 블로그 > ♤우리집♤ 블로그 > ♤우리집♤ http://blog.naver.com/535v/140010604504 http://blog.naver.com/535v/140010604504 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
'분류 전체보기'에 해당되는 글 150건
- 2006.08.07 후니의 쉽게쓴... 중에서 라우터 부분.
- 2006.08.07 보안의 10대 불변 법칙
- 2006.08.07 미들웨어(Middle Ware)란 무엇인가
- 2006.08.07 서버 모니터링 툴의 강자, RRDtool 가이드
- 2006.08.07 TTL 값을 이용한 OS 판별하기
- 2006.08.07 침입 탐지 시스템(IDS)
- 2006.08.06 클러스터
- 2006.08.06 인터넷 보안과 방화벽 개론
- 2006.08.06 EJB는 언제 사용해야 하는가?
- 2006.08.06 EJB 는 왜 필요할까요?
10 Immutable Laws of Security
Here at the Microsoft Security Response Center, we investigate thousands of security reports every year. In some cases, we find that a report describes a bona fide security vulnerability resulting from a flaw in one of our products; when this happens, we develop a patch as quickly as possible to correct the error. (See "A Tour of the Microsoft Security Response Center"). In other cases, the reported problems simply result from a mistake someone made in using the product. But many fall in between. They discuss real security problems, but the problems don't result from product flaws. Over the years, we've developed a list of issues like these, that we call the 10 Immutable Laws of Security.
Don't hold your breath waiting for a patch that will protect you from the issues we'll discuss below. It isn't possible for Microsoft—or any software vendor—to "fix" them, because they result from the way computers work. But don't abandon all hope yet—sound judgment is the key to protecting yourself against these issues, and if you keep them in mind, you can significantly improve the security of your systems.
On This Page
Law #1: If a bad guy can persuade you to run his program on your computer, it's not your computer anymore (어떤 사람이 당신에게 준 소프트웨어를 실행했다면, 그 컴퓨터는 더 이상 당신의 것이 아니다.)
Law #2: If a bad guy can alter the operating system on your computer, it's not your computer anymore
(어떤 사람이 당신 컴퓨터의 운영체제를 변경할 수 있다면, 그 컴퓨터는 더 이상 당신의 것이 아니다.)
Law #3: If a bad guy has unrestricted physical access to your computer, it's not your computer anymore
(어떤 사람이 당신의 컴퓨터에 물리적으로 접근할 수 있다면, 그 컴퓨터는 더 이상 당신의 것이 아니다.)
Law #4: If you allow a bad guy to upload programs to your website, it's not your website any more
(어떤 사람이 당신의 웹 사이트에 프로그램을 업로드할 수 있다면, 그 웹 사이트는 더 이상 당신의 것이 아니다.)
Law #5: Weak passwords trump strong security
(어떤 철통 같은 보안도 비밀번호가 노출되면 소용없는 일이다.)
Law #6: A computer is only as secure as the administrator is trustworthy
(관리자가 얼마나 믿을만한가에 따라서 기계의 보안 수준이 달라진다.)
Law #7: Encrypted data is only as secure as the decryption key
(암호화된 데이터는 복호화 키만큼만 안전하다.)
Law #8: An out of date virus scanner is only marginally better than no virus scanner at all
(오래된 바이러스 백신을 사용하는 것은 바이러스 백신을 사용하지 않는 것과 거의 차이가 없다.)
Law #9: Absolute anonymity isn't practical, in real life or on the Web
(완벽한 익명성 보장은 없다. 실생활에서도 그렇고 웹에서도 그렇다.)
Law #10: Technology is not a panacea
(기술은 만병통치약이 아니다.)
Law #1: If a bad guy can persuade you to run his program on your computer, it's not your computer anymore
It's an unfortunate fact of computer science: when a computer program runs, it will do what it's programmed to do, even if it's programmed to be harmful. When you choose to run a program, you are making a decision to turn over control of your computer to it. Once a program is running, it can do anything, up to the limits of what you yourself can do on the computer. It could monitor your keystrokes and send them to a website. It could open every document on the computer, and change the word "will" to "won't" in all of them. It could send rude emails to all your friends. It could install a virus. It could create a "back door" that lets someone remotely control your computer. It could dial up an ISP in Katmandu. Or it could just reformat your hard drive.
That's why it's important to never run, or even download, a program from an untrusted source—and by "source," I mean the person who wrote it, not the person who gave it to you. There's a nice analogy between running a program and eating a sandwich. If a stranger walked up to you and handed you a sandwich, would you eat it? Probably not. How about if your best friend gave you a sandwich? Maybe you would, maybe you wouldn't—it depends on whether she made it or found it lying in the street. Apply the same critical thought to a program that you would to a sandwich, and you'll usually be safe.
Top of page
Law #2: If a bad guy can alter the operating system on your computer, it's not your computer anymore
In the end, an operating system is just a series of ones and zeroes that, when interpreted by the processor, cause the computer to do certain things. Change the ones and zeroes, and it will do something different. Where are the ones and zeroes stored? Why, on the computer, right along with everything else! They're just files, and if other people who use the computer are permitted to change those files, it's "game over".
To understand why, consider that operating system files are among the most trusted ones on the computer, and they generally run with system-level privileges. That is, they can do absolutely anything. Among other things, they're trusted to manage user accounts, handle password changes, and enforce the rules governing who can do what on the computer. If a bad guy can change them, the now-untrustworthy files will do his bidding, and there's no limit to what he can do. He can steal passwords, make himself an administrator on the computer, or add entirely new functions to the operating system. To prevent this type of attack, make sure that the system files (and the registry, for that matter) are well protected. (The security checklists on the Microsoft Security website will help you do this).
Top of page
Law #3: If a bad guy has unrestricted physical access to your computer, it's not your computer anymore
Oh, the things a bad guy can do if he can lay his hands on your computer! Here's a sampling, going from Stone Age to Space Age:
• He could mount the ultimate low-tech denial of service attack, and smash your computer with a sledgehammer.
• He could unplug the computer, haul it out of your building, and hold it for ransom.
• He could boot the computer from a floppy disk, and reformat your hard drive. But wait, you say, I've configured the BIOS on my computer to prompt for a password when I turn the power on. No problem – if he can open the case and get his hands on the system hardware, he could just replace the BIOS chips. (Actually, there are even easier ways).
• He could remove the hard drive from your computer, install it into his computer, and read it.
• He could make a duplicate of your hard drive and take it back his lair. Once there, he'd have all the time in the world to conduct brute-force attacks, such as trying every possible logon password. Programs are available to automate this and, given enough time, it's almost certain that he would succeed. Once that happens, Laws #1 and #2 above apply.
• He could replace your keyboard with one that contains a radio transmitter. He could then monitor everything you type, including your password.
Always make sure that a computer is physically protected in a way that's consistent with its value—and remember that the value of a computer includes not only the value of the hardware itself, but the value of the data on it, and the value of the access to your network that a bad guy could gain. At a minimum, business-critical computers like domain controllers, database servers, and print/file servers should always be in a locked room that only people charged with administration and maintenance can access. But you may want to consider protecting other computers as well, and potentially using additional protective measures.
If you travel with a laptop, it's absolutely critical that you protect it. The same features that make laptops great to travel with – small size, light weight, and so forth—also make them easy to steal. There are a variety of locks and alarms available for laptops, and some models let you remove the hard drive and carry it with you. You also can use features like the Encrypting File System in Microsoft Windows® 2000 to mitigate the damage if someone succeeded in stealing the computer. But the only way you can know with 100% certainty that your data is safe and the hardware hasn't been tampered with is to keep the laptop on your person at all times while traveling.
