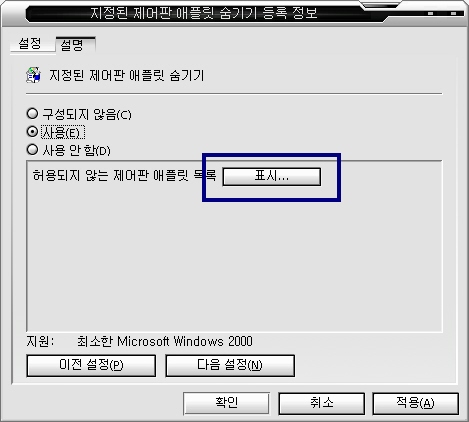
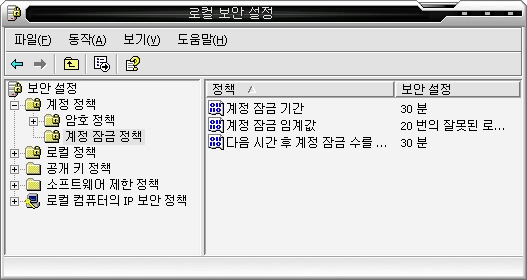
인터넷에서 자료 전달의 핵심 - TCP/IP
순서
1. 들어가기 전에
2. Network 과 프로토콜
3. TCP/IP
1 절 TCP/IP의 옅은 곳 (기본 개념)
2 절 TCP/IP의 깊은 곳 (A,B,C,D, 그리고 E 클래스, 서브넷, 라우팅)
4. OSI 7 Layer와 TCP/IP 비교
5. TCP/IP 응용 예 (DHCP, IP Masquerade)
6. TCP/IP 를 만든 돌대가리들
7. TCP/IP 환경 설정 실습
8. 용어정리
1. 들어가기 전에
TCP/IP는 네트웍의 핵심이라 불리울 만큼 중요한 것이며 그 명성만큼 다양하게 응용이 되고 있다. 그렇다고 여러분이 이 개념을 속속들히 알아야 하는 것은 아니다.
다만, 본인은 여러분이 이 글을 읽어 나갈 때 적어도 그 개념을 파악하기를 바랄뿐이다.
될 수 있으면 TCP/IP에 관한 많은 내용을 포함하며 동시에 글의 양을 최대한 줄이려고 내용의 표현을 간결하게 하려고 노력했다.
이 글에 대한 모든 문의는 사절하며 저작권에 나와 있듯이 이 글을 인용하거나 작성자의 이름을 바꾸어 배포해도 신경쓰지 않겠다.
2, 3, 4, 5, 그리고 6 장에서는 TCP/IP의 기본적인 원리를 다루며 7 장에서는 여러분의 컴퓨터를 인터넷에 접속시키기 위해 직접 TCP/IP 환경 설정 실습을 해 볼 것이다.
2. Network 과 프로토콜
Network 라 하면 두 대 이상의 컴퓨터가 서로 연결되어 자료를 주고 받을 수 있는 상태를 가르킨다. 단순한 개념이므로 이해하는 데 무리가 없을 것입니다.
프로토콜이라 하면 데이터를 주고 받을 때, 어떤 형식으로 데이터를 주고 받을 것이가를
결정한다. 프로토콜에 관한 개념은 약간 어려울지 모르겠으나 이부분을 반드시 익혀야 하겠다. 어떤 이는 프로토콜에 대해서 이런식으로 이야기를 했다.
“프로토콜은 어떤 문제를 풀기위한 해결책이다.”
본인이 생각하기에 이 말은 상당히 애매한 것 같지만 정곡을 찌르는 면이 있기도하다. 프로토콜은 네트웍상(두 대 이상이 어떤 형태로든 연결이 되어 있는 상태)에서 컴퓨터들 간의 자료를 전달할 때 어떤 식으로 자료를 전달해야하는 지 그 해결책을 제시한다는 점에서 볼 때 위의 말은 상당히 설득력이 있다.
프로토콜의 예를 한 번 들어 볼까 한다.
한 2년 된 것 같다. 본인이 심심해서 프로토콜을 만들어 본적이 있었다. (프로토콜이라 불리기에는 너무 초라하지만…) 그 프로토콜은 본인의 이름의 첫자를 딴 JHSP 였다. 이 프로토콜이 하는 일은 아주 간단했다. 우선 서버가 하나 돌아 가고 있고 클라이언트가 그 서버에 접속을 하면 먼저 서버는 “무엇을 원하는가?”라는 메시지를 클라이언트에게 보낸다. 그러면 클라이언트는 자기가 원하는 신호(숫자 1)를 서버에게 보낸다. 그러면 서버는 그 신호(숫자 1)에 해당하는 내용을 클라이언트에게 보내준다.
실제 JHSP 프로토콜이 하는 일은 이것이 다였다. 아주 간단한 프로토콜이지만 프로토콜에 대한 설명을 하고자 할 때 아주 알맞은 예라고 할 수 있겠다.
두 컴퓨터들 간에 서로 어떠한 데이터를 원하는 지 알아보기 위해 신호를 주고 받는 데 위에서는 서버가 먼저 무엇을 원하는 지 물어 보고 클라이언트가 자기가 원하는 것은 1에 해당하는 데이터라고 말해주니 그에 대한 데이터를 서버가 클라이언트에게 보내 주었다.
만약 프로토콜이라는 게 없다고 가정하면, 데이터가 엄청나게 많이 있는 데 아무런 약속도 없이 클라이언트가 접속만 하면 서버가 데이터를 무작위로 보내 버린다면 어떻게 되겠는가? 물론, 안된다.
프로토콜이 무엇인지 대충 개념은 잡았을 것이다.
본인 나름대로 프로토콜에 대한 정의를 한번 내려 보았는 데 다음과 같다.
“프로토콜은 올바른 데이터의 전달을 위해 사용하는 신호이다.”
사실 위 말은 많은 사람들이 이미 알고 있는 프로토콜에 대한 평범한 정의를 약간 고친 것 뿐이다. 프로토콜을 신호라는 말 대신에 컴퓨터들 끼리 사용하는 언어라고 하기도 한다.
즉, 컴퓨터들이 데이터를 주고 받기 위해 서로에게 의사 소통을 해결하는 도구가 프로토콜이라는 것인데 인간의 언어에 해당 된다고 볼 수 있다.
지금까지 설명한 내용을 모두 이해를 했다면 여러분은 벌써 이 방면(?)에 관해서 상당한 지식을 가졌다고 할 수 있다.
만약 여러분이 평범한 인터넷 사용자인데 TCP/IP라는 말을 귀가 따갑게 들어서 도대체 그게 무엇인지 궁금해서 이 글을 읽고 있다면 이 쯤에서 그만두라는 말을 조심스럽게 해 본다. 왜냐 하면 여러분들은 이미 프로토콜에 대해서 완벽하게 알고 있으며 더 이상 알아봐야 평범한 네티즌에게는 아무런 도움이 되질 않기 때문이다.
TCP/IP도 이름만 다를 뿐이지 위에서 설명한 프로토콜의 범위를 벗어나지 않는다. 아니 벗어날 수 없다. 만약 위의 개념을 벗어나는 프로토콜이 있다면 그것은 이미 프로토콜이 아니다. 왜냐하면 위의 개념을 가진 신호 체계를 프로토콜이라 부른다고 정해 놓았기 때문이다.
그럼 TCP/IP가 정말 위에서 설명한 프로토콜과 이름만 다를 뿐인가? 그 말은 솔직히 조금 과장되었다. 실제 대부분의 프로토콜은 위에서 설명한 JHSP 프로토콜처럼 단순한게 아니라 이 와는 비교 하지도 못할 만큼 상당히 복잡하게 설계되어있다. 그도 그럴 것이 하나의 프로토콜로 온갖가지 데이터들(텍스트, 비디오, 오디오 등)은 주고 받고, 뿐만아니라 상황에 맞게 적절하게 가공까지 해서 데이터를 전달해야 하기 때문에 그 덩치가 엄청나게 불어난 것이다. 하지만 이미 언급했듯이 그 근본적인 개념은 모두 동일하다.
3. TCP/IP
1 절 TCP/IP의 옅은 곳 (기본개념)
위에서도 설명했듯이 통신을 할 때는 규칙이 있다. 이것은 인터넷 통신을 할 때도 그대로 적용이 된다.
인터넷(Internet)이란 간단하게 말해서 모든 나라 통신망이 하나로 결합된 세계 최대의 네트웍을 말한다.
이것은 International Network의 약자로 그 뜻에서 알 수 있듯이 국가와 국가 사이의 네트웍을 일컫는 말이다. 그러므로 Internet 은 세상에 하나 뿐이며 영문법으로 따진다면 고유명사가 되고 항상 대문자로 시작한다. 만약 ‘Internet’에서 첫자 I가 소문자로 시작한다면 그 뜻은 완전히 달라진다. 영문법에서 단어의 첫자가 소문자로 시작한다면 고유명사가 아니라 보통명사가 되는 용법 자체에서도 다르게 된다. 고유명사가 아니면? 고유하지 않고 여러 개가 존재한다는 말인데 조금 전에는 세상에서 하나 뿐이라 해놓고 이제와서 무슨말인가? 글쎄, 우리말로 표현 하자면 '아' 다르고 '어' 다르다는 식의 표현이라 하겠다. 만약 'Internet'이 'internet'처럼 소문자로 시작한다면 그 뜻에는 분명 차이가 있다.
그럼 소문자로 시작하는 internet은 무엇인가? Internet은 International Network의 약자라는 것을 알고 있다. 하지만 소문자로 시작하는 internet은 inter-‘ 라는 접두어와 ‘network’이라는 단어가 만나서 생성된 것으로 그 뜻은 네특웍와 네트웍을 사이를 가리키는 소규모의 네트웍을 말한다. 즉 여러분은 전세계를 하나로 묶는 거대한 네트웍인 인터넷을 칭할 때는 항상 대문자 시작하는 Internet이라는 단어를 사용해야한다.
인터넷의 유래가 어떠니하는 고리타분한 이야기는 안할려고 했는 데 일단 시작했으니 그 개괄 정도만 짚어 보겠다.
인터넷은 1970년대 초 DARPA(Department Of Defence Advanced Research Project Agency)에서 시작된 실험 프로젝트인 ARPANET의 부산물이다. 원래는 국방성 관련일을 행하는 기관이나 대학에서 사용으나 이후 그 규모가 커짐에 따라 네트워크 관리
프로토콜(NCP)을 전송관리 프로토콜/인터넷 프로토콜(TCP/IP)로 바꾸고 이름도 인터넷이라 정하였다. 인터넷은 개방성이라는 특성으로 인해 빠른 정보 교류가 이루어져 인터넷의 내적, 외적으로 많은 기술의 발전을 가져왔으며 그에 따라 인터넷 자체가 점점 거대해져 지금에까지 이르렀다.
인터넷을 통하여 다른 컴퓨터에 접속 (텔넷, FTP)하여 작업을 할 수 있고 편지를 보내거나 외국에 있는 상대방의 얼굴을 직접 보면서 대화를 할 수가 있다. 뿐만 아니라 게임이나 쇼핑 등도 할 수 있으며 그 이용가치는 헤아릴 수 없다고 해야할 것이다.
초기 단계에 TCP/IP는 유닉스 계열에서 만 사용이 되었는 데 그 효율성으로 인해 요즘에는 거의 모든 운영체제에서 사용된다.
그럼 이제 TCP/IP에 대해서 알아 보자.
TCP/IP의 기능 : 컴퓨터들 사이에 데이터를 전달하기 위해 데이터를 패킷으로 잘라 목적지로 전달한 뒤 그 패킷을 다시 원래대로 복구한다.
TCP : 데이터를 패킷으로 자르고 다시 합치는 일을 맡음
IP : TCP에 의해 잘려진 패킷을 목적지로 전송
간단하게 설명하면, 정보를 효율적으로 전달하자는 데 목적이 있다.
좀 길게 설명하면, TCP가 데이터를 옮기기에 적당한 크기로 나누고 그 데이터를 IP에게
맡기면 IP는 그 데이터가 전송되어야할 목적지까지 옮긴다. 이 때 IP는 데이터의 전송만
담당할 뿐 그 데이터가 죽이되든 떡이되는 신경쓰지 않는데 TCP가 그 데이터 관리를 맡는다.
TCP에 의해 나누어진 데이터들이 IP에 의해 다 전달이 되면 다시 TCP가 원래의 데이터
모습을 갖추도록 재 구성한다.
인터넷에 접속되는 모든 컴퓨터들은 고유한 IP 번호를 같는다. (꼭 그런 것은 아님) 이것은 마치 여러분의 집 주소와 같아서 편지를 쓸 때 편지 봉토에 집 주소만 쓰면 그 편지가 어디든지 전달되는 원리와 같다.
좀 다르게 설명해 볼까?
서로 자기 나라 말 밖에 모르는 한국 사람과 일본 사람을 서로 맞대 놓고 대화를 하라면
제대로 될까? 바디 랭귀지로? 쉽지 않을 것이다. 만약 이 두사람이 세계 제일의 공통어인
영어를 알고 있다면 문제는 쉽게 풀어진다.
컴퓨터 세계도 이와 마찬가지라서 윈도우와 유닉스를 연결해 놓고 서로 데이터를
주고 받으라고 명령한다면 윈도우는 윈도우에서 쓰는 말 밖에 모르고 유닉스는
유닉스에서 쓰는 말 밖에 모를텐데 당연히 데이터를 올바로 주고 받을 수 없을 것이다.
이 때 컴퓨터 세계에도 인간의 세계에서와 같이 공통어가 있다면 제대로 통신을 할 수
있을 것이다.
컴퓨터 세계에서 그 공통어가 바로 TCP/IP인 것이다.
TCP/IP는 인터넷에서 컴퓨터들사이에 데이터 전송을 위한 표준 프로토콜(언어)이며 기본
적으로 4개의 층으로 이루어져 있다.