Top of page
Law #4: If you allow a bad guy to upload programs to your website, it's not your website any more
This is basically Law #1 in reverse. In that scenario, the bad guy tricks his victim into downloading a harmful program onto his computer and running it. In this one, the bad guy uploads a harmful program to a computer and runs it himself. Although this scenario is a danger anytime you allow strangers to connect to your computer, websites are involved in the overwhelming majority of these cases. Many people who operate websites are too hospitable for their own good, and allow visitors to upload programs to the site and run them. As we've seen above, unpleasant things can happen if a bad guy's program can run on your computer.
If you run a website, you need to limit what visitors can do. You should only allow a program on your site if you wrote it yourself, or if you trust the developer who wrote it. But that may not be enough. If your website is one of several hosted on a shared server, you need to be extra careful. If a bad guy can compromise one of the other sites on the server, it's possible he could extend his control to the server itself, in which he could control all of the sites on it—including yours. If you're on a shared server, it's important to find out what the server administrator's policies are. (By the way, before opening your site to the public, make sure you've followed the security checklists for IIS 4.0 and IIS 5.0).
Top of page
Law #5: Weak passwords trump strong security
The purpose of having a logon process is to establish who you are. Once the operating system knows who you are, it can grant or deny requests for system resources appropriately. If a bad guy learns your password, he can log on as you. In fact, as far as the operating system is concerned, he is you. Whatever you can do on the system, he can do as well, because he's you. Maybe he wants to read sensitive information you've stored on your computer, like your e-mail. Maybe you have more privileges on the network than he does, and being you will let him do things he normally couldn't. Or maybe he just wants to do something malicious and blame it on you. In any case, it's worth protecting your credentials.
Always use a password—it's amazing how many accounts have blank passwords. And choose a complex one. Don't use your dog's name, your anniversary date, or the name of the local football team. And don't use the word "password"! Pick a password that has a mix of upper- and lower-case letters, number, punctuation marks, and so forth. Make it as long as possible. And change it often. Once you've picked a strong password, handle it appropriately. Don't write it down. If you absolutely must write it down, at the very least keep it in a safe or a locked drawer—the first thing a bad guy who's hunting for passwords will do is check for a yellow sticky note on the side of your screen, or in the top desk drawer. Don't tell anyone what your password is. Remember what Ben Franklin said: two people can keep a secret, but only if one of them is dead.
Finally, consider using something stronger than passwords to identify yourself to the system. Windows 2000, for instance, supports the use of smart cards, which significantly strengthens the identity checking the system can perform. You may also want to consider biometric products like fingerprint and retina scanners.
Top of page
Law #6: A computer is only as secure as the administrator is trustworthy
Every computer must have an administrator: someone who can install software, configure the operating system, add and manage user accounts, establish security policies, and handle all the other management tasks associated with keeping a computer up and running. By definition, these tasks require that he have control over the computer. This puts the administrator in a position of unequalled power. An untrustworthy administrator can negate every other security measure you've taken. He can change the permissions on the computer, modify the system security policies, install malicious software, add bogus users, or do any of a million other things. He can subvert virtually any protective measure in the operating system, because he controls it. Worst of all, he can cover his tracks. If you have an untrustworthy administrator, you have absolutely no security.
When hiring a system administrator, recognize the position of trust that administrators occupy, and only hire people who warrant that trust. Call his references, and ask them about his previous work record, especially with regard to any security incidents at previous employers. If appropriate for your organization, you may also consider taking a step that banks and other security-conscious companies do, and require that your administrators pass a complete background check at hiring time, and at periodic intervals afterward. Whatever criteria you select, apply them across the board. Don't give anyone administrative privileges on your network unless they've been vetted – and this includes temporary employees and contractors, too.
Next, take steps to help keep honest people honest. Use sign-in/sign-out sheets to track who's been in the server room. (You do have a server room with a locked door, right? If not, re-read Law #3). Implement a "two person" rule when installing or upgrading software. Diversify management tasks as much as possible, as a way of minimizing how much power any one administrator has. Also, don't use the Administrator account—instead, give each administrator a separate account with administrative privileges, so you can tell who's doing what. Finally, consider taking steps to make it more difficult for a rogue administrator to cover his tracks. For instance, store audit data on write-only media, or house System A's audit data on System B, and make sure that the two systems have different administrators. The more accountable your administrators are, the less likely you are to have problems.
Top of page
Law #7: Encrypted data is only as secure as the decryption key
Suppose you installed the biggest, strongest, most secure lock in the world on your front door, but you put the key under the front door mat. It wouldn't really matter how strong the lock is, would it? The critical factor would be the poor way the key was protected, because if a burglar could find it, he'd have everything he needed to open the lock. Encrypted data works the same way—no matter how strong the crypto algorithm is, the data is only as safe as the key that can decrypt it.
Many operating systems and cryptographic software products give you an option to store cryptographic keys on the computer. The advantage is convenience – you don't have to handle the key – but it comes at the cost of security. The keys are usually obfuscated (that is, hidden), and some of the obfuscation methods are quite good. But in the end, no matter how well-hidden the key is, if it's on the computer it can be found. It has to be – after all, the software can find it, so a sufficiently-motivated bad guy could find it, too. Whenever possible, use offline storage for keys. If the key is a word or phrase, memorize it. If not, export it to a floppy disk, make a backup copy, and store the copies in separate, secure locations. (All of you administrators out there who are using Syskey in "local storage" mode—you're going to reconfigure your server right this minute, right?)
Top of page
Law #8: An out of date virus scanner is only marginally better than no virus scanner at all
Virus scanners work by comparing the data on your computer against a collection of virus "signatures". Each signature is characteristic of a particular virus, and when the scanner finds data in a file, email, or elsewhere that matches the signature, it concludes that it's found a virus. However, a virus scanner can only scan for the viruses it knows about. It's vital that you keep your virus scanner's signature file up to date, as new viruses are created every day.
The problem actually goes a bit deeper than this, though. Typically, a new virus will do the greatest amount of damage during the early stages of its life, precisely because few people will be able to detect it. Once word gets around that a new virus is on the loose and people update their virus signatures, the spread of the virus falls off drastically. The key is to get ahead of the curve, and have updated signature files on your computer before the virus hits.
Virtually every maker of anti-virus software provides a way to get free updated signature files from their website. In fact, many have "push" services, in which they'll send notification every time a new signature file is released. Use these services. Also, keep the virus scanner itself—that is, the scanning software—updated as well. Virus writers periodically develop new techniques that require that the scanners change how they do their work.
Top of page
Law #9: Absolute anonymity isn't practical, in real life or on the Web
All human interaction involves exchanging data of some kind. If someone weaves enough of that data together, they can identify you. Think about all the information that a person can glean in just a short conversation with you. In one glance, they can gauge your height, weight, and approximate age. Your accent will probably tell them what country you're from, and may even tell them what region of the country. If you talk about anything other than the weather, you'll probably tell them something about your family, your interests, where you live, and what you do for a living. It doesn't take long for someone to collect enough information to figure out who you are. If you crave absolute anonymity, your best bet is to live in a cave and shun all human contact.