TCP/IP는 TCP와 IP가 합쳐진 것인데 이를 따로 떼어서 설명을 해 보면 IP는 실제로
데이터를 전달하며, TCP 데이터를 패킷으로 자르고, 붙이고 또 전달 되는 데이터를 관리한다. 즉, IP는 데이터가 전달될 정확한 위치를 정하고, TCP는 전달되는 데이터가 혹시 상하지 않나 하고 검사를 한다.
IP의 특징이라하면 비신뢰성과 비연결성이라 할 수 있다.
비 신뢰성이란 IP는 오로지 데이터를 전달하는데 만 신경을 쓴다는 것이며 전달되는
데이터가 죽이되든 떡이되든 상관하지 않는다는 것을 말한다. 이 때문에 TCP와 연동을 해
데이터가 올바로 전송되었는 지 검사하는 것이 필요한 것이다.
비 연결성이란 예를 들어 사용자의 웹 브라우저가 서버에 접속해서 데이터를 가져온 뒤 접속을 끊는 것을 말한다. 즉 하나의 웹 페이지에 그림이 두 개 있다면 HTML 파일을 가져오기 위해서
접속을 한 번하고 각 각의 이미지를 가져 오는 데 접속을 따로 따로 해야 한다는 이야기가
된다. 이러한 점은 서버에서는 접속을 바로 바로 끊으니 부하가 걸리지 않으므로 장점이
되나 사용자 입장에서는 매번 접속을 해야하니 시간이 걸린다는 단점이 된다.
(물론 이것은 옛날 얘기이다. 요즘 사용되는 최신 버전의 HTTP 에서는 기본적으로 한번의 접속으로 모든 데이터를 보낼 수 있도록 지원한다.)
TCP는 메일이나 HTML등의 모든 데이터를 이동시킬 때 패킷 단위로 잘라서 보내는 역할을 하는 데, 보내는 패킷 내부에는 현재 패킷의 출발 지점, 목적 지점, 패킷의 순번, 크기 등을 적어 체크섬에 저장해 넣는다. 그리고 이 패킷을 받는 쪽에서는 실제 받은 패킷의 크기 등을 그 패킷 내부에 있는 체크 섬과 비교해 값이 맞지않거나 일정한 시간이 경과했는데도 응답이 없을 경우에는 잘못된 패킷으로 간주해 즉각 새로운 패킷을 보낼 것을 요구한다.
데이터를 보내면 상대편 컴퓨터는 모든 패킷이 전송될 때 까지 기다린다. 패킷을 받을
때 마다 체크섬을 검사해 이상이 있으면 데이터를 다시 전송받는다. 데이터가 모두 전송되었으면 데이터를 보내기 전의 상태와 같게 하기 위해 패킷의 순번대로 재 결합을 한다.
(네트웍에서 데이터를 전달할 때 사용되는 단위에는 여러가지가 있는 데 대부분 패킷(packets)이라고 부른다.)
TCP/IP 패킷 처리방법에 대한 자세한 설명은 뒤에 다시 설명하도록 하고 우선 TCP/IP를 각 계층별로 나누어 설명해 보겠다.
(괄호안에는 각 계층에서 정의되는 프로토콜)
애플리케이션 층
아래 층(트래스 포트 층)이 데이터를 송신할 수 있도록 데이터 포멧을 한다. | 트랜스포트 층 (TCP/UDP)
세션의 초기화, 에러 제어, 패킷(세그먼트)으로 나누고 각 각에 헤더를 붙임.
헤더는 수신한 곳에서 데이터가 전송되는 동안 변경되지 않았음을 확인하고,
세그먼트가 원래의 형태로 재 결합하기 위해 사용되는 정보를 포함한다.
(데이터를 전송 할 때와 수신한 뒤의 오류를 체크) | 네트워크 (인터넷) 층 (IP)
데이터를 IP 데이터 그램에 넣고 데이터그램에 적절한 인터넷 주소를 부여하여
전송할 데이터를 준비한다. | 데이터 링크 층
이더넷과 FDDI등의 전송 매체의 접근 방법을 포함해, 네트워크 사이의
데이터 전송의 순서를 기술한다.
물리적인 전송 매체에 관련, 논리적인 데이터를 물리적인 데이터로 변환
|
메일 프로그램등이 데이터를 보내면 TCP가 데이터를 송신할 수 있도록 TCP가 이해할 수 있는 형태로 포멧한다. TCP는 그 데이터를 패킷 형태로 자르고 에러 체킹을 위한 헤더를 각 패킷에 붙인다. 네트워크 층에는 IP 포장(목적지 IP의 주소를 가르켜 줌)을 하고 IP헤더를 넣는다. 데이터 링크층은 네트워크 층에서 보내온 데이터의 IP 주소를 특정한 네트워크의 하드웨어 주소로 번역한다.
예를 다시 들면, HTTP 서버가 0 과 1 로만 되어 있는 자료를 애플리케이션 층에 보낸다.
그러면 애플리케이션 층에서는 그 데이터를 새로운 형태로 포멧 (디지털을 아날로그) 트랜스포트 층에 보낸다. 트랜스포트 층에서는 TCP가 데이터를 전달하기 쉬운 형태로 자르고 난 뒤 네트워크 층으로 데이터를 보낸다. 네트워크층에서는 데이터가 가야할 장소와 IP 헤더를 붙이고 데이터를 데이터 링크층으로 보낸다. 데이터 링크층은 네트워크 층에서 보내온 데이터의 IP 주소를 특정한 네트워크의 하드웨어 주소로 번역한다.
송신측에서 각 계층은 상위 계층에서 받은 데이터의 헤더를 추가하고, 유사하게 수신측에서 각 계층은 다음 상위 계층에 데이터를 보내기 전에 자신의 헤더를 추출한다. 그래서 최종적으로 얻게되는 데이터는 원래 보냈던 데이터와 동일한 것이 된다.
TCP는 전달 되는 데이터의 관리 기능외에 또 다른 기능이 있다. 그것은 TCP가 다른
프로토콜과 같이 사용될 수 있도록 지원한다. 예를 들어 여러분이 집에서 모뎀으로
인터넷에 WWW을 항해 하려 한다면 먼저 윈속등으로 여러분 컴퓨터에 TCP/IP 환경을
만들어야 한다. WWW에서는 브라우저와 서버와 통신을 위해 HTTP라는 프로토콜을 따로
사용하는 데 왜 TCP/IP라는 프로토콜을 따로 컴퓨터에 설정 해 주어야 하는가? 이미
언급했다시피 인터넷에는 많은 종류의 컴퓨터(OS)가 존재한다. 이들 간을 묶는 첫 번째
프로토콜(언어)이 TCP/IP이고 인터넷을 기반으로 움직인는 WWW에서 정보를
교환하기 위한 프로토콜이 HTTP인것이다.
인터넷 상의 모든 컴퓨터는 주소를 가지고 있다. 이 주소는 IP라고 불리는 데 32bit로
이루어 졌으며 8비트 씩 나누어 네 부분으로 구분하며 각 각은 255이하의 값을 가진다.
예를 들면 IP는 203.237.229.161과 같이 표현된다. 인터넷 사용자가 브라우저를
이용해 웹 사이트를 방문할 때는 URL 입력창에 crt.ml.org와 같은 문자열을
입력하는 데 사실 모든 컴퓨터들은 오직 IP 주소로만 구분이 된다.
그렇기 때문에 위의 crt.ml.org 라는 URL을 숫자로 된 IP로 바꾸어 주는 과정이
반드시 필요한 데 이것은 네임서버(DNS)라고 하는 컴퓨터가 문자로 된
URL을 숫자로 된 적절한 IP로 바꾸어준다. 사용자가 속해있는 로컬 DNS에서 IP주소를
찾지못하면 상위 DNS 서버에서 해당 URL에 맞는 IP주소를 얻어온다. 그러면 사용자의
웹 브라우저는 그 IP주소를 가지고 실제 웹 사이트를 찾아간다.
이상 까지의 내용만이라도 알고 있으면 일반 사용자로서, 또한 네트웍 프로그래머로서
충분하다고 생각이된다. 네트웍 프로그래밍을 할 때 TCP나 UDP에 관해서 프로그래밍을
한더라도 그 내부의 동작원리는 모두 감추어져 있기 때문에 굳이 더 이상 알 필요가
없다고 생각된다.
그러나 네트웍 관리해 보겠다면 이 글의 내용 전체를 자세히 해부해 주었으면한다.
이 아래의 내용 부터는 위에서 언급한 내용에서 빠진 부분을 좀 더 깊이 공부를 해 보겠다.
2절 TCP/IP의 깊은 곳 (A,B,C,D, 그리고 E 클래스, 서브넷, 라우팅)
IP에 대해서 좀 더 깊이 있게 알아보자.
위에서는 IP를 여러분의 집주소에 비교를 했다. 여러분들의 집 주소는 다른 사람들이 볼 때 알아 보기 쉽게 적혀 있다.
예를 들면, "서울시 용산구 한남 1 동 297/2 번지" 와 같이 되어 있으면 이 주소가 대충 어디 쯤인지 쉽게 알 수 있다. 이와 비슷하게 컴퓨터 주소 엮시 다른 컴퓨터가 보면 알아 보기 쉽게 되어 있는 데 0 과 1로 이루어진 32비트 숫자로 되어있다.
이러한 32 비트로 이루어진 주소를 컴퓨터의 고유 주소를 IP라 부르는 데 사람이 알아보기에는 쉽지가 않다.
그래서 사람들은 꽤(?)를 내어 32비트를 4 부분으로 나눠 각 부분을 10진수로 표기해 사용한다.
에를 들면 11000011 10110111 10100111 01000101을 네 부분으로 나눈 뒤 203.237.229.162와 같이 십진수로 나타내어 사용한다. 아무래서 위의 2 진수 보다는 외우기가 훨씬 편하다.
IP 주소는 분류와 관리상 편리하게 몇 개의 클래스로 나누어져 있는 데 표를 이용해 나타내어 보았다.
클래스 네트웍 구분자 네트웍 주소 사용가능한 IP 주소 용도
| A | 0 | 1111111 | 11111111 11111111 11111111 |
| | B | 10 | 111111 11111111 | 11111111 11111111 |
| | C | 110 | 11111 11111111 11111111 | 11111111 |
| | D | 1110 |
| Multicast | | E | 11110 |
| 실험용/연구용 |
위 표를 보고 한 눈에 이해하기가 힘드리라 생각한다.
IP에는 분류 구분을 위해 처음 부분의 일련된 비트를 둔다. 먼저 어떤 IP가 0으로 시작하면 A 클래스라는 것을 위 표에서 알 수가 있다. 이 것은 2 번 째 비트부터 8 번째 비트 까지가 네트웍 주소가 되며 반대로 사용가능 한 IP 주소(이하, 호스트 수)는 24비트가 된다. 즉, A 클래스로 나누어 지는 네트웍크 수는 2의 7승인 128개가 되며 호스트의 수는 2의 24승으로 16,777,216 개가 된다.
IP 주소가 0으로 시작한다는 말은 0000 0011 11111101 00000011 0000 0111 와 같은 IP 주소가 그 한 예라고 할 수 있는 데 이를 네부분으로 나눠 십진 수로 표시해 본다면 3.253.3.7과 같다. 본인이 여기서 말하고자 하는 의도는 8 비트 중 그 첫 비트가 0으로 시작한다면 그 첫 부분의 최소 값은 0이며 최 대 값은 127 이라는 것이다. IP의 주소가 0 부터 127 사이의 값으로 시작이 된다면 그것은 틀림 없이 A클래스라는 말이된다.
IP 주소가 10으로 시작하면 B 클래스임을 나타내며 3 번째 비트부터 16번째 비트가 네트웍 주소를 가리키며 나머지 17번째 비트부터 32 비트 까지가 호스트 주소임을 나타낸다. 8비트 중 두 비트가 10으로 시작하면 최소 128의 값을 가지며 최대 191의 값을 가진다. 즉, 십진수로 표기한 IP 의 네 부분 중 그 첫부분이 128에서 191의 값을 가진다면 그 IP주소는 틀림없이 B 클래스에 속해 있다.
C 클래스의 경우는 110으로 시작하며 4 번째 비트부터 24 번째 비트까지(즉, 2의 20승이므로 2,097,152개의 네트웍 주소가 C 클래스로 나타내어 질 수 있다)가 네트웍 주소가 되고 나머지 25비트부터 32비트 까지가 호스트 주소가 된다. C 클래스 하나에 나타낼 수 있는 호스트 수는 256개로수 비교적 작다.
C 클래스의 IP 주소의 첫 부분은 십진수 192부터 223의 값을 가진다.
현재 네트웍상에서 많이 쓰이는 IP 클래스는 A,B, 그리고 C 이다. D 클래스나 E 클래스는 특별한 용도로 쓰이는 데 그 사용빈도 수가 아주 드물다.
서브 넷팅
IP를 분류별로 나눈 것의 제일 큰 목적은 뭐니 뭐니해도 그 관리의 편성성 때문이라 하겠다. 예를 들어 203.237.229 라는 C 네트워크 클래스 IP를 하나 할당 받았다면 우리는 이론상 256개의 호스트를 사용할 수 있다. 하지만 이 IP 주소를 가지는 256대의 컴퓨터가 모두 한 건물내에 있지 않고 여러 건물에 흩어져 있다면 여러분은 이 C 네트웍 클래스를 또 다른 서브 네트웍으로 분류하기를 원할 것이다. 만얀 여러분이 할당받은 203.237.229 네트웍 클래스를 다시 두 개의 서브 네트웍으로 나눈다고 가정을 한다면 어떻게 네트웍을 설정해야 하는 지 살펴보자.
우리는 하나의 C 네트워크 클래스가 256개의 IP를 가진다는 것을 알고 있다.
이 것을 두 개로 분류하면 0~127 까지를 하나의 분류로 하고 나머지 128~125 까지를 또 다른 하나의 네트웍으로 분류할 수 있다.