The same thing is true of the Internet. If you visit a website, the owner can, if he's sufficiently motivated, find out who you are. After all, the ones and zeroes that make up the Web session have to be able to find their way to the right place, and that place is your computer. There are a lot of measures you can take to disguise the bits, and the more of them you use, the more thoroughly the bits will be disguised. For instance, you could use network address translation to mask your actual IP address, subscribe to an anonymizing service that launders the bits by relaying them from one end of the ether to the other, use a different ISP account for different purposes, surf certain sites only from public kiosks, and so on. All of these make it more difficult to determine who you are, but none of them make it impossible. Do you know for certain who operates the anonymizing service? Maybe it's the same person who owns the website you just visited! Or what about that innocuous website you visited yesterday, that offered to mail you a free $10 off coupon? Maybe the owner is willing to share information with other website owners. If so, the second website owner may be able to correlate the information from the two sites and determine who you are.
Does this mean that privacy on the Web is a lost cause? Not at all. What it means is that the best way to protect your privacy on the Internet is the same as the way you protect your privacy in normal life—through your behavior. Read the privacy statements on the websites you visit, and only do business with ones whose practices you agree with. If you're worried about cookies, disable them. Most importantly, avoid indiscriminate Web surfing—recognize that just as most cities have a bad side of town that's best avoided, the Internet does too. But if it's complete and total anonymity you want, better start looking for that cave.
Top of page
Law #10: Technology is not a panacea
Technology can do some amazing things. Recent years have seen the development of ever-cheaper and more powerful hardware, software that harnesses the hardware to open new vistas for computer users, as well as advancements in cryptography and other sciences. It's tempting to believe that technology can deliver a risk-free world, if we just work hard enough. However, this is simply not realistic.
Perfect security requires a level of perfection that simply doesn't exist, and in fact isn't likely to ever exist. This is true for software as well as virtually all fields of human interest. Software development is an imperfect science, and all software has bugs. Some of them can be exploited to cause security breaches. That's just a fact of life. But even if software could be made perfect, it wouldn't solve the problem entirely. Most attacks involve, to one degree or another, some manipulation of human nature—this is usually referred to as social engineering. Raise the cost and difficulty of attacking security technology, and bad guys will respond by shifting their focus away from the technology and toward the human being at the console. It's vital that you understand your role in maintaining solid security, or you could become the chink in your own systems' armor.
The solution is to recognize two essential points. First, security consists of both technology and policy—that is, it's the combination of the technology and how it's used that ultimately determines how secure your systems are. Second, security is journey, not a destination—it isn't a problem that can be "solved" once and for all; it's a constant series of moves and countermoves between the good guys and the bad guys. The key is to ensure that you have good security awareness and exercise sound judgment. There are resources available to help you do this. The Microsoft Security website, for instance, has hundreds of white papers, best practices guides, checklists and tools, and we're developing more all the time. Combine great technology with sound judgment, and you'll have rock-solid security.
기본적으로 미들웨어는 애플리케이션들을 연결해 이들이 서로 데이터를 교환할 수 있게 해 주는 소프트웨어다. 미들웨어는 애플리케이션들을 직접 연결하는 방식에 비해 몇 가지 중요한 이점이 있다. 애플리케이션들을 직접 연결할 경우, 일반적으로 관련된 애플리케이션 모두에 코드를 추가해 각 애플리케이션이 서로 대화하도록 지시해야만 한다. 반면 미들웨어는 이 대화 과정에서 번역기라는 독립적인 제3자의 역할을 함으로써 애플리케이션 모두에 코드를 추가하는 엄청난 작업을 할 필요가 없다.
미들웨어의 종류
기업들이 통합과 관련된 여러 업무를 더 잘 처리하기 위해 여러 종류의 미들웨어를 도입하는 일은 이례적인 일이 아니다. 일반적으로 더 복잡한 통합 작업이 요구되는 더 큰 기업들은 EAI(Enterprise Application Integration)와 같은 더 정교한 미들웨어 제품을 선호하기 마련이다.
RPC와 데이터베이스 게이트웨이
설명
아마도 이것들은 진짜 미들웨어가 아닐 수 있지만, 문맥상으로 볼 때 전혀 관련이 없다고도 말할 수 없다. 양쪽 모두 애플리케이션 연결 기능을 다루는 더 오래된 방법들로, 특히 분산 환경에서 그렇다.RPC는 원격절차호출(Remote Procedure Call)의 약어로, 서버 애플리케이션에 있는 어떤 절차를 촉발하는 클라이언트 애플리케이션의 코드중 한 조각을 말한다. 오늘날의 정의에 따르면 RPC는 미들웨어가 아니다. 비록 지금도 사용되고는 있지만, RPC는 여러 개의 애플리케이션을 서로 묶으려 할 때 프로그래머들이 반복해서 코딩 작업을 해야만 하는 방식이기 때문이다. 따라서 애플리케이션의 수가 늘어나면 RPC 외의 다른 미들웨어 방식이 더 효과적이다. 현재 RPC는 미들웨어들에 의해 대체되고 있다. 반면 데이터베이스 게이트웨이는 데이터 접근을 용이하게 할 수 있는 제3의 역할을 하기 때문에 RPC보다 미들웨어의 정의에 더 들어맞는다. 데이터베이스 게이트웨이는 애플리케이션들을 특정 종류의 데이터베이스 플랫폼에 연결해 준다. 일례로 HP 3000 서버에 있는 중대형 애플리케이션 및 데이터를 가진 기업을 생각해 보자. 많은 새로운 상용 애플리케이션들이 오라클이나 사이베이스 같은 유명 데이터베이스에 접근할 수 있도록 고안되었지만, 이 애플리케이션들이 더 오래된 HP 3000용 ‘터보이미지(TurboImage)’ DBMS를 이용하려면 약간의 도움이 더 필요한데, 이때 데이터베이스 게이트웨이가 그런 도움을 주다. 이런 것이 데이터베이스 게이트웨이의 전형적인 활용 사례다.
메시지-지향 미들웨어(MOM)
제품
MQ시리즈(MQSeries) - 아이비엠MSMQ - 마이크로소프트스마트소켓츠(SmartSockets) - 탈라리안(Talarian)
설명
MOM은 오래된 미들웨어 기술이다. 메시지-지향 미들웨어는 이메일과 비슷한 방식으로 데이터를 메시지 형태로 만들어 하나의 애플리케이션에서 다른 애플리케이션으로 전달한다. 사실 상용 MOM 제품이 보급되기 전, 세계 최대의 곡물회사인 카길 같은 대기업은 데이터 전송을 위해 휴렛팩커드의 오픈메일(OpenMail) 이메일 엔진을 토대로 MOM 통합 도구들을 자체 개발했었다.이메일의 원리를 이해하고 있다면, MOM의 원리도 알 수 있을 것이다. 그리고 이메일의 경우처럼, MOM의 장점은 애플리케이션 A의 데이터가 대기열에 가서 기다릴 수 있기 때문에 애플리케이션 B는 나중에 필요한 시점에서 그 데이터를 불러올 수 있다는 것이다. 이로 인해 일례로 애플리케이션 A가 정보를 전달하려는 순간 애플리케이션 B가 우연히 다운돼 재부팅을 해야만 하는 등의 상황에서도 데이터의 무결성이 보호될 수 있다. 이런 비동기적 접근법을 사용해, 미들웨어 서버는 애플리케이션 B가 다시 작동을 시작할 때까지 기다린 후 대기열의 데이터를 올바른 순서에 따라 던져준다.(이 같은 데이터 메시지의 전송 유보는 앞에서 말한 지속성의 한 예다.)
전형적인 사용처
MOM은 대개 데이터에 대해 수행되어야 하는 운영이 비교적 많지 않고 데이터 교환 시간이 그리 중요하지 않은 단순한 일방향의 교환을 위해 사용된다. 일례로 서로 다른 데이터베이스에 저장되어 있는 저축성 예금과 수표 계좌의 연결을 들 수 있다. 고객이 수표 계좌에 대한 자신의 주소를 갱신하면, 이에 따라 총괄 시스템은 이 고객의 다른 계좌의 주소들도 갱신하게 되지만, 이 갱신 작업에 3초나 10분이 걸린다고 해서 그것이 그리 큰 문제는 되지 않을 것이다.