C 네트웍 클래스에서는 32비트의 IP중 24 비트가 네트웍 주소이고 8비트가 호스트 주소인데 이 8비트를 다시 두 개로 나었으니 그 8 비트 중 첫 번째 비트를 네트웍 구분자로 두어 0으로 시작하면 203.237.229 C 네트웍 클래스의 첫 번째 네트웍이라 가정하고 1로 시작하면 203.237.229. C 네트웍 클래스의 두 번째 네트웍이라고 할 수 있다. 이 때 첫 번째 네트웍의 네트웍 주소는 203.237.229.0이 되고 두 번째 네트웍 클래스의 네트웍 주소는 203.237.229.128이 된다.
이 두 네트웍의 구분을 위해서 넷 마스크는 203.237.229.128을 사용하면 된다.
서브 넷팅에 대해서는 이상으로 짧게 끝마치겠다.
보다 자세한 사항은 이 글의 7장 TCP/IP 환경 설정 실습에서 서브 넷팅에서 길 찾는 방법 등을 참고하기 바란다.
윈속(winsock)은 개인용 PC와 인터넷을 이어주는 매개체 역활을 한다. 윈속을 구동하면 TCP/IP 환경이 개인 PC에 마련되며 이를 통해 인터넷 애플리케이션들이 데이터를 송수신할 수 있다.
4. OSI 7 Layer와 TCP/IP의 비교
우리는 TCP/IP에 관해서 3장에서 자세히 공부를 했다.
그럼 여기서 OSI 7 Layer 에대해 한 번 알아보고 이게 TCP/IP랑 무슨연관이 있는지도 알아보자. (사실, 별 상관이 없지만 OSI 7 Layer는 표준적인 모델이라 거의 모든 네트워크 프로토콜을 구현을 설명할 때 비교되어 설명된다.)
그리고 미리 한가지 말해 둘 것은 이 절은 OSI 7 Layer와 TCP/IP의 비교를 위한 장으로 OSI 7 Layer에 대해서는 자세히 언급하지 않겠다. 여러분들 중 네트웍 프로토콜을 직접 만들거나 혹은 다른 네트웍 프로토콜을 분석해야 할 입장에 있는 사람이 있다면 OSI 7 Layer에 대한 관련내용을 다른 서적에서 참고해야 할 것이다.
OSI 7 Layer에 대해서 설명하기 이전에 먼저 OSI 7 Layer와 TCP/IP를 가지고 비교 설명을 한 번 해 보겠다.
OSI 7 계층과 TCP/IP 비교 설명
1. 7 계층 vs 4 계층
2. 모델(방식, 형식) vs 2개가 하나로 이루어진 프로토콜
3. 나중에 나옴 vs 먼저나옴 (OSI 7 계층의 모든 역활을 해 냄),
위에서 3 번째 비교 내용을 보면 TCP/IP가 OSI 7 Layer 보다 먼저 나왔다는 것을 알 수가 있다. 이는 TCP/IP 프로토콜이 만들어 질 당시 OSI 7 Layer통신 프로토콜 표준 모델이라는 것이 없었기 때문에 당연히 TCP/IP 프로토콜은 OSI 7 Layer의 모델과는 일치할 수 없다.
특히, TCP/IP가 OSI 7 Layer 와 달리 4 계층으로 이루져 있다는 것만 보더라도 알 수가 있다. 하지만 TCP/IP 프로토콜 구조가 비록 4 계층으로 이루어져 있지만 OSI 7 Layer가 가지고 있는 각 층 모든 기능을 다 수행한다.
[표 4-1] OSI 7 Layer와 TCP/IP의 계층별 차이점
응용계층
응용 프로그램이 네트워크에 연결되는 방법과 서비스를 기술 | 응용 계층
TCP/IP 네트워크 데몬과 응용 프로그램이 OSI 의 일부 계층과 세션 계층의 일부 업무를 수행한다.
| 프리젠테이션 계층
응용 프로그램에 대한 데이터 표현의 기술 | 세션 계층
네트워크 연결의 생성, 관리, 소멸 | 트랜스포트 계층
세션의 초기화, 에러 제어, 순서 검사를 포함한, 데이터 경로와 전달을 관리한다. | 트랜스포트 계층
데이터에 대한 에러와 순서 검사
| 네트워크(인터넷) 계층
데이터의 주소, 전송, 패킷의 분할과 복구를 한다. | 네트워크 계층
테이터의 주소와 경로의 통신 흐름제어 | 데이터 링크 계층
물리층에 대한 접근 방법 기술 | 물리 계층
이더넷과 FDDI등의 전송 매체의 접근 방법을 포함해, 네트워크 사이의 데이터 전송의 순서를 기술한다. | 물리 계층
물리적 전송 매체와 순차적 운영 특성 기술 |
위에는 OSI 7 Layer와 TCP/IP의 구조를 계층별로 나타내어 설명을 하였다.
위 표의 내용과 중복이 되는 내용이겠지만 메일을 보낼 때 OSI 7 Layer와 TCP/IP가 작동하는 방식을 가지고 표로 나타내어 다시 설명을 해 보겠다.
[표 4-2] 메일 메시지 전송시 OSI 7 Layer와 TCP/IP의 작동 방식 비교
| OSI 7 Layer | 하드웨어 | TCP/IP | 메일 메시지 전달 과정 |
| 1 | 애플리케이션 |
게이터웨이 |
애플리케이션 | 패킷으로 분할, MUA가 주소 검사 -> 다른 네트웍 주소이면 라우터를 통해 네트워크 메일 전송 대리자 에게 전달. 라우터는 메시지가 전송 될 곳을 결정한뒤 메시지를 보냄 | | 2 | 프리젠테이션 | | 3 | 세 션 | | 전 송 | | 4 | 전 송 |
| 전송을 위한 준비(오류 체킹 등) |
네트워크 |
라 우 터 | | 5 | 네트워크/인터넷 |
| | 6 | 데이터-링크 | 라 우 터 |
물 리 층 | 브 리 지 | | 7 | 물리적 | 중 계 기 | 중 계 기 |
라우터 : 모든 데이터가 가장 효율적인 경로를 통해 전송될 수 있도록 통로를 결정한다.
브릿지 (네트워크 연결) : 목적지가 같은 네트워크에 있으면 브릿지는 패킷을 무시한다.
브릿지는 다른 네트워크로 갈 필요가 있는 패킷을 통과시킨다.
브릿지는 OSI 7 Layer의 데이터 - 링크의 매체 접속 제어 (Media-Access Control : MAC) 세션에서 작동한다.
혹시 여러분 중 메일 서버나 클라이언트에 대해서 관심이 있으신 분은 본인이 강좌를 써 놓은 것이 있으니 참고하기 바란다.[링크 걸어 놓을 것]
표 4-1 에 대해서는 별도로 설명을 하지 않아도 무엇을 뜻하는 지 알 수 있으리라 생각하고 설명하지 않겠으며 표 4-2에 대해서만 짧게 언급하겠다.
인터넷에서 메일이 가는 과정을 OSI 7 Layer와 TCP/IP를 통해 표를 그려 보았는 데 실제 이 부분을 이해하기 위해서는 먼저 상기해야 할 것이 하나 있다.
여러분도 지금 쯤이면 인터넷 상에서 움직이는 모든 데이터는 TCP/IP라는 프로토콜의 의해 데이터가 움직여 진다는 것을 알 고 있을 것이다. 이 글을 통해 벌써 몇번이나 강조를 해 왔다.
다시 말하면 OSI 7 Layer 에서 제안하는 구조와 TCP/IP프로토콜의 구조가 같지 않기 때문에 TCP/IP 프로토콜에 의해 조작되는 데이터를 억지로 OSI 7 Layer 모델에 끼워 맞출 수는 없다는 것을 말하며 단지 여러분의 이해를 돕기 위해 표를 그려 설명해 놓은 것 뿐이라는 것을 알아주기 바란다.
메일 메시지를 포함한 모든 인터넷 상의 데이터는 TCP/IP 프로토콜이 전달한다고 얘기를 했는 데 위에서는 라우터가 TCP/IP프로토콜의 업무인 주소를 파악하고 데이터를 전달하는 것 처럼 설명을 했다.
정확하게 못을 박자면, TCP/IP 프로토콜이 데이터가 가야할 위치나 데이터를 보내기 위해 가공하고 직접 전달하는 일을 맡는다. 여기서 설명하는 관점은 TCP/IP 프로토콜의 차원에서 그 내용을 세세히 살피며 기술하는 것이 아니라 그 보다 한 단계 높은 개념적인 차원에서 설명하는 것이므로 TCP/IP 프로토콜이라는 말 대신에 그 역할을 대신하는 라우터라는 이름을 썼다.
OSI 7 Layer는 Open System Interconnection(개방형 시스템 상호접속) 7 Layer 의 약자로서 ISO(International Standards Organization: 국제 표준기구)에서 표준으로 제정하였다.
우선 하위 계층부터 나열해 보면 물리적(또는 데이터 전송) 층(Physical Layer), 데이터-링크 층(Data Link Layer), 네트워크(또는 인터넷) 층(Network Layer), 전송 층(Transport Layer), 세션 층(Session Layer), 프리젠테이션 층(Presentation Layer), 그리고 마지막으로 애플리케이션 층(Application Layer)으로 나누어져 있다.
좀 긴것 같다. 이제 하나 하나의 층이 무슨 일을 하는 지 대충만 알아보자.
맨 하위 층 부터 설명하자면 이 글을 읽는 여러분 보다 글을 쓰고 있는 본인이 재미없어 지칠 것 같다. 그래서 실생활(?)에 조금이나 나마 관련이 있는 맨 위 층 부터 설명을 하겠다.
Application Layer : OSI 7 Layer 중 최 상위 계층에 속한다. 애플리케이션이라고 해서 워드패드와 같은 특정 프로그램을 가르키는 것이 아니라 네트웍 프로그램이 외부와 통신을 하게 될 때 직접적으로 이 계층과 접촉을 하게 된다. 즉 이 계층은 네트웍 애플리케이션의 인터페이스가 된다고 말 할 수 있다. 이 계층을 사용하는 주요 애플리케이션은 여러분이 하루도 빠지지 않고 매일 밤 낮으로 사용하는 웹 브라우저, 메일 프로그램, 텔넷(이야기, 데이터 맨 프로 등) 프로그램등이 여기에 속한다.
Presentation Layer : 표현 계층은 응용 프로그램의 문자 표현(명령어의 상이함)과 관련하여 하나의 일관된 표현을 관리한다. 예를 들면 그래픽 웹 브라우저에 속하는 IE 나 NC의 경우 이미지를 자연스럽게 나타내는 데 텍스트 기반의 웹 브라우저인 lynx는 이미지를 화면에 나타낼 수가 없는 데 이와 같은 처리를 이 계층에서 한다고 생각하면 된다.
Session Layer : 네트워크 접속 유지, 오류 복구등을 한다.
Transport Layer : 이 계층의 명칭이 말하는 것 처럼 데이터를 전송하는 데 필요한 업무를 맡는다. 데이터를 수용할 수 있는 패킷 크기로 분할 하며 패킷 분할 에서 데이터를 완전 무결하게 보존한다. 분할과 재 구성 , 오류복구, 흐름제어 등을 포함하여 이 증에서 구현할 수 있는 몇 단계의 서비스가 있다.
Network Layer : IP 포장은 네트워크나 인터넷 패킷에 붙여진다. 헤더는 소스와 목적지 주소, 연속된 순서, 올바른 라우팅과 목적지에서의 재구성을 위해 필요한 다른 데이터를 포함한다.
Data Link Layer : 데이터 - 링크 층은 예를 들어 , PPP (Pointer-to-Pointer) 되기 위해 패킷을 맞춘다.
Physical Layer : 이더넷과 토큰링은 가장 일반적인 물리적인 층 프로토콜이다.
우리는 네트웍 애플리케이션이 OSI 7 Layer를 통해 데이터를 내보낸다는 가정을 하고 실제 어떤 어떤 단계를 거치면서 어떤식으로 데이터를 보내는 지 한 번 따져보아야할 필요성을 느낀다. 그렇지 않고는 위 처럼 산만하게 계층별로 설명해 놓은 글을 이해하기가 힘들기 때문이다. 위에서 메일 데이터를 보내는 예를 들었으니 참조하기 바라고 여기서는 짧게 정리해 보겠다.
일단 데이터를 보내기 위해서는 네트웍 애플리케이션을 실행 시켜야한다. 데이터를 보내면 맨 위층부터 아래층으로 전달 되는 데 각 층에서는 주어진 임무대로 데이터를 가공한다. 그리고는 상대편에게 보내는 데 상대편에서는 그 데이터를 받을 때 보낼 때와는 정 반대로 맨 밑의 계층에게 먼저 데이터가 전달되 데이터가 전달 될 때 데이터를 가공하던 과는 달리 거꾸로 데이터를 원상복귀 시키기 위해 각 층에서는 데이터를 보낼 때와는 정 반대로 데이터를 복구한다.
5. TCP/IP 응용 예
DHCP (동적 IP 할당) IP Masquerade
여기에서는 IP 어드에스가 모자랄 경우 효율적으로 사용할 수 있는 방법을 설명한다.
- DHCP
DHCP (Dynamic Host Configuration Protocol) 은 동적 호스트 설정 규약이다.
DHCP는 IP가 모자라서 동적 IP가 필요한 경우 일반적으로 쓰인다.
(네트웍을 하지 않고 있다면 IP를 돌려 주므로 다른 컴퓨터가 사용할 수 있음)
리눅스에서 DHCP를 설정하는 순서
- /etc/dhcp.conf 파일 설정
- touch /etc/dhcpd.leases
- /sbin/route add -host 255.255.255.255 dev eth0 (/etc/rc.d/rc.local에 추가)
- /etc/rc.d/init.d/dhcpd start
- 윈도우 95에서 DHCP 서버에서 IP 가져우기를 선택하고 호스트 이름만 적어준 뒤 재 부팅
/etc/dhcpd.conf 파일의 예
subnet 203.237.229.0 netmask 255.255.255.0 {
range 203.237.229.164 203.237.229.167; (IP 할당 범위)
default-lease-time 86400; (기본 임대 단위 초, 하루)
max-lease-time 259200;
option subnet-mask 255.255.255.0;
option broadcase-address 203.237.229.255;
option routers 203.237.229.254;
option domain-name-servers 210.114.128.2;
option domain-name "client21.dankook.ac.kr"
}
- IP Masqerade
리눅스에서 제공하는 IP Masqerade를 이용하면 IP Address를 할당받지 못한 컴퓨터에서도 여러가지 네트웍 애플리케이션을 사용할 수 있다.