거래처리(TP) 모니터
제품
CICS, 오픈CICS(OepnCICS) - 아이비엠BEA 턱시도(Tuxedo) - BEA 시스템즈
설명
거래처리(TP) 모니터는 본래 메인프레임 환경을 위해 개발된 유래가 오래된 기술이다.(MOM보다 오래됐다.) TP 모니터는 거래 데이터의 작성과 읽기를 관리하기 위해 전위처리 애플리케이션들과 후방지원 데이터베이스 사이에 위치한다.TP 모니터는 메시지-지향 미들웨어보다 더 애플리케이션들에 간여한다. 이것은 TP 모니터가 제공하는 고유의 서비스 이점을 활용하기 위해서 TP 모니터들이 애플리케이션들에 대해 더 많은 수정 작업을 요구한다는 의미다. TP 모니터는 또한 특수 보안 기능과 데이터 무결성 기능을 제공한다.
전형적인 사용처
TP 모니터는 대규모의 거래가 처리되는 환경에 맞는다. 다시 은행 업무의 예를 들면, 현금자동입출금기(ATM)에서 기록되는 모든 거래는 해당 금융기관이 고객의 계좌 잔고를 정확하게 추적할 수 있도록 세심하게 다뤄져야만 한다. 이 일을 TP가 담당한다. 특히 TP 모니터는 복수의 애플리케이션들이 보안이나 디렉토리 서비스 같은 동일한 기본 기능 몇 가지를 동시에 필요로 할 때 유용하다.“TP 모니터의 이점은 새로운 애플리케이션들을 작성할 때 이 애플리케이션들에 맞춰 이런 서비스들을 다시 개발할 필요가 없다는 것이다.”라고 부쉐는 말한다. “애플리케이션들은 다른 종류의 미들웨어를 통해 서로 의사소통할 수 있지만, TP 모니터는 그 이상의 기능을 제공한다.” 따라서 TP 모니터를 단순한 일대일 애플리케이션 연결성을 위해 사용할 경우, 그것은 “성능 과잉”이 될 것이라고 그녀는 덧붙인다.
객체 모니터(Object Monitors)
제품
아이비엠 컴포넌트 브로커(Component Broker)비지브로커 ITS(VisiBroker Integrated Transaction Server) - 인프라이즈(Inprise)마이크로소프트 트랜잭션 서버(Transaction Server)
설명
객체 모니터(Object Monitors, 객체 TP 모니터라고도 불린다.)는 앞에서 설명한 TP 모니터의 발전된 버전이다. 새롭게 태동중인 제품군인 객체 모니터는 TP 모니터의 기능을 그대로 제공하지만, 바로 아래에서 설명될 객체요구브로커(ORB) 모델들과 같은 객체-지향 표준에 따라 작성된다는 점이 다르다. ORB 모델을 사용하기 때문에, 기업은 애플리케이션에 손을 대지 않고도 TP 모니터에 의해 제공되는 서비스들을 수정할 수 있다.
전형적인 사용처
온라인 쇼핑 장바구니 및 관련 주문처리 애플리케이션들 같은 전자상거래 애플리케이션이 객체 모니터를 사용하는 경향이 있다. 이것은 전자상거래 애플리케이션들이 서로 다른 많은 원천들로부터 데이터를 끌어올 필요가 있고, 갈수록 늘어나는 기능성에 맞춰 자주 수정될 필요가 있기 때문이다. 이에 필요한 유연성으로 인해 컴포넌트 기반의 아키텍처가 인기를 끌고 있는데, 이 아키텍처는 시스템의 다른 부분에 영향을 주지 않으면서도 시스템의 한 부분을 바꿀 수 있는 능력을 제공하기 때문이다. 또 객체 모니터는 웹 상거래시 필요한 고도의 데이터 무결성과 초대규모의 거래 용량 처리 능력을 제공한다.
객체요구브로커(ORBs)와 아키텍처
아키텍처 표준들
코바(Corba, Common Object Request Broker Architecture) - OMG(Object Management Group)엔터프라이즈 자바빈즈(EJB, Enterprise JavaBeans) - 썬 마이크로 시스템즈COM+(Component Object Model) - 마이크로소프트
설명
ORB는 애플리케이션과 네트웍 서비스(보안, 성능 모니터링, 프린트 등) 사이에서 정보를 전달한다. ORB는 서비스들과 상호운영 애플리케이션들을 위한 더 넓은 아키텍처 표준들의 핵심 부분이다. 위에 나열한 세 가지는 이런 표준 가운데 가장 유명한 주자들이다. 이 표준 가운데 하나를 구현한 실제 미들웨어 제품의 한 예가 최신 코바 표준 3.0에 기초하고 있는 아이오나(Iona) 테크놀러지로스社의 ‘오빅스 2000(Orbix 2000)’이다.ORB의 기본 전제는 애플리케이션들이 다른 애플리케이션들뿐 아니라 동일한 서비스들에도 접근할 필요가 있다는 것이다. 오늘날의 컴퓨팅 현실은 이기종 컴퓨팅 하드웨어와 운영체제 플랫폼 및 다양한 개발 도구들과 언어들로 구축된 애플리케이션들이 혼재돼 있다. 이 모든 컴포넌트(구성요소)가 서로 통신할 수 있도록 하기 위해서, 기업은 일관된 객체-지향 아키텍처가 필요한 것이다.그리고 비즈니스 파트너나 공급자들과 데이터 공유를 해야 하는 기업의 애플리케이션들이 늘어나면서, 이런 종류의 표준화된 접근법은 통합 작업을 크게 단순화시켜 줄 수 있다.코바는 역사적으로 유닉스 환경에 초점을 맞추고 있으며, 반면 엔터프라이즈 자바빈즈는 자바 언어로 개발하고 있는 기업에 가장 잘 맞는 아키텍처다. 좋은 소식은 이 두 표준이 서로 협력하고 있으며, 조화를 이루고 있다는 것이다. 코바 지지자들은 최소한의 작업으로 자바 개발 프로젝트를 통합할 수 있게 될 것이다.
그러나 부쉐는 현시점에서 코바 모델로 개발된 서버 객체들이 COM+ 모델로 개발된 서버 객체들과 잘 통신되지 않는다는 점을 지적한다.(반대도 마찬가지) 이것은 기업들이 이 2개 ORB 아키텍처 가운데 어느 한쪽을 선택해 사용해야지, 혼합 사용해서는 안된다는 것을 의미한다. 윈도우 NT/2000 서버 사용자들은 COM+에 의해 최적의 서비스를 받을 수 있다. 반면 유닉스 서버 사용자들(마이크로소프트의 윈도우를 탑재한 데스크탑 컴퓨터에 의해 접근되는 경우에도)은 코바가 최고의 선택일 것이다.
특별히 주목할 사항
마이크로소프트의 미들웨어 구조와 제품 계획들은 계속 진화되고 있으며, 그에 따라 관련 용어도 바뀌고 있다. 따라서 이 회사의 계획을 세심하게 따라가지 않는 사람들에겐 이것이 혼란의 한 원인이 될 수 있다. COM+의 원래 명칭은 단순히 COM이었다. 그러다 DCOM(Distributed Common Object Model)이 되었다. 부쉐에 따르면, 마이크로소프트는 현재 DCOM에서 벗어나 현재의 이름인 COM+으로 옮겼다고 한다. 그러나 COM+도 미들웨어 범주를 넘은 제품과 서비스를 포함하고 있는 DNA(Distributed Network Architecture)란 더 커다란 마이크로소프트 아키텍처 계획의 일부일 뿐이다.