먼저 다음과 같이 커널 컴파일부터 하자.
enable loadable modulde support (Y)
networking support (Y)
network firewalls (Y)
tcp/ip networking (Y)
ip forwarding/gatewaying (Y)
if firewalling (Y)
ip masquerading (Y)
ip always defragment (Y)
dummy net driver support (Y)
ipautofw masquerade support (Y)
컴파일이 끝났으면
/etc/hosts를 다음과 같이 수정하도록 하자
127.0.0.1 localhost localhost.localdomain
203.237.229.163 client21.dankook.ac.kr client21
192.168.1.1 client21.dankook.ac.kr client21
192.168.1.2 redpig.crt.com redpig
192.168.1.3 user.crt.com user
192.168.1.4 crt.crt.com crt
다음으로 윈도우 세팅을 하면 된다.
TCP/IP에서 할당된 IP 주소를 192.168.1.163로 놓고 서브넷 마스크를 255.255.255.0 으로 둔 다음 게이트 웨이 주소를 리눅스 박스로 (192.168.1.1) 두고 재 부팅한다.
재 부팅한 다음 ping 203.237.229.163을 해 본다. 정상적으로 작동을 하면 리눅스 박스로 접속을 해서 네트웍 애플리케이션을 사용하면 된다.
다시 리눅스 박스로 돌아 와서
# ipfwadm -F -p deny
# ipfwadm -F -a m -S 192.168.1.1/24 -D 0.0.0.0/0
# ipfwadm -F -a m -S 192.168.1.2/24 -D 0.0.0.0/0
와 같이 입력하고 도스 창에서 바로 telnet home.hitel.net 이라고 입력해 본다.
정상적으로 접속이 되면 모든 세팅이 완료 되었다.
6. TCP/IP 를 만든 돌대가리들
사실 TCP/IP에는 문제가 많다. 왜 밀레니엄 버그(Y2K)가 발생했을까? 그 것은 컴퓨터를 만든 사람들이 돌대가리라서 그렇다. 어떻게 컴퓨터를 2000년 까지만 사용하고 그 이후에는 사용하지 않을 것이라는 생각을 할 수 있었을까?
요즘 IP가 모자라서 난리를 친다. 왜 그럴까? IP를 만든 사람들이 돌 대가리라서 그렇다.
물론 IP를 만들 당시 32bit면 42억개가 넘는 IP를 만들 수 있으니 충분하다고 생각했겠지만 지금은 IP가 모자라 대안책을 내놓고 있는 실정이다.
뿐만 아니라 TCP에도 문제가 많다. 돌대가리들이 만들었으니 별 수 없을 것이다.
본인이나 여러분에게 있어 이 문제를 하나 하나 분석해 나갈 만큼 여유롭지 못할 것이다.
그래서 본인은 그 차이점만 명료하게 나열하고 자 한다.
- 제일 큰 차이점은 아무래도 IP의 크기 차이라하겠다. 기존의 IPv4는 32비트의 길이를 가졌는 데 새로운 IPv6는 128비트의 길이를 가진다. 이로 인해 IP 어드레스의 증가와 그 관리에 더 많은 융통성을 부여했다고 할 수 있다.
- IPv6의 새로운 헤더 구성이 전체적인 데이터 전송속도 개선을 가져왔다. 예로 IPv6에서는 fragmentation에 대한 헤더가 사라졌는 데 이 것은 일반적인 경우 필요가 없는 필드라서 packet의 처리 속도를 저하시키는 요인중 하나였다. 그리고 IP datagram의 크기가 제한이 없어졌다.
- IPv6에서는 보안을 위한 메커니즘을 기본적으로 제공한다.
7. TCP/IP 환경 설정
1 절 시작하면서
2 절 호스트 이름 설정
3 절 IP 어드레스 지정
4 절 hsots 파일과 networks 파일
5 절 Interface 설정 및 라우팅 테이블 만들기
6 절 TCP/IP 네트웍 점검
1 절 시작하면서
이 장에서 TCP/IP 설정에 관한 모든 문제의 해결책을 제시하지도 않으며 TCP/IP 설정시
맞닥드리게 되는 어려운 문제들을 다루지도않는다.
다만, 시스템에 처음 TCP/IP 설정시나 가장 일반적인 문제를 풀어가는 데 필요한 내용을
기술했다.
시스템에 TCP/IP 설정한다는 것은 실제 이론과는 달리 쉽지가 않다는 것을 직접 해 본
사람은 다 느낄 것이다. NIC(Network Interface Card, 흔히 LAN 카드라 부름)를 컴퓨터에 부착하는 것 부터 시작해야 하므로 만만치 않은 작업이 될 것이다.
그렇다고 시도 조차 해 보지 않고 포기할 정도로 어려운 편은 아니다.
요즘 왠만한 운영체제는 설치를 할 때 기본적으로 TCP/IP 설정의 많은 부분을 자동적으로 해결하기도 한다.
TCP/IP 설정을 할 때에는 일단 설정을 한 번하면 새로운 NIC 설치나 시스템의 완전히
고치는 경우가 아니라면 두 번 설정을 할 필요가 없다.
하지만 어떤 명령들은 재 부팅할 때 마다 실행되어야한다. 이러한 명령어들의 대부분은
/etc/rc 의 스크립트가 맡는다. 이런 작업을 수행하는 스크립트 이름은 rc.net 이나
rc.inet 으로 나타내며 어떤 시스템에서는 rc.inet1 혹은 rc.inet2로 나타나기도한다.
전자는 주로 커널 부분의 네특웍킹을 초기화 시키는 데 쓰이며, 후자는 기본이 되는
네트웍 프로그램(데먼들?)을 실행시키는 데 쓰인다.
2 절 호스트 이름 설정
호스트 이름을 설정은 보통 부팅할 때 hostname 명령으로 정해진다.
호스트 이름을 바꾸기 위해서는
$ hostname 호스트이름
와 같이 명령한다.
3 절 IP 어드레스 지정
만약, 네트웍 프로그램을 사용할 때 외부와의 접속을 하지 않고 자체적으로만 모든 작업을
하고자 한다면 루프백(loopback)을 사용하면 된다.
루프백 IP 어드레스는 항상 127.0.0.1이며 실제 인터넷에 접속한 것과 같이 수행된다.
예를 들면, 윈도우즈 95에서 퍼스널 웹 서버를 깔고 ASP 프로그래밍을 하거나, 리눅스에서
아파치 서버를 깔고 CGI 또는 Lite 프로그래밍을 한다고 가정할 때, 웹 브라우저를 켜 놓고
URL 입력창에 http://127.0.0.1/이라고 입력하면 로컬 웹 서버에 접속한다.
웹 서버 뿐만아니라 FTP 서버, Telnet 서버 등도 루프백 주소로 다 접속할 수 있다.
하지만 대부분의 경우 소규모 네트웍이나 인터넷에 접속하기를 원할 것이다.
4 절 hosts 파일과 networks 파일
인터넷상의 모든 컴퓨터는 IP 로 구별된다는 것을 여러분은 잘 알 고 있을 것이며,
IP 주소를 외우기가 쉽지않아 도메인 명이라는 것을 쓴다는 것도 잘 알고 있을 것이다.
다른 컴퓨터에 접속하기 위해서는 IP를 직접 사용하든가, 아니면 호스트 이름을
사용할 수 있다.
호스트 이름을 사용할 경우 여러분의 시스템 자체에서 간단하게 호스트 이름을 IP 주소로
바꾸어 주는 기능을 추가할 수 있다.
/etc/hosts 파일이 그것인데 만약 DNS 나 NIS 를 사용하지 않겠다면 여러분은 이 파일에
모든 호스트(인터넷 상의 모든 도메인)명을 집어 넣어야할 것이다. 이렇게 한다면
얼마나 비 효율적인지 설명하지 않아도 알것이다. 그래서 DNS나 NIS를 병행해서 사용하며
/etc/hosts 파일에는 몇 몇 자주 접속하는 FQDN을 적고 그 Alias 정도를 사용하는 데 만족하는 것이 일반적이며 또 다른 장점은 그 호스트 이름을 rc.inet 스크립트에서도 사용할 수가 있다. 그러므로 만약 IP 어드레스를 바꾼다면 그냥 /etc/hosts 파일을 수정해 주고
재 부팅하면 되는 것이다. 즉, rc에 있는 파일들을 일일이 수정해야 하는 번거러움을 덜게
되는 것이다.
그리고 꼼꼼한 셋업을 원하는사람은 맨 처음 시스템에 TCP/IP 설정을 할 때는 DNS 나 NIS 의 도움을 받지 않고 /etc/hosts 만으로 테스트 해보는 것도 괜찮을 듯하다.
그리고 /etc/host.conf 파일에는
order hosts
라인을 넣어 주어야 하는 데, 이 뜻은 네트웍 프로그램들이 외부 접속을 위해 호스트명을 제시하며 IP어드레스를 가르쳐 달라고 요구할 때 먼저 /etc/hosts 파일을 찾아 보아라는 뜻이 된다.
/etc/hosts 파일에는 라인 마다 IP 어드레스, 호스트 네임(FQDN), 그리고 생략가능한 별명(Alias)이 들어가며 구분은 공백 문자나 탭 문자로 시작한다. IP 어드레스는 맨 첫칸에서 부터 시작해야하며 주석은 # 으로 시작한다.
아래에 예를 들어 보겠다.
/etc/hosts 파일의 내용
# IP 어드레스를 써 주고 그 다음에 FQDN, 그리고 Alias를 써 주자.
# 물론 꼭 그렇게 해야만 되는 것은 아니지만 원칙은 지키라고 만들어 놓은 것임을 유념하자.
# Alias는 생략가능하다.
127.0.0.1 localhost
203.237.229.135 css.dankook.ac.kr css
203.237.229.163 web-team.ml.org web-team
이상과 hosts 파일을 작성했다면 여러분은
# telnet web-team
와 같이 입력해서 웹팀의 서버에 접속할 수 있다. 그런데 여러 글자를 쳐야 하므로 좀 귀찮다.
본인의 경우는
# web-team
와 같이 입력하면 바로 웨팀의 서버에 접속할 수 있도록 앨리어싱해서 쓰고 있다.
/etc/networks 파일에는 네트웍 주소를 지정하기 위해 심볼릭을 사용하고 싶은 경우 작성할 수가 있다. 이에 대한 자세한 사항은 생략하겠다.
/etc/networks 파일의 예
# /etc/networks 예
css-net 203.237.229.0
sin-net 203.237.225.0
7장 5 절 Interface 설정 및 라우팅 테이블 만들기
Interface란? (이 글의 맨 끝을 참조하기 바람)
실제 NIC를 설치했다고 바로 사용할 수 있는 것이 아니라는 것 쯤은 다들 알고 있을 것이다.
장치를 시스템에 부착했으면 커널에게 알려주어야 하는 데, 장치를 제대로 부착했는지 안했는 지 어떻게 알 수 있을 까? 물론 잘 해야 알겠지만 그게 어디 쉬운일인가.
본인의 경우 RealTek 랜 카드를 설치한 경험을 기술해 보겠다. 보통 3 Com Lan 카드를 사용하면 쉽게 잡을 수 있는 데 이와 같은 이상한(?) 랜 카드를 사용하면 거의 며칠 밤을 꼬박 새워야 하는 경우가 허다하다.
우선 도스모드에서 PnP 기능을 끈다.
IRQ와 IO, 그리고 필요하다면 DMA번호를 체크한다.
리눅스로 부팅해 알맞는 네트웍모듈을 찾아라.
이더넷 하드웨머 모듈을 메모리에 적재시킨다.
이상과 같이 순조롭게 새 장치를 커널이 인식했으면
부팅할 때 마다 자동적으로 로딩되도록 /etc/conf.modules 파일에 추가
이와 같이 과정이 준비되어 있다면 아래의 설명을 계속 읽어 나가도 좋다.
이 때 사용되는 명령어에 대해서 알아보자. 주로 인터페이스를 설정하는 명령과 라우팅 테이블을 만드는 두 가지 명령으로 구분하는 데 ifconfig와 route 명령이 그것이다. 주로 이러한 작업은 시스템이 부팅할 때 마다 rc.inet1 스크립트에서 이루어지는 데 어떤 이유에서든지 부팅시에 초기화 되지 않는다면 직접해주면 된다.
ifconifg명령는 'interface config'의 약자로서 해당 인터페이스를 커널 네트웍킹 부분에 인식시켜주는 역활을 한다. 이렇게 하기 위해서는 IP 어드레스와 기타 옵션이 필요한 데, 설정이 되면 커널은 패킷을 그 인터페이스를 통해 주고 받고 한다.
ifconfig 명령의 형식는 주로 아래와 같다.
ifconfig interface ip-address
위 명령은 ip-address를 지정한 interface에 부여하고 활성화 시킨다. 그 외에도 지정할 수 있는 옵션이 있는 데 생략할 경우 기본값이 들어간다.
예를 들어, 기본 서브넷 마스크 값은 그 IP 어드레스의 네트웍 클래스에 따라 지정이 되는 데 만약 C 클래스라면 255.255.255.0이 기본값이 된다.
route 명령을 사용하여 커널의 라우팅 테이블에서 routes(데이터가 이동되는 통로)를 추가 혹은 삭제할 수 있다.
route 의 명령어 형식은 아래와 같다.
route [add | del] target
우리는 7장 3절에서 loopback에 대해서 알아보았다. 여기에서 loopback 인터페이스를 설정하는 예를 들어 보겠다.
$ ifconfig lo 127.0.0.1
위 명령에서 인터페이스는 lo 이며 그 IP 어드레스는 127.0.0.1이다. 물론 127.0.0.1 이라는 IP 어드레스 대신 localhost라는 심볼릭을 써도 상관이 없다. 왜 그런지 이해가 안된다면 /etc/hosts 파일 설명 부분을 다시 살펴 볼 것을 권한다.