기업 애플리케이션 통합(EAI)
제품
액티브엔터프라이즈(ActiveEnterprise) - 팁코 소프트웨어(Tibco Software)네온 임팩트(NEON Impact) - 뉴 에라 오브 네트웍스(New Era of Networks)이-게이트(e-Gate) - STC(Software Technologies Corp.)비즈니스웨어(BusinessWare) - 비트리아 테크놀러지(Vitria Technology)제네바 엔터프라이즈 인티그레이터(Geneva Enterprise Integrator) - 레벨 8 시스템즈(Level 8 Systems)(그 외 다수)
설명
EAI 업체들은 EAI 제품을 미들웨어라고 부르는데 커다란 거부감을 느끼고 있다. 기업(enterprise)이란 매력적인 단어를 포함하고 있는 EAI에 미들웨어란 명칭은 어울리지 않는다는 것이다. 그러나 EAI의 근본 개념은 통합이다. 불행하게도 EAI란 단어는 마케팅 목적에 아주 유용하기 때문에, 많은 업체가 각자의 제품이 제공하는 기능성들이 그처럼 폭이 넓음에도 불구하고 이 용어를 굳이 사용하고 있는 것이다. EAI는 미들웨어 이상이다. ORB와 같이 EAI 도구들은 일반적으로 데이터 전송을 위한 기저 메커니즘으로 메시지 브로커(broker)를 사용한다. 여기에 EAI 도구들은 데이터를 받으려는 각각의 특정한 애플리케이션의 입맛에 맞춘 형태로 데이터를 분석, 복제, 변환할 수 있다. 대기업의 경우, MOM과 EAI를 모두 사용할 수는 있지만, 아주 탄탄한 EAI 제품을 사용하고 있다면, MOM 같은 더 낮은 수준의 통합 도구를 사용하지 않아도 된다.EAI 도구들이 제공하게 될 차세대 기능성(이 기능성으로 인해 EAI와 다른 종류의 미들웨어는 한층 명확히 구분이 될 것이다.)은 비즈니스 프로세스 규칙들(rules)의 지원이다. EAI는 사용자가 적절한 비즈니스 프로세스를 정의하고 이런 규칙에 따라 데이터를 통합할 수 있게 해 준다. 일례로 적절한 권한자에 의해 승인을 받기만 하면, 구매 애플리케이션에서 수취 계정 애플리케이션으로 데이터를 자동으로 이동시키도록 규칙을 정할 수 있다.허위츠 그룹에 따르면, 비트리아社의 제품이 이런 종류의 비즈니스 프로세스 규칙을 지원한 최초의 제품이라 한다. 현재 다른 경쟁사들도 기업의 내부 및 공급망 전체에 이 기능을 추가할 수 있도록 각사 제품에 대해 작업하고 있다.XML(eXtensible Markup Language) 지원은 EAI 제품의 최대 장점중 하나다. 또한 EAI 제품은 비쯔톡(BizTalk, 마이크로소프트가 후원하는 B2B 통신 프로토콜)과 로제타넷(RosettaNet, 전자 업계 통신 프로토콜을 만들기 위한 이 업계 컨소시엄) 등 표준도 지원한다.
대부분의 EAI 제품의 경우, 사용자는 중앙 모듈을 구매한 후 각자가 필요로 하는 특정 인터페이스만을 선택적으로 구매할 수 있다. 일례로 STC의 이-웨이(e-Way) 제품군은 SAP, 시벨, 로터스 노츠, 다양한 후방지원 데이터베이스들을 위한 개별적인 ‘어댑터들(adapters)’을 포함하고 있다. 또한 대부분의 EAI 업체는 고객이 자체적으로 개발한 애플리케이션들을 연결할 필요가 있을 때, 고객의 프로그래밍 작업을 지원하는 서비스 부서를 갖고 있다. “그들은 80-20 법칙을 따르는 것처럼 보인다. 다시 말해 인터페이스의 80%는 미리 구축된 것을 사용하도록 하고, 나머지 20%는 고객이 작업을 하도록 하는 것이다.”라고 컨설팅 업체인 ARC의 부사장 존 캠패네일은 말한다.
전형적인 사용처
EAI는 많은 애플리케이션들을 통합해야 하는 대기업에 적합하다. 일례로 카길은 ERP, 유지보수 관리, 재고, 비용 회계 시스템 등 다양한 애플리케이션들을 연결하기 위해 BEA 시스템즈社의 이링크(eLink) EAI 제품을 사용하고 있다.
결론
당신의 회사에 적합한 미들웨어는 어떤 것인가? 유일한 대답은 없다. 서로 다른 애플리케이션과 통합 요구에 맞춰 각기 다른 미들웨어를 사용해야 한다. 반면 단일화된 접근법은 규모의 경제성을 제공하고 개발에 따른 수고를 덜어줄 것이다. 어느 경우든 각 용어가 무엇을 의미하는지 알고 있을 때, 선택의 고민은 훨씬 가벼워질 것이다.
http://www.ciokorea.com/001101/c74.htm
| 블로그 > kdnnetwork님의 블로그 http://blog.naver.com/kdnnetwork/140000675195 | ||||||||||||||||||||||||||||||||||
| 제 목 : 서버 모니터링 툴의 강자, RRDtool 가이드 (작성중. alpha 버전) 작성자 : 좋은진호(truefeel) 작성일 : 2003.9.22(월)~ 그래픽 모니터링 툴인 RRDtool과 그 프론트엔드 툴 HotSaNIC의 설치, 운영가이드이다. 1. RRDtool의 이해 2. RRDtool 설치 3. HotSaNIC 설치 4. RRDtool 직접 다루기 5. 문제 해결 6. 이용 사례 1. RRDtool의 이해 RRDtool에 대해 들어가기 전에 먼저 MRTG 툴을 설명할 필요가 있을 듯 하다. MRTG(Multi Router Traffic Grapher)는 이름에서도 드러난대로, SNMP 프로토콜을 사용하여 라우터를 거쳐가는 트래픽을 실시간 그래픽을 통해 모니터링하는데 가장 많이 사용한다. 이외에 시스템을 모니터링하는 여러 addon들이 있다. DISK 사용량, CPU사용량, 메모리 사용량, 데몬, 세션 개수 등.. 심지어는 P2P인 당나귀의 트래픽, 프락시 서버인 Squid 트래픽까지 실시간(실시간이라기 보다는 특정 시간간격으로 변화하여 보여준다는게 더 정확하지만)으로 웹에서 볼 수 있다. RRDtool은 MRTG처럼 실시간 그래픽 모니터링 기능을 가지고 있으면서 보다 더 개선된 형태의 툴이다. 보다 빠르고 시스템 로드를 덜 잡아먹는다. 또한 MRTG의 제약이었던 2개 이상의 데이터를 하나의 그래픽을 통해 표시할 수 있다. 그래픽의 유연성(?)면에서도 단연 RRDtool이 압도한다. [ MRTG로 트래픽 모니터링하는 화면 ] 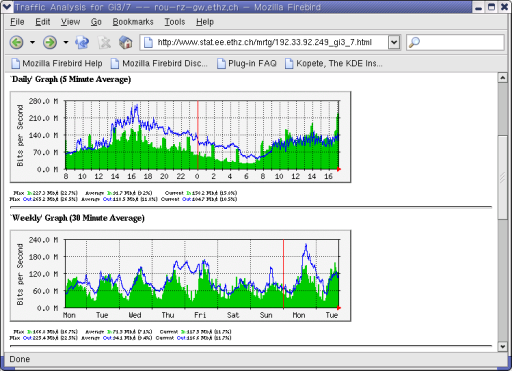 [ RRDtool과 HotSaNIC으로 CPU 사용률을 모니터링하는 화면 ] 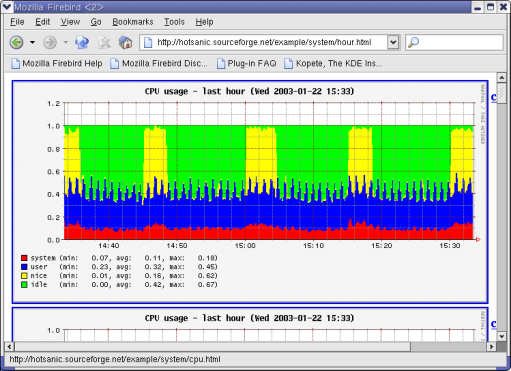 2. RRDtool 설치 RRDtool : http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/ RRDtool의 시스템 요구사항은 다음과 같다. Perl 5.005 (컴파일시에 문제가 발생하면 더 최신 것을 설치해본다.) GNU make GNU gcc 위 RRDtool 사이트에서 최신 버전을 받아온다. /usr/local/rrdtool에 하는 것으로 가정한다.