특정 인터페이스의 설정 내용을 보려고 한다면 ifconfig 명령에 인터페이스 명만을 파라메타로 주면된다.
$ ifconfig lo
lo Link encap Local Loopback
inet addr 127.0.0.1 Bcase [NONE SET] Mask 255.0.0.0
.......... MTU 2000
..........
'fconfig lo' 와 같이 명령을 내리면 위와 같은 결과를 출력할 것이다.
127.0.0.1 은 A 클래스에 속하기 때문에 넷 마스크를 255.0.0.0이 기본값으로 잡혔다.
그 다음에는 데이터가 127.0.0.1을 통해서 전달될 수 있도록 route 명령으로 리우팅 테이블에 추가를 해야한다.
$ route add 127.0.0.1
이상과 같이 명령을 했다면 제대로 수해이 되는 지 체크를 해야할 것이다.
이 때 많이 쓰이는 명령어로는 ping 이 있는 데 기본 형식은 다음과 같다
# ping localhost
이 명령이 하는 일은 주어진 도메인명 (또는 IP 어드레스)에 도달할 수 있는 지 체크하고 그 도메인으로 부터 데이터를 주고 받을 때 지연되는 시간을 측정한다.
# ping localhost
PING localhost (127.0.0.1) : 56 data bytes
64 bytes from 127.0.0.1: icmp seq=0 ttl=32 time=1 ms
64 bytes from 127.0.0.1: icmp seq=0 ttl=32 time=0 ms
64 bytes from 127.0.0.1: icmp seq=0 ttl=32 time=0 ms
^C
--- localhost ping statics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0/0/1 ms
ping localhost 와 같은 명령을 내렸을 때 위와 같은 내용이 나오면 제대로 수행 되고 있다고 볼 수 있다. 위의 경우 ping 명령을 수행하면 끝 없이 패킷을 주고 받고 하는 데 이 때는 CRTL + C를 눌러 프로그램을 종료시킨다.
시스템 마다 ping 명령의 결과가 다르게 나타날 수 있다.
예를 들면
# ping localhost
localhost is alive.
와 같이 나타나는 경우도 있다.
또 어떤 경우는 25% packet loss 와 같이 나타나기도 하는 데 네트웍 병목현상 때문일 수도 있고, 하드웨어적인 문제 등 기타 여러가지가 원인이 될 수가 있다. 심한경우는 75% 이상 패킷이 손실되는 경우도 있다.
만약 ping 명령을 했는 데 100% packet loss나 또는 위와 비슷한 결과가 나타나지 않는다면 뭔가가 분명히 잘 못되었다고 생각되는 데 이때는 몇 몇 환경 설정 파일이 제대로 작성되지 않았는지, route 프로그램과 커널 버젼이 맞지 않는지, 커널을 조정할 때 networking 이 enable 되었는지를 확인해 본다.
ping 명령을 했을 때 "Network unreachable"과 같은 메세지가 나온다면 아마도 route 명령을 잘 못 사용했을 경우가 많다.
이상과 같이 설정을 제대로 했다면 자체 네트웍킹을 하는 데는 아무런 문제가 없을 것이다.
참고로 /etc/rc의 rc.inet 파일을 살펴보기를 권한다.
실제로 네트웍이나 인터넷에 연결이 되지 않더라도 OS는 loopback을 이용해 많은 작업을 하기 때문에 loopback 인터페이스는 시스템에 항상 설정되어 있어야 한다. 또 대부분 기본적으로 설정이된다.
다음으로 Ethernet Interface 설정에 대해서 알아보겠다.
많은 부분을 loopback interface 설정할 때 설명을 했으나 실제 여러분이 자세히 알아야하는 부분이라 생각되기에 여러분이 직접 실습을 해 볼 수 있도록 완전한 예를 들어가면서 차근 차근 설명하기로 하겠다.
좀 어려운 예가 될지도 모르겠지만 C 클래스 203.237.228 네트웍 주소를 다시 네개로 subnetting 한 뒤 그 중 세 번째 네트웍을 가지고 예를 들어 보겠다.
이 C 클래스에서 세번째 서브 네트웍을 할당 받았다면 실제 사용할 수 있는 IP 어드레스는 203.237.228.128 부터 203.237.118.191까지가 되는 데 보통 첫 IP 어드레스는 네트웍 번호로 그리고 마지막 호스트 주소와 그 앞 호스트 주소는 브로드 캐스트용 및 게이트 웨이 용으로 사용되로 실제 사용할 수 있는 IP 어드레스는 64개가 안된다.
다시 한번 언급하는 것이지만 Interface를 설정하기 위해서는 컴퓨터에 NIC를 꼽을 때 커널에 먼저 인식 시켜야 한다는 것을 잊지말아야 겠다.
우선 ifconfig 명령으로 인터페이스를 설정한다. 새로 설치한 Ethernet Interface를 203.237.228.130의 어드레스를 부여하고자 한다면
# ifconfig eth0 203.237.228.130 netmask 255.255.255.192
와 같이 입력한다. 여기서 netmask 옵션의 값을 255.255.255.192로 주었다.
왜 이렇게 주었을까? 여러분이 처음 인터페이스 설정을 해 본다면 아주 많이 생각해야 할 것이다.
하나의 C 클래스는 256개의 호스트 주소를 가질 수 있다. 256를 4개로 나누면 64가 된다. 맞는가?
즉, C 클래스를 4개로 subnetting하면 호스트 주소가 64개 짜리인 네트웍이 4개가 생긴다.
위에서 세 번째 네트웍 주소를 할 당 받는다는 것을 명시했으므로 이 C 클래스에서 128 부터 191까지가 우리에게 할 당된 IP 주소이다.
자세히 설명을 하면 첫 번째 네트웍 주소는 203.237.228.0 부터 203.237.228.63까지 이며, 두 번째 네트웍 주소는 203.237.228.64 부터 203.237.228.127까지, 그 다음 우리에게 할당된 세번째 네트웍은 203.237.228.128 부터 203.237.228.191 까지가 된다.
그리고 마지막 네트웍의 주소는 203.237.228.192 부터 끝까지인 203.237.228.256 이 된다.
여기서 우리는 넷 매스킹을 수행해야 할 필요가 있다. 넷 매스킹이란 먼저 설명했듯이 두 개의 비트 값을 AND 연산해 참이면 1을 취하고 거짓이면 0을 취한다.
왜 이런게 필요할까? 네트웍 구분을 위해서이다.
패킷을 내 보낼 때 그 패킷이 전송되어야 할 네트웍을 알아보고 일치한다면 그 인터페이스를 통해 데이터를 방출해야하기 때문이다.
일단은 계속 진행을 하자.
위 명령이 제대로 수행되었나 보려면 아래와 같은 명령을 입력한다.
# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 52:54:4C:01:43:17
inet addr:210.123.83.130 Bcast:210.123.83.255 Mask:255.255.255.192
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:771 errors:0 dropped:0 overruns:0
TX packets:439 errors:0 dropped:0 overruns:0
Interrupt:3 Base address:0x260
위와 같은 결과가 나오면 제대로 설정이 되었다.
위에서 Bcast나 MTU등은 다 설명을 했으므로 다시 언급하지 않겠다.
인터페이스 설정을 해다고 다 끝나는 것이 아니다.
인터페이스 설정을 했으면 데이터 패킷를 보낼 때 어떤 경로를 통해 보내야 할지를 지정해 주어야한다.
실제 대부분의 경우 한 컴퓨터에 패킷을 내 보낼 수 있는 두 개이상의 경로가 존재한다.
# route add -net 203.237.228.128
route 명령에서 net 옵션은 위에서 설명했지만 다시 한번 설명해 보겠다.
route 명령에서 net 옵션을 사용하여 네트웍 주소를 추가할 수 있는 데, 이유는 나중에 커널이 패킷을 내 보낼 때 위에서 지정해준 네트웍 주소와 일치하는 값이 있다면 그리로 내보내기 때문이다. 위에서도 설명할 때 패킷을 내 보낼 때 그 패킷이 전송되어야 할 네트웍을 알아보고 일치하면 그 인터페이스를 통해 데이터를 방출한다고만 얘기하고 자세한 언급을 하지 않았는데 여기서도 마찬가지로 자세한 내용은 조금 더 뒤로 미루겠다.
일단, 위와 같이 명령을 하면 라우팅 테이블에는 다음과 같이 나올 것이다.
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
203.237.228.128 0.0.0.0 255.255.255.192 U 0 0 6 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 5 lo
위와 같은 결과가 나왔다면 어떤 상태임을 나타내는가? 여러분이 위 결과를 한 눈에 파악할 수 있다면 상당한 실력을 가지고 있다고 생각이 된다.
"라우팅 테이블은 패킷 어디를 통해 전달되어야 하는 가를 나타내는 것이다." 라는 것은 수 없이 얘기했으므로 지금 쯤은 누구나 다 알고 있을 것이다.
위에서는 두 개의 라우트(route)를 볼 수 있다. 즉 데이터를 보낼 수 있는 길은 단 두 곳 뿐이라는 뜻이다.
Destination은 네트웍 번호를 나타내며 Genmask는 매스크 비트를 나타낸다.
이 쯤에서 우리는 커널이 패킷을 외부로 보낼 때 어떤 일을 하는지 하나 하나 따져 보는 것이 필요하겠다.
1. 먼저 패킷을 전달할 목적지 주소를 읽어들인다.
2. 그리고는 라우팅 테이블을 살펴 그 Destination을 결정한다. 그렇게 하기 위해서는 먼저 Genmask 의 값을 읽어 목적지 주소와 넷매스킹(비트 AND 연산)을 하고 그 결과가 Destination의 값과 같은지 비교를 하는 것이다.
3. 이 때 두 값이 같다면 Iface 필드에 지정된 인터페이스를 통해 패킷을 전송한다.
4. 만약 두 값이 같지 않다면 다음 라인의 Genmask 값을 읽어 비교하며 계속 반복 작업을 한다.
5. 라우팅 테이블의 모든 라인의 Genmask의 값과 목적지 주소값을 넷 매스킹해서 Destination과 같은 값이 나오지 않는다면 에러를 내거나 패킷을 보내지 않는다.
그럼 실제 패킷을 보내 보고 위와 같은 과정을 조목 조목 따져 보자.
실제 이 과정을 이해하는 것이 아주 중요하다고 생각된다.
# ping 203.237.228.129
와 같이 명령을 내렸다면 먼저 커널은 목적지 주소인 203.237.228.129를 취한다.
그리고는 라우팅 테이블에서 첫 번째 라인의 Genmask 값을 읽어 들인다. 위 예에서
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
203.237.228.128 0.0.0.0 255.255.255.192 U 0 0 6 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 5 lo
위의 라우팅 테이블에서 첫 번째 라인의 Destination은 203.237.228.128, Genmask는 255.255.255.192, 그리고 Iface는 eth0이다.
그럼 목적지 주소인 203.237.228.129와 Genmask 값인 255.255.255.192를 넷매스킹을 할 차례이다.
넷매스킹의 결과는 203.237.228.128이다. 넷매스킹하는 방법은 위에서 설명을 했으므로 다시 설명하지 않겠다.
그러면 이 결과가 현재 라인의 Destination과 일치하는 지 비교를 해야한다.
비교를 하면 일치한 다는 것을 알 수가 있다. 그러므로 그 라인에서 Iface(인터페이스) 필드에 지정된 eth0(경로)를 통해 패킷을 내 보낸다.
또 다른 예를 들어보자.
# ping 203.237.229.162
와 같이 명령을 내렸다면 먼저 커널은 목적지 주소인 203.237.229.162를 취한다.
그리고는 라우팅 테이블에서 첫 번째 라인의 Genmask 값을 읽어 들인다. 위 예에서
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
203.237.228.128 0.0.0.0 255.255.255.192 U 0 0 6 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 5 lo
첫 번째 라인의 Destination은 203.237.228.128, Genmask는 255.255.255.192, 그리고 Iface는 eth0이다.
그럼 목적지 주소인 203.237.229.162와 Genmask 값인 255.255.255.192를 넷매스킹을 할 차례이다.
네매스킹의 결과는 203.237.229.128이다. 아쉽게도 세 번째 부분에서 Destination 값과 일치하지 않는다.
그러면 라우팅 테이블에서 다음 라인을 읽는다.
두 번째 라인의 Destination은 127.0.0.0, Genmask는 255.0.0.0, 그리고 Iface는 lo 이다.
다음으로 할 일은 목적지 주소인 203.237.229.162와 Genmask 값인 255.255.255.192를 넷매스킹을 하는 것.
네매스킹의 결과는 203.0.0.0이다. 모든 부분에서 Destination 값과 일치하지 않는다.
그러면 라우팅 테이블에서 다음 라인을 읽어 들여서 비교를 해야 하는 데 더이상 비교할 것이 없기 때문에
아래 명령의 결과로
# ping 203.237.229.162
PING 203.237.229.162 (203.237.229.162): 56 data bytes
ping: sendto: Network is unreachable
ping: wrote 203.237.229.162 64 chars, ret=-1
ping: sendto: Network is unreachable
--- 203.237.229.162 ping statistics ---
2 packets transmitted, 0 packets received, 100% packet loss
와 비슷한 에러 메세지를 낸다.
지금이 어떤 상태인가? 제대로 된 것인가? 그렇다.
분명 제대로 네트웍이 설정된 상태다. 왜냐하면 현재 까지의 설정만으로도 내부 네트웍을하는 데는 아무런 무리가 없으니.
그렇다면 정말 이것으로 끝인가? 분명 아니라는 것은 여러분도 잘 알고 있을 것이다.
만약 여러분이 내부 네트웍만 사용하고자 않다면 이정도에 만족 할 지도 모르겠다.
하지만 어찌 인터넷에 접속하고 싶지 않으랴!
우리가 원하는 ping 명령의 결과는 아래와 같을 것이다.