3. HotSaNIC 설치 HotSaNIC : http://hotsanic.sourceforge.net/archive/ HotSaNIC은 RRDtool을 사용하는 툴로 시스템 통계정보를 그래프로 생성해준다. * 시스템 요구 사항 - RRDtool - iptables 또는 ipchains (네트워크 트래픽 통계용으로 쓰기 위함) 위 사이트에서 받은 최신 버전은 컴파일없이 환경설정만으로 바로 사용하므로 /usr/local에서 압축을 푼다.
모니터링중이 아니라면 N) 있다면
3) 필요한 디렉토리 생성 이제 RRDtool의 웹용 이미지와 html이 저장될 디렉토리와 로그 파일 저장 디렉토리를 생성한다. 디폴트로 로그는 HoSaNIC 홈의 var/log에 생성된다. (html 홈은 /usr/local/apache/htdocs/ 라고 가정)
4) 환경 파일의 주요 설정 HoSaNIC 홈/settings가 주 설정 파일이고 HoSaNIC 홈/modules/모듈명/settings는 각 모듈별 설정 파일이다. 주 settings 파일에서 주요 설정을 살펴보자.(반드시 확인할 것에 * 표시해둠)
각 모듈별 설정은 해당 디렉토리의 settings을 보면 자세히 설명이 되어 있다. 여기서는 ping, diskio, apps에 대해서만 예를 들어본다. * ping 모듈 ( HoSaNIC홈/modules/ping/settings ) 192.168.123.15(파일서버)에 대해 ping을 한다면, 다음을 추가하면 된다.
설정했는데 ping 이미지가 생성안된다면 '5. 문제해결'에 해결방법을 설명해뒀다. * diskio 모듈 ( HoSaNIC홈/modules/ping/settings ) /proc/stat 에서 disk_io 라인을 살펴보면 다음과 같이 되어 있다. disk_io: (2,0):(1,1,2,0,0) (3,0):(306090,39930,942826,266160,5212040) (3,1):(55015,28746,1435800,26269,909568) (8,0):(50,50,253,0,0) 여기서 (3,0) = hda, (3,1) = hdb, (8,0) = sda를 각각 의미한다. 따라서 hda와 hdb의 disk 입출력을 보려면 다음과 같이 설정한다.
* apps 모듈 ( HoSaNIC/modules/apps/settings )
5) 실행 자~ 이제 웹페이지를 생성하고 rrdgraph만 실행하면 모니터링할 수 있다.
이제 웹브라우저를 띄우고 보면 된다. 아직 이미지도 안나온는데 뭘 보라는 것일까? 최소 15분(settings의 DTIME)이 지내야 모듈내의 큰 이미지들이 생성되고 24시간(CTIME)이 지나면 메인의 작은 이미지가 보일 것이다. 24시간 전이라도 적당한 시기에 ./convert.pl을 실행하면 메인에서도 이미지를 볼 수 있다. 부팅할 때 자동으로 rrdgraph가 실행되록 하려면 어떻게 해야할까? rrdgraph 스크립트를 /etc/rc.d/init.d 에 복사를 한 후 chkconfig로 서비스를 추가한다.
4. RRDtool 직접 다루기 HoSaNIC은 이미 정해진 모듈을 통해서 RRDtool을 다루는 것이다. 이제 시스템관리자가 원하는 데이터를 RRDtool로 직접 조작하여 통계용 이미지를 생성하는 방법을 알아본다. 간단히 과정을 정리해보면. - RRDtool용 자체 DB(일반적으로 .rrd로 지정)를 생성한다.(create) -> - 데이터를 업데이트하거나 (update) 가져온다.(fetch) -> - 이미지를 생성한다. (graph) 1) rrdtool 명령 익히기 DB 생성, 이미지 만드는 것은 모두 RRDtool홈/bin/rrdtool 명령을 통해서 한다.
rrdtool에서 사용 가능한 명령은 무엇이 있을까? ---------- ----------------------------------------------------------------------- 명 령 설 명 ---------- ----------------------------------------------------------------------- create 새로운 RRD DB를 만든다. update DB에 새 데이터를 저장한다. graph 저장된 DB자료를 이용해서 이미지를 생성한다. (.gif 또는 .png) dump RRD DB의 데이터를 XML 포맷으로 뽑아준다. restore XML 포맷에서 RRD DB로 저장한다. fetch RRD DB에서 데이터를 얻어온다. tune RRD DB의 설정을 변경한다. last RRD DB의 최종 업데이트 시간을 알려준다. info RRD DB의 헤더 정보를 보여준다. (파일명, 최근업데이트일, 설정값...) rrdresize RRA 크기를 변경한다. 가능하면 사용하지 말기를 xport RRD DB의 데이터를 XML 포맷으로 뽑아준다. (출력 포맷 지정) ---------- ----------------------------------------------------------------------- 2) 샘플 DB 생성 3) 이미지 만들기 5. 문제 해결 1) HoSaNIC 로그 파일을 보니 Can't locate RRDs.pm in @INC (@INC contains... 오류가 있습니다. RRDtool 설치할 때 make site-perl-install 를 하지 않아 RRDs.pm 펄 모듈이 설치되지 않아서 입니다. RRDtool 소스 디렉토리에 가서 make site-perl-install을 하세요. 2) makeindex.pl 실행할 때 다음 오류가 발행합니다. WEBDIR (path to HotSaNIC's output directory) does not exist. 시스템 모니터링 결과가 저장될 웹디렉토리를 생성하지 않았다. 위 글중 '3 - 3) 필요한 디렉토리 생성'을 확인해봐라. 3) 시간이 한참지났는데 ping 이미지가 생성이 안됩니다. 물론 ping설정은 했습니다. 로그를 보니 Can't locate asm/unistd.ph in @INC (did you run h2ph?).. 가 있습니다. 펄용 헤더 파일이 없기 때문입니다. 펄 헤더로 변환해주는 h2ph로 해결할 수 있습니다. cd /usr/include; h2ph -r -l . 6. 이용 사례 HanIRC의 채널별 사용자 통계를 보여준다. 5분간격의 데이터를 1시간 단위로 자동 업데이트한다. 장혜식님의 py-rrdtool을 사용한 페이지 http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/gallery/ * 참고 자료 http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/manual/index.html http://myhome.hanafos.com/~itup/index.html http://kltp.kldp.org/stories.php?story=03/02/13/1717339 | ||||||||||||||||||||||||||||||||||
수동으로 OS를 판별하는 대표적인 방법으로 TTL 값을 이용한 방법이 있다.
각 OS마다 고유한 TTL 값이 있기 때문에, ping이나 traceroute 명령으로 TTL 값을 확인할수 있고 OS를 추측할수 있는 것이다.
TTL | OS |
128 | Windows 98,2000 |
247 | Solaris 2.x |
255 | Accel linux, linux |
244 | Irix & linux |
54 | Windows NT |
31 | Firmware |
246 | Redhat linux, unix 4.0 |
248 | Unix 4.0 |
255 | Cisco router |
바로 위에서 언급한 TTL 값은 네트워크 환경에 따라서 크게 달라질 수가 있다.
아래의 예와 같이 ping 명령을 이용해 특정 IP를 스캔하면, TTL값을 확인할수 있다. 예로 쓰인 '218.52.198.73'의 TTL 값이 '128' 임을 알수 있고, 이를 통해 해당 OS가 'Windows 98/2000' 임을 짐작할수 있는 것이다.^^
| 블로그 > nirvana2k님의 블로그 http://blog.naver.com/nirvana2k/60003799955 | |
| 침입탐지시스템(IDS)은 침입차단시스템과 달리 애플리케이션 계층에 대한 심화된 분석을 수행함한다. 물론 애플리케이션에서의 분석이라는 측면에서 애플리케이션 프록시 게이트웨이 방식의 침입차단시스템도 이러한 기능은 수행할 수 있지만, 성능 문제로 인해서 현재는 많이 사용되지는 않고 있다. 이번 연재에서는 IDS 관리에 있어서 겪게 될 대다수의 어려움, 그러한 어려운 점을 극복하기 위해 IDS 도입 시 고려해야 할 사항은 무엇인지를 이야기하고자 한다. <편집자> 지난 호에서 침입차단시스템에 대해 이야기했지만 최적의 침입차단시스템을 도입하고 그것을 잘 관리하는 것만으로 모든 보안은 해결됐다고 볼 수는 없다. 침입차단시스템은 침입차단시스템이 정책상 허용하는 서비스에 대해서는 보호할 수 없기 때문이다. 물론 URL 필터링, 액티브X, 자바 필터링과 같은 기능을 제공하기도 하고 CIS(Content Inspection Server) 제품군과의 연동을 통해 이러한 단점을 극복하려고 시도도 하지만 그것만으로는 많은 기대를 할 수 없다. 침입차단시스템 운영 시 염두할 점은 SMTP, DNS, WWW, 미디어 등과 같이 외부의 모든 클라이언트에 대해 연결을 허용할 수밖에 없는 서비스는 언제라도 공격의 위험을 갖고 있다는 것이다. 그리고 침입차단시스템은 기본적으로 애플리케이션 정보에 대한 검사는 수행하지 않기 때문에 그러한 공격에 대해 별다른 감사 로그조차 없이 무방비가 될 수 있고, 이 점을 극복하기 위해 침입탐지시스템(Intrusion Detection System, IDS)이 소개됐다. IDS의 개념 IDS는 그 분석을 위한 자료 수집원에 따라 네트워크 기반 IDS와 호스트 기반 IDS로 나뉠 수 있으며 이 글에서는 네트워크 기반 IDS에 대해서 이야기하는 것으로 그 범위를 한정하겠다. 네트워크 기반 IDS는 네트워크 관문의 스위치에 포트 미러링의 형태나 TAP(Test Access Port)로 설치된다. 따라서 들어오고 나가는 트래픽을 모두 수집해 기존에 정의된 룰에 매칭해 이것이 침입인지 아닌지를 파악하고 침입이라면 관리자에게 여러 가지 방법을 동원해 통보한다. 방화벽과 가장 큰 차이라면 애플리케이션 계층에 대한 심화된 분석을 수행함으로써, 방화벽은 그 초점이 주로 네트워크 계층 정보에 대한 필터링을 수행한다는 점이다. 물론 애플리케이션에서의 분석이라는 측면에서 애플리케이션 프록시 게이트웨이 방식의 방화벽도 이러한 기능은 수행할 수 있으나 성능 문제로 인해서 현재는 많이 사용되지는 않고 있다. 그리고 IDS는 수동적인(Passive) 장비라서 네트워크에 영향을 미치지 않으며 패킷을 수집해 분석을 수행하고 차단보다는 탐지에 보다 더 초점을 맞췄다는 점이다. IDS 운영의 어려움 IDS 솔루션을 실제 도입해 운영한 적이 있는 관리자라면 누구라도 처음에 많은 어려움에 부딪히게 된다. 일단 네트워크에 설치된 이후 수많은 로그 화면에 압도당하게 되며 어떤 것이 정말 위험하고 어떤 것이 무시해도 될 로그인지 알 수가 없다. 방화벽과 IDS를 도입해 구축이 완료되면 기업 내 보안 수준이 높은 수준으로 향상됐다고 생각하기 쉬우나 실질적으로 제품을 커스터마이징해 가면서 그러한 기대도 한풀 꺾이게 된다. 극단적으로 말해서 IDS를 설치해 처음 나타나는 로그의 90%가 의미 없는 오탐지라면, 오탐지가 아닌 나머지 10% 정도만이 실질적으로 의미 있게 봐야 할 공격이다. 그리고 IDS는 침입을 막아주는 것보다는 탐지를 통한 사후 분석의 개념이 강하기 때문에 24시간 그것을 지속적으로 모니터링하면서 실시간으로 대응할 보안 전문가의 노력이 없다면 해킹은 막을 수 없다. 1. 관리적 어려움 ① IDS 커스터마이징 IDS 도입 후 제일 처음 관리자가 부딪히게 될 어려움은 너무나도 많은 양의 로그다. 초기 설치된 채로 유지돼 1개월도 채 안 돼 수십 기가에 달하는 로그 서버의 하드디스크 공간을 잠식해 버린 업체를 본 적이 있다. 콘솔 상에서 너무나도 많은 이벤트가 빠르게 지나가는데 실질적으로 그만큼 많은 공격이 네트워크 상에서 이루어지고 있는 것일까? 그것은 확실히 아니다. 따라서 환경에 맞는 커스터마이징은 필수적이다. 커스터마이징 과정에서 겪게 될 어려운 점은 일반적으로 다음과 같다. - 무의미한 룰에 대한 미탐지 설정 우선 관리자가 보안에 대해서 많은 지식을 가지고 있지 않다면 해당 룰이 의미 있는 공격인지 그렇지 않은지 알 수 없다. 그렇다고 해서 위험도가 낮다고 한 룰은 탐지하지 않도록 할 것인가? 이런 판단을 하게 되는 관리자도 종종 본 적이 있지만 위험도란 관점은 상대적인 개념이다. 즉 IDS 벤더에서 위험도가 낮다고 한 룰이 오히려 그 사이트에서는 가장 중요한 룰이 될 수가 있고, 위험도가 높다고 한 룰이 오히려 무의미한 룰일 수 있다. 따라서 그런 룰에 대해 IDS 벤더에서 위험도가 낮다고 해서 미탐지를 할 것이라고 결론 내리기에는 이르다. - 파라미터 튜닝 설정 일부 서비스거부(DoS) 공격, 브루트 포스(brute force) 공격, 스캐닝(scanning) 공격 등은 특정 접근 시도가 특정 시간 내에 특정 회수 이상만큼 나타나면 경고를 발생하도록 설계돼 있다. 