# ping 203.237.229.162
PING 203.237.229.162 (203.237.229.162): 56 data bytes
64 bytes from 203.237.229.162: icmp_seq=0 ttl=54 time=81.7 ms
64 bytes from 203.237.229.162: icmp_seq=1 ttl=54 time=150.1 ms
64 bytes from 203.237.229.162: icmp_seq=2 ttl=54 time=47.0 ms
64 bytes from 203.237.229.162: icmp_seq=3 ttl=54 time=48.5 ms
--- 203.237.229.162 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 47.0/81.8/150.1 ms
어떻게 해야 할까? 분명 203.237.229.162는 전혀 다른 C 클래스 주소이다.
일단, 커널이 어떻게 패킷을 내 보내는가는 알았다.
하지만 인터넷상의 모든 네트웍 주소를 라우팅 테이블에 집어 넣어도 되는 것일까?
그렇게 해 보지 않아서 모르겠지만 좋은 생각이 아닌 것 만은 틀림없다.
우리는 기본 라우트라는 것이 있다는 것을 알아야한다.
기본 라우트가 하는 일은 목적지 주소을 Genmask와 넷매스킹한 뒤 그 값과 일치하는 Destination이 없는 경우 그 패킷을 받아 어디로 보내야 할 지 결정해 그 곳으로 보내주는 역활을 한다.
대부분의 경우 여러분은 여러분의 네트웍 관리자에게 문의해서 기본 게이트웨이의 IP 어드레스를 알아내야한다.
만약 그 IP 어드레스가 203.237.228.190이라 하고
여러분은 네트웍 관리자로부터 그 IP 어드레스를 알아내었다고 가정하자.
이제 어떡할 것인가?
단순히 아래의 명령으로 기본 게이트웨이를 라우팅 테이블에 추가해 주면된다.
# route add default gw 210.123.83.190
기본 게이트웨이를 라우팅 테이블에 추가했다.
다시 ping 명령을 수행해 보자.
# ping 203.237.229.162
PING 203.237.229.162 (203.237.229.162): 56 data bytes
64 bytes from 203.237.229.162: icmp_seq=0 ttl=54 time=81.7 ms
64 bytes from 203.237.229.162: icmp_seq=1 ttl=54 time=150.1 ms
64 bytes from 203.237.229.162: icmp_seq=2 ttl=54 time=47.0 ms
64 bytes from 203.237.229.162: icmp_seq=3 ttl=54 time=48.5 ms
--- 203.237.229.162 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 47.0/81.8/150.1 ms
위와 같은 결과나 나올 것이다.
조금 지겹더라도 우리는 커널이 패킷을 전달하는 과정을 다시 한번 밟아 보자. TCP/IP가 네트웍킹의 핵심이라면 TCP/IP 설정에서 이부분이 핵심이라 해도 지나치지 않을 것이다.
먼저 커널은 목적지 주소인 203.237.229.162을 읽는다.
그 다음 라우팅 테이블의 첫 번째 라인의 정보를 읽는 데, Destination은 210.123.83.128, Genmask는 255.255.255.192, Iface는 eth0이다라는 것을 알 수 있다.
그 다음은 목적지 주소인 203.237.229.162와 Genmask 값인 255.255.255.192를 넷매스킹을 할 차례이다.
그 결과는 203.237.229.128이다. Destination 값과 일치하지 않는다.
커널은 다시 두 번째 라인의 정보를 읽는다.
Destination은 127.0.0.0, Genmask는 255.0.0.0, Iface는 lo 이다.
목저지 주소와 Genmask와 넷매스킹한다. 엮시, 결과는 Destination과 일치하지 않는다.
그 다음 커널은 어떤 일을 해야 하겠는가? 상상을 한 번 해 보자.
우리는 기본 게이트웨이를 추가 했다. 그 게이트웨이는 라우팅 테이블에서 일치하는 네트웍 주소가 없을 경우 모든 패킷 전달을 맡는다. 기본 게이트웨이라고 특별히 라우팅 테이블에 나타나지 않거나 전혀 어뚱한 값이 들어가지는 않는다.
기본 게이트웨이도 마찬가지로 그 Genmask와 목적지 주소와 넷매스킹을 한다. 이 때 그 결과 값은 항상 Destination과 일치한다. 당연히 그래야만 그 곳에 지정된 Iface로 패킷을 보내지 않겠는가?
그럼 과연 Destination 과 Genmask에는 어떤 값이 들어가 있어야 항상 목적지 주소와 Genmask를 넷매스킹한 값과 Destination 값이 일치하겠는가?
우리는 넷매스킹이 어떠한 연산을 하는지 알고있다.
Destination 값이 0.0.0.0 이고 Genmask 값이 0.0.0.0 이라면 목적지 주소가 어떤 값이든지 상관없이 Genmask와의 넷매스킹의 값은 항상 0.0.0.0 이 나오며 Destination 과 일치하게 된다.
실제 라우팅 테이블을 한 번 살펴보면 다음과 같이 나타난다.
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
203.237.228.128 255.255.255.192 U 0 0 8 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 7 lo
0.0.0.0 203.237.228.192 0.0.0.0 UG 0 0 1 eth0
맨 아래 라인이 기본 게이트웨이를 가르키는 부분인데 어떻게 나와있나? Destination과 Genmask값이 0.0.0.0 이라는 것을 알 수 있다. Gateway에는 실제 기본 게이트웨이 주소인 203.237.228.192 이 나와있다.
위에서
# route add default gw 203.237.228.190
와 같이 명령을 내렸는데 원래 route add 다음에는 타겟 IP가 오는 데 위에서는 default라는 심볼릭을 사용했다.
default 대신에 0.0.0.0을 사용해도 된다.
# route del default
# route add -net 0.0.0.0 gw 210.123.83.190 netmask 0.0.0.0
와 같이 테스트를 해 보라.
좀 긴 글이라 지루하게 느껴졌는 지 모르겠지만 마지막으로 마무리를 해보겠다.
TCP/IP 환경을 설정하기 위해서는
1. 커널에 NIC를 알린다.
2. 인터페이스를 잡는다.
3. 내부 라우팅을 잡는다.
4. 기본 게이트웨이를 라우팅 테이블에 추가한다.
제 8 장 용어정리
인터페이스 (Interface) : 여러가지의 뜻이 있으나 여기서는 컴퓨터를 서로 이어주는 중간매체를 의미한다.
이더넷 카드가 인터페이스의 한 종류라 할 수 있겠다.
출처:http://database.sarang.net/study/tcp-ip/tcpip3.html
자료2
1. TCP/IP 소개 및 개요 1.1 인터네트워킹의 생성 컴퓨터에 있어서 데이터 통신은 이미 가장 기본적인 부분의 하나가 되었다. 컴퓨터 사용자들은 전세계에 퍼진 네트워크를 통해 기후 상태나 곡물생산량, 항공편 운행상태와 같은 여러 주제에 관련된 데이터를 수집하고 있고, 전자 메일링 리스트를 사용하여 공동관심사에 대한 정보를 교환하고 있으며, 프로그램들을 서로 교환 하고 있다. 예전의 (그리고 현재의 몇몇) 네트워크들은 몇몇 사용자들에 의해 사용되는 독립적인 형태로 존 재했다. 따라서 사용자들은 하드웨어 사양을 자신들이 속해있는 네트워크 사양에 맞추어 설정해 야했다. 더욱이 모든 네트워크 사양을 지원하는 단일 네트워크가 존재하지 않기 때문에 하나의 하드웨어 사양을 이용한 광범위한 네트워크를 만드는 것이 불가능 했다. 지난 15년 동안, 서로 떨어져 있는 각각의 수많은 네트워크들을 연결하여 하나의 네트워크로 연 결하여 사용할 수 있도록 해주는 기술이 개발되어져 왔다. 인터네트워킹이라 불리우는 이 기술은 서로 다른 종류의 네트워크를 연결시키고 하나의 통신 기준 집합을 둠으로서 여러 가지의 다양한 하드웨어기술을 다루게 해 주었다. 인터넷 기술은 네트워크 하드웨어의 복잡한 부분은 감추고 컴퓨터들에게 자신이 속한 물리적 네트워크에 관계없이 통신할 수 있도록 한다. 이로 인하여 한 네트워크 상의 호스트에서 사용되는 컴퓨터 서비스들과 그 프로그램들을 멀리 떨어진 다른 네트 워크 상의 호스트에서 사용하는 것이 가능해졌다. 1.2 TCP/IP의 등장배경 미국 정부에서도 인터넷 기술의 중요성과 그 잠재력을 인정하여 많은 기간동안 인터넷을 만들기 위한 기반 연구를 진행해 왔다. ARPA에 의해 주도된 이들 연구는 인터넷 기술의 여러 가지 기반기술과 개념들을 만들고 발전 시켜왔다. 이들 기술들 중에는 컴퓨터들이 서로 통신하는 것에 대한 세밀한 표준도 포함된다. 공 식적으로 TCP/IP Internet Protocol Suite라고 불리우고 일반적으로 TCP/IP라고 불리우는 이 표준은 서로연결된 어떠한 네트워크들의 집합들 사이에서라도 통신 기 본 프로토콜로써 사용되어진다. TCP/IP 기술은 가정과 대학 캠퍼스, 학교, 기업, 그리고 정부 연구기관등이 서로 연결된 전세계 적 규모의 인터넷을 구성하는 기반을 만들었다. NSF, DOE, DOD, HHS, NASA 등의 미국 연구 기관들이 인터넷을 창설하는데 참 가하였고 자신들의 연구 사이트들을 연결하는데 TCP/IP를 사용하였다. ARPA/NSF 인터넷, TCP/IP 인터넷, 글로벌 인터넷으로도 불 리우는 인터넷은 전세계의 정보들을 마치 옆방 컴퓨터안의 정보를 검색하는 것과 같이 사용할 수 있는 환경을 만들어 주었다. 1.3 TCP/IP기반의 인터넷 서비스들 TCP/IP의 기본 구조는 다음과 같다.  그림 1. TCP/IP 기본 구조 이 구조상에서 지원되는 인터넷 서비스들은 다음 두가지로 나눌 수 있다.
1.3.1 응용수준의 인터넷 서비스들 가장 유명하고 널리 사용되는 인터넷 응용 서비스들은 다음과 같다. o 전자 메일 : 전자 메일은 메모를 작성하고 이를 개인이나 그룹에 전송하는 기능을 수행한다. 또 다른 사용자가 보낸 메모를 받아 이를 읽을 수 있게 하는 기능도 가지고 있다. 많은 전자 메일 시스템이 존재하지만, TCP/IP 를 사용하는 것은 좀더 나은 신뢰성을 보장해주는데, 이는 이 방법이 메일 메시지를 보내는 과정 에서 송신, 수신 호스트 사이에 있 는 연결노드에 영향을 받지 않기 때문이다. 즉, TCP/IP 메일 전송 시스템은 송신, 수신 호스트들 이 직접 연결되어 작동하기 때 문에 좀 더 신뢰성 높은 메일 전 송을 할 수 있게 해준다. o 파일 전송 : TCP/IP 프로토콜은 큰 프로그램이나 데이터 파일을 전송할 수 있게 해주는 파일 전송 응용 프로그램을 포함한다. 이 시스템은 접근 허가를 받은 사용자인지를 검색할 수 있게 하는 기능, 혹은 모든 접근을 거부 하게 하는 기능을 제공한다. 메일과 마찬가지로, TCP/IP 위에서의 파일 전송은 양쪽 호스트들이 직접 연결되기 때문에 신 뢰성 높은 전송이 가능해진다. o 원격 접속 : 원격 접속 시스템은 사용자가 한 컴퓨터에 앉아서 멀리 떨어진 시스템에 접속하고 상호 대화가 가능한 접속 세션을 연결시켜 사용할 수 있도록 도와준다. 원격 접속 시스템은 원 격 시스템과 직접 연결된 창을 사용자의 시스템 화면에 출력하고 , 사용자의 시스템의 입력과 원격시스템의 출력을 창을 통해 표시한다.
1.3.2 네트워크수준의 인터넷 서비스들 네트워크수준에서, 인터넷은 모든 응용프로그램들이 사용하는 다음과 같은 두가지 형태의 서비스 를 제공한다. o 비연결 패킷 전송 서비스(Connectionless Packet Delivery Service) : 이 서비스는 모든 다른 인 터넷 서비스들에 대한 기반을 만들어 준다. 비연결 전송은 대부분 패킷 스위칭 네트워크들에서 사용된다. 비연결 서비스는 각 각의 패킷을 독립적으로 전송하기 때문에 신뢰성을 보장할 수 없다. 하부의 하드웨어와 직접적으 로 대응이 가능하기 때문에, 비 연결 서비스는 보다 효율성있게 사용될 수 있다. 기본 인터넷 서비스로 비연결 패킷 전송을 사용함으로써 TCP/IP 프로토콜이 많 은 네트워크 하드웨어에 적용될 수 있다. o 신뢰가능한 흐름 전송 서비스(Reliable Stream Transport Service) : 대부분의 응용프로그램들 은 송신자와 수신자 사이에서 패킷전송 에러나 패킷 손실 등의 에러를 자동으로 복구시켜줄 통신 소프트웨어가 필요하다. 신뢰 가능한 전송 서비스는 이런 문제점들을 다룰 수 있게 한다. 이 서비스는 한 호스트에서 수행되는 하나의 응용프로그램이 다른 호 스트에서 수행되는 응용프로그램과 "연결(connection)"을 생성하여 데이터를 전송 한다.
2. 인터넷 주소(Internet Address) 2.1 개요 인터넷은 소프트웨어로써 구현되는 가상 구조로 만들어져 있다. 따라서 하드웨어에 관계없이 패 킷 형식이나 크기, 주소, 전송기 술 등을 자유롭게 설정할 수 있다. IP 구조에서, 인터넷상의 호스트 각각은 인터넷 주소, 혹은 IP 주소라고 불리우는 32비트의 정수 주소를 배정받게 된다. 개념상로 각각의 주소들은 한쌍(netid, hostid)로 구성되어있다. netid는 네트워크를 나타내고, hostid는 그 네트워크상의 호스트를 나타낸다. 모든 IP 주소들은 그림 2에 나와있는 처음 세가지 형태중 하나로 구성되어 있다. 
그림 2. 인터넷 주소(IP)의 다섯가지 형태 IP 주소의 종류는 처음 세 개의 비트로서 결정되어진다. 클래스 A 주소는 호스트 수가 2의 16승 (65,536)이상 되는 네트워크에 배당이 되고 netid로 7비트, hostid로 24비트가 주어진다. 클래스 B 주소는 호스트 수가 2의 8승(256)이상이고 2의 16승이하인 네트워크에 배당이 되고 netid로 14비 트, hostid로 16비트가 주어진다. 마지막으로, 클래스 C 주소는 호스트 수가 2의 8승이하인 네트워크 에 배당이 되고 netid로 21비트, hostid로 8비트가 주어진다. 2.3 네트워크 주소와 브로드캐스트 주소 인터넷 주소는 호스트를 나타내는 것과 마찬가지로 네트워크를 나타낼 수 있다. 즉, IP 주소의 hostid 값이 0이면 네트워크 자체를 가리키게된다. 또한 인터넷 주소는 네트워크상의 모든 호스트들을 나타내는 브로드캐스트 주소를 가질 수 있다. 표준안에 따라, hostid 값이 0이면, 이 IP 주소는 브로드캐스트 주소로 사용된다. 이 주소는 이더 넷과 같은 네트워크기술에서 유용하게 쓰일 수 있다. 그림 3은 이러한 특별한 형태의 IP 주소들을 보여준다. 
그림 3. 특별한 형태의 IP 주소들 2.4 서브넷 주소처리 어떤 한 사이트에서 여러개의 물리적 네트워크를 하나의 네트워크 주소로서 사용할 수 있게 하는 기법을 서브넷 주소처리라고 한다. 그림 4와 같이 네트워크 주소의 hostid 부분을 두 영역으로 나누어 각 각 물리적 네트워크와 호스트를 나타내게 한다. 
그림 4. 서브넷 주소처리 이 기법은 한 사이트내에 있는 라우터들과 호스트들에 의해서만 사용되어질 수 있으며, 다른 곳에서는 일반적인 주소로서 처리된다. 그림 5는 서브넷 주소처리에 의해 나누어진 하나의 네트워크(128.0.0.0)의 예를 보여준다. 
그림 5. 서브넷 주소처리된 네트워크의 예 3. ARP와 RARP 3.1 ARP 앞에서 인터넷은 패킷을 보내거나 받을 때 IP 주소를 사용하는 하나의 가상망이라고 설명했었다. 이 가상망상에서 두 호스트들 이 통신하기 위해서는 각각의 호스트의 물리적 네트워크 주소를 얻어내어 IP주소를 대응시켜야 한다. 이더넷 같은 네트워크에서 브로드캐스트 기능을 사용하여 이 작업을 수행하게 하는 프로토콜 을 Address Resolution Protocol(ARP)이라고 한다. 이 방법은 새로 코드를 컴파일 시킬 필요없이 새 로운 호스트를 네트워크에 포함시킬 수 있고, 중앙처리형의 데이터베이스같은 것을 필요로 하지 않는다. 주소 대응 테이블를 유지하 지 않고 기능을 수행하게 하기 위해, 설계자는 주소를 동적으로 연결하기 위해 저수준의 프로토콜을 사용했다. Address Resoluton Protocol(ARP)라 불리우는 이 프로토콜은 효율적이고 쉽게 사 용할 수 있는 구조를 제공해준다. 그림 6는 ARP의 동작과정을 보여준다. 호스트 A가 IP address IB 의 물리적 네트워크 주소를 알아내고자 할 때, 호스트 A는 IP 주소 IB 를 가지고 있는 호스트에게 물리적 네트워크 주소 PB 를 보내주도록 요청하는 특별한 패킷을 브로드캐스트한다. B를 포함한 모든 호스트들은 모두 이 요청을 받게 되지만, 호스트 B만이 자기의 IP 주소를 인식하고 자기의 물리적 네트워크 주소가 포함된 메시지를 다시 A로 보내주게 된다. A가 이 메시지를 받으면, A는 이 물리적 네트워크 주소를 이용하여 인터넷 패킷을 B에게 직접 보내주게 된다. 한번 연결된 후에는 캐시를 사용 하여 이 정보를 저장해 두어 다시 ARP를 사용할 필요가 없게 해준다. 
그림 6. ARP 프로토콜 ARP 메시지는 물리적인 프레임을 통해서 전송되어져야한다. 그림 7은 프레임의 데이터부분에 캡슐화되어 전송되는 ARP 메시지를 보여준다. 
그림 7. ARP 캡슐화 그림 8은 ARP 메시지의 형식을 보여준다. 
그림 8. ARP 메시지 형식 HARDWARE TYTE 필드는 하드웨어 인터페이스 형식을 나타내고, 만일 이더넷일 경우 1로 설정된다. PROTOCOL TYPE은 송신자에게 적용되는 상위 수준의 프로토콜 형식을 나타내며, IP 주소는 080016 으로 설정된다. OPERATION 필드는 ARP 요청(1), ARP 응답(2), RARP 요청(3), RARP 응답 (4) 중 하나로 설정된다. HLEN과 PLEN 필 드는 각각 하드웨어 주소 길이와 소프트웨어 주소 길이를 나타낸다. 마지막으로 SENDER HA, SENDER IP 필드는 송신 호스트의 하드웨어 주소와 소프트웨어 주소를, TARGET HA, TARGET IP 필드는 찾고자 하는 호스트의 하드웨어와 소프트웨어의 주소를 나타낸다. 3.2 RARP 디스크를 가지고 있지 않은 호스트가 자신의 IP 주소를 서버로부터 얻어내기 위해서는 RARP (Reverse Address Resolution Protocol)라는 TCP/IP 인터넷 프로토콜을 사용해야한다. RARP는 ARP 프로토콜로부터 적용된 것이고 그림 8에 나와있는 ARP의 형식을 같이 사용한다. ARP 메시지와 같이 RARP 메시지는 네트워크 프레임의 데이터 부분에 캡슐화되어 한 호스트에서 다른 호스트로 전송된다. 그림 9는 RARP의 동작원리를 보여준다. 송신 호스트는 자신을 송신과 수신 호스트로 정의한 RARP 메시지를 브로드캐스트한다. 네트워크상의 모든 호스트들이 이 요청을 받지만, RARP 서비스를 지원하도록 허가받은 호스 트들만이 이 요청을 수행하고, 그 답신을 보낸다. 이런 호스트들은 RARP 서버로서 네트워크상의 호스트들에게 알려지게 된 다. RARP가 성공적으로 수행되기 위해서, 네트워크는 적어도 하나의 RARP 서버를 포함해야 한다. 
그림 9. RARP 프로토콜 4. IP(Internet Protocol) 4.1 개요 신뢰성이 보장되지 않는 비연결 전송(connectionless) 구조로 정의된 프로토콜을 인터넷 프로토콜이라 부르며 약어로 IP라고 나타낸다. IP 프로토콜은 TCP/IP 인터넷을 통한 전송에 사용되는 데이터의 기본단위를 정의한다. IP는 데이터가 보내질 경로를 고르는 라우팅 기능을 수행한다. 물리적 네트워크와 TCP/IP 인터넷 사이에는 유사한 점이 많다. 물리적 네트워크에서 전송단위는 헤더와 데이터부분을 가지고 있는 하나의 프레임이다. 인터넷에서 사용되는 데이터 전송단위를 인터넷 데이터그램이라고 부르며, IP 데이터그램 혹은 데이터그램이라고도 부른다. 물리적 네트워크의 프레임과 같이 데이터그램은 헤더와 데이터부분으로 나뉜 다. 또, 데이터그램 헤더는 송신지와 목적지 주소, 그리고 데이터그램의 내용을 나타내는 형식 필 드를 가진다. 데이터그램 헤더와 프레임 헤더의 차이는 전자는 IP 주소 정보를 가지고 있고, 후자는 물리적 네트워크 주소를 갖는다는 점이다. 4.2 데이터그램 형식 그림 10은 인터넷 데이터그램의 형식을 나타낸다. 
그림 10. IP 데이터그램 형식 VERS 필드는 IP 프로토콜의 버젼(현재는 4)을 나타내고, HLEN 필드는 헤더의 길이는 나타내는 필드이다. IP OPTION 필드와 PADDING 필드를 제외한 헤더안의 모든 필드는 고정된 길이를 갖는다. TOTAL LENGTH 필드는 옥텟으로 계산된 IP 데이터그램의 전체 길이를 나타낸다. 일반적으로 Type Of Service(TOS)라고 불리우는 8비트의 SERVICE TYPE 필드는 어떻게 데이터그램이 처리될 것인가를 나타내고 다시 5개의 부 필드로 나뉘어 그 사항을 구체적으로 나타낸다. IP 데이터그램은 물리적 네트워크 프레임에 캡슐화되어 전송된다. 물리적 네트워크상에서 실제로 전송될 수 있는 한 프레임의 최대 길이를 그 네트워크의 최대 전송단위 혹은 MTU라고 한다. 각 물리적 네트워크가 서로 다른 MTU를 가지고 있기 때문에 큰 데이터그램은 MTU가 가장 작은 네트워크에 맞추어 나누어 서 전송해야할 필요가 있다. 이 나누어진 데이터그램을 프레그멘트라고 하고, 이 프레그멘트를 처리 하는 것을 프레그멘테이션이라고 한다. 프레그멘트들은 각각 프레그멘트 헤더를 가지고있고 이 헤더의 FLAG 필드와 FRAGMENT OFFSET 필드로서 이 데이터그램이 프레그멘트라는 것과 오프셋주소를 알려준다. IDENTIFICATION 필드는 이 나누어진 프레그멘트들이 하나의 데이터그램이라는 것을 나타내고 후에 프레그멘트들을 재 조합 할 때 사용된다. TIME TO LIVE(TTL) 필드는 이 데이터그램이 얼마동안 인터넷 시스템안에서 머물 수 있는가를 나타낸다. PROTOCOL 필드는 어떤 상위 수준의 프로토콜이 사용되었는가를 나타내고 HEADER CHECKSUM 필드는 헤더값의 무결성을 보장하기위해 쓰인다. SOURCE IP ADDRESS와 DESTINATION IP ADDRESS 필드는 각각 송신 호스트와 수신 호스트의 IP 주소를 나타낸다. DATA 필드는 데이터그램내의 데이터부분의 시작지점을 알려준다. OPTION 필드와 PADDING 필드는 네트워크 테스팅이나 디버깅을 위해 쓰인다. 4.3 인터넷 상에서의 라우팅 하나의 물리적인 네트워크 안에 있는 호스트들사이에서의 IP 데이터그램 전송은 라우터를 사용하지 않고 직접 수행된다. 송신 호스트는 물리적 프레임내에 데이터그램을 캡슐화시키고 목적지 IP 주소를 물리적 하드웨어 주소와 대응시킨 뒤 목적지로 프레임을 직접 전송한다. 서로 다른 물리적 네트워크를 통한 전송은 라우터를 사용하게 된다. TCP/IP 인터넷안에서의 라우터들은 서로 연결된 구조를 가지고 있다. 데이터그램은 이를 직접 목적지 호스트에 전송할 수 있는 라우터에 도달할 때까지 라우터에서 라우터로 전송된다. 각각의 라우터는 라우팅 테이블을 가지고 있어 이 테이블안의 정보를 가지고 데이터그램 전송을 하게된다. 4.4 ICMP(Internet Control Message Protocol) 인터넷상의 라우터들이 전송상의 에러나 예상치않은 사건들을 보고하게 할 목적으로 만들어진 프로토콜을 Internet Control Message Protocol(ICMP)라고 한다. 다른 모든 전송과 같이, ICMP 메시지는 IP 데이터그램의 데이터부분에 실려 인터넷을 통해 전송된다. 그림 7은 ICMP 캡슐화를 보여준다. 각각의 ICMP 메시지는 자기의 고유한 형식을 가지고 있지만, 처음 세 필드는 모두 동일하다. 8비트 정수 메시지인 TYPE 필드는 이 메시지의 종류를 정의하고 8비트 CODE 필드는 메시지 형식에 대한 추가적인 정보를 보여준 다. 그리고 ICMP 메시지에만 적용되는 16비트의 CHECKSUM 필드가 있다. ICMP TYPE이 정 의하는 메시지종류는 표 1과 같다. 타입필드 | ICMP 메시지 타입 | 0 | 반복 응답 | 3 | 목적지 도달 불가능 | 4 | 소스 손실 | 5 | 경로 변경 | 8 | 반복 요청 | 11 | 데이터그램 시간초과 | 12 | 매개변수 문제발생 | 13 | 타임 스템프 요청 | 14 | 타임 스템프 응답 | 15 | 정보 요청(사라짐) | 16 | 정보 응답(사라짐) | 17 | 주소 매스크 요청 | 18 | 주소 매스크 응답 |
표 1. ICMP 메시지 타입
5. UDP(User Datagram Protocol)와 TCP(Transmission Control Protocol) 5.1 UDP의 개요 TCP/IP 환경에서 User Datagram Protocol(UDP)는 한 응용프로그램에서 다른 응용프로그램으로 데이터그램을 전송하는 기본적인 메카니즘을 제공한다. 또한, UDP는 한 호스트안에서 돌아가는 응용프로그램들을 구분하는데 쓰이 는 프로토콜 포트를 제공한다. 이는 한 호스트안의 응용프로그램이 다른 호스트안의 특정 응용프로그램에 데이터를 전송할 수 있게 해준다. UDP는 신뢰성이 보장되지 않고(unreliable) 비연결인 데이터그램 전송 구조를 제공한다. 따라서, UDP 메시지는 손실될 수 있고, 중복될 수도 있으며, 순서가 뒤바뀌어 도착할 수도 있다. 그리고 패킷들이 수신자가 처리할 수 있는 양보다 더 빨리 도착할 수 도 있다. 5.2 UDP 메시지 형식 각각의 UDP 메시지는 유저 데이터그램이라고 불리운다. 개념적으로 하나의 유저 데이터그램은 UDP 헤더와 UDP 데이터부분 두가지로 구성된다. 그림 11에서 보듯이, 헤더는 메시지가 보내진 포트, 메시지의 목적 포트, 메시지 길이, 그리고 UDP 체크섬을 가리키는 4개의 16비트 필드로 나뉜다. 
그림 11. ICMP 메시지 타입 5.3 TCP의 개요 TCP/IP 인터넷 프로토콜에 의해 제공되는 신뢰성이 보장되는 데이터전송서비스를 Transmission Control Protocol 또는 TCP라고 한다. 이 프로토콜은 신뢰성 있는 전송을 수행하기위해 두 호스트가 교환하는 데이터와 승인 메시지의 형식을 정의한다. 또, 어떻게 TCP 소프트웨어가 주어진 호스트의 여러 가지 목적지 가 운데서 하나를 구별해 내며, 어떻게 전송 에러를 복구할 것인가를 정의한다. 또한 이 프로토콜은 두 호스트가 어떻게 TCP 흐름 전송을 초기화하고 이 초기화가 이루어졌을 때 두 호스트가 어떻게 서로 승인하는지를 보여준다. 5.4 TCP 계층화 UDP와 같이, TCP도 프로토콜 계층화 구조에서 IP위에 놓이게 된다. 그림 12은 이 개념적인 구 조를 나타낸다. 
그림 12. 프로토콜 계층화 구조 5.5 TCP 세그멘트 형식 두 호스트사이에서 TCP 소프트웨어를 통해 전송되는 단위를 세그멘트라고 부른다. 세그멘트들은 연결을 시키거나, 데이터를 보내거나, 승인메세지를 보내거나, 원도우 사이즈를 알리거나, 또는 연결을 끊을 때 양쪽 호스트들 사이에서 서로 교환된다. 그림 13은 TCP 세그멘트 형식을 보여준다. 
그림 13. TCP 세그멘트 형식 SOURCE PORT와 DESTINATION 필드는 송신, 수신 호스트의 응용프로그램에 의해 정의되는 TCP 포트 번호를 가진다. SEQUENCE NUMBER 필드는 세그멘트안 데이터의 송신 바이트 흐름(stream)의 위치를 가리킨다. ACKNOWLEDGMENT NUMBER 필드는 소스가 다음에 받을 것으로 예상되는 옥텟의 수를 나 타낸다. HLEN 필드는 세그멘트의 길이를 정의하는 정수를 가지고 있다. RESERVED 필드는 차후에 사용되어지기위해 예약된 필드이다. 6비트의 CODE BITS 필드는 세그멘트의 용도와 내용을 결 정하기 위해 쓰인다. 이 필드가 URG로 설정되어있을때는 URGENT POINTER 필드가 설정된다.
5.6 TCP 연결 설정및 종료 연결을 설정하거나 종료위해서 TCP는 세 방향 핸드쉐이킹을 사용한다. 가장 간단한 경우, 연결설 정 핸드쉐이킹은 그림 14과 같이 처리된다. 
그림 14. 세 방향 핸드쉐이킹(3 way Hand Shaking) 핸드쉐이킹의 첫 번째 세그멘트는 코드 필드안에 SYN(synchronization) 비트를 설정함으로서 정의된다. 두 번째 메시지는 핸드쉐이킹을 계속하고 있다는 것 뿐만아니라 첫 번째 SYN 세그멘트에 대한 응답이라는 것을 나타내는 SYN 비트와 ACK 비트 집합 모두를 가진다. 첫 번째 헨드쉐이킹 메시지는 두 사이트가 모두 동의했고 연결이 이미 만들어졌다는 것을 알려준다. 연결을 종료할 시에는 SYN 비트대신 FIN 비트를 설정하여 응용프로그램과 종료 메시지를 주고 받는다. 기본적인 구조는 그림 15와 같다. 
그림 15. 연결 종료를 위한 수정된 세 방향 헨드쉐이킹 6. 라우팅 프로토콜 인터넷에서 사용되는 라우팅 프로토콜은 다음과 같다. o GGP(Gateway-to-Gateway Protocol) : 네트워크상의 핵심 라우터들은 Gateway-to-Gateway Protocol(GGP)라고 알려진 벡터 간격 프로토콜을 사용한다. GGP는 더 이상 TCP/IP 구조의 중요한 부분이 아니지만, 이것은 벡터 간격(vector-distance) 라우팅의 한 예를 제공한다. GGP는 UDP 데이터그램들이나 TCP 세그멘트들과 비슷하게 IP 데이터그램들을 통해 사용되도록 설계되었다. 각각의 GGP 메시지는 메시지와 남아있는 필드의 형식을 나타내는 고정된 형식 헤더를 가지고 있다. o EGP(Exterior Gateway Protocol) : 라우팅 정보를 교환하는 두 라우터들은 만약 두 개의 서로 다른 독립적인 시스템들에 속해있다면 외부 이웃들이라고 불리우고 같은 독립적인 시스템 안에 있다면 내부 이웃들이라고 불린다. 도달 가능 정보를 다른 시스템에게 알려주는 프로토콜을 Exterior Gateway Protocol또는 EGP라고 하고 여기에 쓰이는 라우터들을 외부 라우터라고 한다. 연결된 인터넷 안에서, 각각의 독립적인 시스템들이 핵심 시스템에게 도 달 가능정보를 보내는 경우에 EGP를 사용한다. NSFNET안에 서는 EGP와 비슷한 프로토콜인 BGP(Border Gateway Protocol)가 사용된다. o RIP(Routing Information Protocol) : 가장 널리 쓰이는 내부 게이트웨이 프로토콜은 Routing Information Protocol(RIP)이다 . RIP는 RIP를 구현시키는 프로그램 이름인 routed로도 부른다. routed 소프트웨어는 버클리에 있는 캘리포니아 대학에서 개발되었고, 자신이 속해있는 지역 네트워크상의 호스트들 사이에서 일관성있는 라우팅과 도달가능 정보를 제공해준다. 라우팅 교환을 빠르게 하기위해 RIP는 물리적 네트워크 브로드캐스트를 사용한다. ※ 현재는 RIP보다 OSPF를 더 맣이 사용하고 있음 o OSPF(Open Shortest Path First protocol) : IETF(Internet Engineering Task Force)에서는 SPF(Shortest Path First) 알고리즘을 사용한 내부 게이트웨이 프로토콜을 설계했다. Open SPF(OSPF)라고 불리는 이 프로토콜은 여러 가지 목적을 가지고 개발되었다. 로드 밸런싱을 지원한다거나 서비스 형태 라우팅을 포함하거나 하여 효율적인 라우팅을 지원해준다. 가장 많은 기능을 제공해 주는 프로토콜이지만 설치와 운용이 복잡하다.
7. IP의 미래 : IPv6(Internet Protocol version 6) 7.1 개요 계속되는 인터넷 호스트들의 폭발적인 증가와 여러 가지 추가로 요구되는 기능들(멀티미디어 지원등)에 대한 지원문제를 해결하기 위해서 IPv4의 새로은 버전으로 IPv6가 태어났다. 이 프로 토콜은 인터넷 환경속에서 보통의 소프트웨어 업그레이드와 같이 인스톨 될 수 있으며, 현재의 IPv4와도 상호운용이 가능하다. 낮은 전송 속도를 가지는 네트워크 뿐만 아니라, ATM같이 높은 효율성을 가진 네트워크들에서도 잘 돌아가도록 이 프로토콜은 설계되었다. 여기에 덧붙여서, 가까운 미래에 요구될 새로운 인터넷 기술들에 대한 기반을 제공한다. IPv6는 IPv4의 여러 가지 문제들을 해결하고 여러 가지 성능향상을 추가했다. 인터넷이 확장 하면서 생기는 문제를 해결하고, 유동적인 전송 매카니즘을 제공하여 구조상의 문제점으로 인해 발생할 수 있는 여러 가지 위험들을 줄이고자 하였다.
7.2 IPv6 형식 IPv6 프로토콜은 기본적인 IPv6 헤더와 IPv6 확장헤더로 나뉜다. 그림 16는 기본적인 IPv6 헤 더 형식을 보여준다. 
그림 16. IPv6 헤더 형식 각각의 필드는 다음과 같이 구성되어 있다. Version : 4비트 인터넷 프로토콜 버전 번호, 6으로 설정되어 있다. Prio : 4비트 우선순위 값 Flow Label : 24비트 필드, QoS와 관계가 있다. Payload Length : 16비트의 무부호 정수. 내용물의 길이를 나타냄. Next Header : 8비트의 선택기. IPv6 헤더에 계속해서 오는 헤더의 형태를 구분한다. Hop Limit : 8비트의 무부호 정수. 패킷이 각각의 노드를 지날때마다 1씩 감소한다. Source Address : 128비트. 패킷을 보내는 초기 송신 호스트의 주소. Destination Address : 128비트. 패킷의 수신 호스트의 주소.
IPv6는 분리된 확장 헤더를 두어 향상된 옵션 매카니즘을 제공한다. 이 확장 헤더를 통해 인증 또는 암호화 등의 옵션을 줄 수 있다. IPv6 주소는 128비트의 길이로 되어있고 개개의 인터페이스와 인터페이스 집합을 정의해준다. IP 주소의 형태는 유니캐스트, 애 니캐스트, 멀티캐스트의 3종류로 나뉜다. 유니캐스트 주소는 단일 인터페이스를 정의한다. 애니캐스트 주소는 패킷이 애니캐스트 주소로 보내졌을 때 그 집합의 하나의 일원에게만 전송될 인터페이스 집합을 정의한다. 멀티캐스트 주소는 패킷이 멀티캐스트 주소로 보내졌을 때 그 그룹안에 있는 모든 인터페이스들에게 전송될 인터페이스 그룹을 정의한다. IPv6의 멀티캐스트 주소는 IPv4의 브로드캐스트 주소를 대신한다. IPv6 변환 기술에서 사용되는 두가지 특별한 유니캐스트 주소가 있는데 하나는 IPv6와 IPv4 모두 호환가능한 호스트라는것을 나타내는 IPv6 호환 주소이고, 다른 하나는 IPv4만 호환가능한 호스트라는 것을 보여주는 IPv6에 대응 된 IPv4 주소이다. 각각 뒤 32비트 부분에 IPv4주소를 포함하고 있다. 그림 17은 이 두가지 주소형식을 보여준다. 
그림 17. IPv4 호환 IPv6 주소 형식
7.3 IPv6 변환 매카니즘 현재 구현되어 있는 IPv4의 구조를 건드리지 않고 IPv4와 IPv6를 상호 운용하는 방법에는 다음 두 가지가 있다. o 호스트와 라우터에서의 이중 IP 계층화 : 네임 서버들과 라우터들은 변환 기간동안 IPv4와 IPv6 모두를 지원한다. 이 방법은 업그레이드된 노드들이 자신의 기본적인 프로토콜을 사용하면서 IPv4와 IPv6 노드들과 상호운용 이 가능하도록 만들어준다. 이중 호스트들은 IPv4를 사용하여 IPv4 호스트들과 통신하고, IPv6를 사 용하여 IPv6 호스트들과 통신한다. IPv4와 IPv6 모두에 적용되기위해 확장된 DNS(Domain Name Service)를 사용하여야 한다. 이중 IP 네트워크의 구조는 그림 18과 같다.

그림 18. 이중 IP 네트워크 o IPv4 위에서의 IPv6 터널링 : 호스트들 (그리고 경우에따라 라우터들도) 캡슐화 방법으로 IPv4 라우팅 기술을 통해 IPv6 전송 을 행할 수 있다. 이 기술은 기존에 설치된 IPv4 라우팅 시스템을 건드리지 않고 IPv6 작업 수행 을 가능케한다는 장점이 있다. IPv4 라우팅 내부 구조상에서 IPv6 전송을 할 수 있도록 하기위해 터 널링이라는 기법을 사용한다. IPv6/IPv4 겸용 호스트들이나 라우터들은 IPv4 패킷에 IPv6 데이터그램을 캡슐화시켜 IPv4 지역을 통과하게 하기위해서 가상 터널을 만든다. 그림 19에는 IPv4에 IPv6를 캡슐화하는 예제가 나와있다.

그림 19. IPv6 캡슐화 터널링방법에는 두가지가 있는데 하나는 구성화된(configured) 터널링 방법이고, 다른 하나는 자 동화된(automatic) 터널링 방법이다. 구성화된 터널링 방법은 IPv4 네트워크상에 떨어져있는 두 개의 IPv6/IPV4 노드(일반적으로 라우터)들 사이에 가상적인 터널 연결을 만드는 전형적인 터널링 방법이다. 각각의 터널 연결은 한쪽이나 양쪽의 터널 종단지점의 IP 주소를 수동적으로 지정해주므로써 설정된다(그림 20). 
그림 20. 구성화된 터널링 자동화된 터널링은 구성화된 터널링과 같은 기반 메카니즘을 사용하지만, 각각의 터널을 개별로 설정해 주어야할 필요를 없앴다. IPv4 주소가 실려있는 IPv4 호환 주소를 사용하여 전송하고자 하는 IPv4 호스트까지 직접 전송해준다. 자동화된 터널링은 일반적으로 라우터가 아니라 호스트에게 패킷을 전송하는데 에 쓰인다(그림 21). 
그림 21. 자동화된 터널링 8. 결론 지금까지 TCP/IP 프로토콜의 전체적인 구조와 그 동작원리, 그리고 앞으로 발전되어 나갈 모습 에 대해 간략하게 소개했다. TCP/IP는 인터넷같은 커다란 네트워크의 집합들에 사용되기 위해 만들어져왔고 또 그동안 실제 로 다른 프로토콜보다 뛰어난 효율성과 안정성을 보이며 사용되어져왔다. 최근들어 인터넷 호 스트 수가 증가함에따라 기존의 TCP/IP 프로토콜로서는 이를 수용할 수 없게 되자 IPNG(Internet Protocol Next Generation)같은 계획을 통해 이를 보완하고 있다. 인터넷이나 TCP/IP 프로토콜 모두 고정적이지는 않다. 세계의 여러 가지 연구기관들에서 이 기 술들을 확장하고 발전시켜나가려는 노력을 계속하고 있다. 앞으로도 TCP/IP기술은 인터넷의 확장과 더불어 계속 발전해 나갈 것이 다.
|