이러한 종류의 공격들은 설정 가능한 파라미터가 존재해 어느 정도 적절한 수치를 주느냐에 따라 효율적으로 탐지하거나 그렇지 않을 수 있다. 문제는 어느 정도 적절한 수치를 어떻게 결정하느냐 하는 것인데 그것이 쉬운 일이 아니다. 당연히 자사의 인터넷 회선으로 T1 라인을 사용하는 경우와 OC-3를 사용하는 경우가 그러한 파라미터는 다를 수밖에 없는데 IDS 벤더에서 자사의 환경에 맞는 최적의 값을 제안한 것은 아니다. 실제로 특정 IDS 업체에서 제공하는 기본값을 그대로 사용할 경우, 단지 특정 서버로 핑(ping)을 지속적으로 실행시키기만 해도 핑 플루딩(ping flooding)이라는 경고가 발생하는 경우를 볼 수 있었다. 그렇다면 어떻게 파라미터를 정할 것인가? - 신뢰 IP의 지정 그나마 커스터마이징 과정에서는 가장 쉬운 부분일 수 있다. 많은 공격 탐지에 대해 소스IP나 목적지IP가 동일한 양상을 보인다면 그것에 대한 IP 정보를 확인함으로 신뢰 IP를 지정할 수 있다. 예를 들어 SNMP를 통해 인터페이스 정보를 수집했다는 공격이 특정 소스IP로부터 많은 탐지를 보였는데, 해당 소스IP가 SNMP를 통한 정보 수집 기능을 하는 NMS 장비였다면 이것은 정상적인 네트워크 활동에 대해 탐지된 것으로 볼 수 있다. 이런 경우 해당 공격에 대해 신뢰IP를 지정해 그 IP에 대한 공격은 탐지하지 않도록 설정하는 것이다. 그런데 이러한 설정이 어려운 경우가 있다. 보다 복잡한 공격(예를 들어 쿠키의 내용 중에 바이너리 코드가 포함돼 있어서 탐지된다는 등)에 대해서는 해당 공격에 대한 경고가 발생하는 조건이 무엇인지, 그리고 왜 발생한 것인지에 대한 상세한 로그를 IDS에서 제공하는 상세 로그 분석을 통해 확인해야 하는 경우다. ② 엔진 및 패턴 업데이트 IDS는 벤더에서 구현한 시그니처를 기반으로 탐지한다는 점에서 안티 바이러스 제품과 매우 흡사하다. 물론 그렇기 때문에 엔진 및 패턴 업데이트가 중요하다. 최근에는 제로 데이 어택(zero-day attack)의 시대여서, 취약성 릴리즈와 그에 대한 공격 코드 발표일의 차이가 아주 짧아지고 있는 추세다. 새로운 취약성이 나타났을 때 해당 취약성에 대해 IDS 벤더에서는 해당 취약성에 대한 패턴 업데이트를 얼마나 빨리 발표할 것인지 그것을 IDS 관리자는 얼마나 빨리 업데이트를 할 것인지는 이제 효율적인 공격 탐지에 필수적이다. ③ 실시간 대응 IDS 도입 이후 겪게 될 가장 큰 혼란과 어려움 중 하나는 실시간 대응에 대한 문제다. IDS 무용론을 이야기한 가트너 그룹에서 그 이유로 이야기하는 점은 IDS는 기본적으로 설치 이후 로그양이 너무 많아서 그것에 대한 분석 및 커스터마이징을 위해 보안전문가라는 인력이 필요하다는 점, 그리고 IDS는 차단보다는 탐지에 초점을 맞췄기 때문에 그러한 보안전문가가 24시간 계속 콘솔을 전담 모니터링해야 한다는 점이다. 물론 이러한 점은 IDS 벤더도 오래 전부터 이해하고 있었기 때문에 ‘방화벽과의 연동’, ‘TCP 세션 끊기’를 통한 능동 차단 기능을 구현하고 있다. 하지만 IDS의 고질적인 오탐지(false positive) 문제가 해결되지 않는 상황에서 능동 차단 기능을 적용할 수는 없는 노릇이다. ④ 룰에 대한 상세한 정보 침입탐지 이벤트가 발생했을 때 관리자는 룰에 대해서 이것이 오탐지는 아닌지, 그리고 오탐지가 아니라면 얼마나 위협적인 공격인지를 파악해야 한다. 그것을 위해서는 룰에 대한 상세한 정보(해당 룰에 의한 침입탐지 이벤트가 발생하는 조건, 해당 룰과 관련된 애플리케이션, 취약성 발표된 시기, 취약성에 대한 설명, 오탐지가 발생할 수 있는 조건 등)가 온라인으로 확인할 수 있어야 하며 관리자가 쉽게 이해할 수 있어야 한다. 2. 탐지 기능의 문제점 과거 많은 IDS가 탐지 기능의 문제점을 가졌다. 원래 IDS는 단순히 패킷에서 해킹에 해당되는 패턴이 있는지 검색하는 패킷 그래핑(packet grepping) 수준이었다. 하지만 이후 너무나도 많은 회피 기법에 의해 IDS를 속일 수 있다는 것이 알려졌다. 이러한 모든 회피 기법의 아이디어는 ‘해킹 당하는 대상을 IDS가 정확히 이해하지 못한다’는 것이다. ① 공격에 사용되는 프로토콜을 인지하지 못하는 경우 공격에 사용되는 프로토콜을 정확히 파악하지 못해서 생기는 문제는 다양하다. 1. ‘GET /scripts/..%c1%1c../winnt/system32/cmd.exe?/ c+dir HTTP/1.0’ 2. ‘get /scripts/..%c1%1c../winnt/system32/cmd.exe?/ c+dir http/1.0’ 3. ‘GET /scripts/..%c1%1c../winnt/system32/cmd.exe?/ c+dir HTTP/1.0’ 위의 세 가지 요청은 HTTP 프로토콜 상에서 동일한 의미를 가진다. 하지만 실제 어떤 IDS 제품은 1번은 탐지하나, 2번이나 3번 둘 중의 하나, 혹은 두 가지 모두를 탐지하지 못 하는 경우도 본 적이 있다. 그밖에 웹 서버의 포트 번호가 달라져도 탐지를 못 하는 경우가 있어서 그러한 IDS 제품에 테스트의 목적으로 2123 포트에 운영 중인 웹 서비스에 관련 공격이 들어온다면 무방비 상태가 되는 것이다. ② 각종 URL 회피 기법 휘스커(Whisker) 툴에 기반한 닉토(nikto)는 휘스커 툴에서 사용할 수 있었던 각종 URL 회피 기법을 테스트할 수 있다. 이러한 URL 회피 기법의 몇 가지 예를 보면 다음과 같다. IDS 제품에서 이러한 회피 기법을 모두 지원하는 경우도 있지만 그렇지 않은 경우도 있다. 테스트는 쉽게 닉토 툴로 할 수 있다. · Self-reference directory: ‘GET /cgi-bin/jj’ → ‘GET /./cgi-bin/./jj’ · URL encoding: ‘GET /cgi-bin/jj’ → ‘GET /%63%67%69% 2d%62%69%6e/%6a%6a’ · Reverse traversal: ‘GET /cgi-bin/jj’ → ‘GET /test/../cgi-bin/jj’ · Windows delimiter: ‘GET /cgi-bin/win-c-sample.exe’ → ‘GET \cgi-bin\win-c-sample.exe’ · NULL method: ‘GET /cgi-bin/win-c-sample.exe’ → ‘GET%00 /cgi-bin/jj’ ③ IP 프레그멘테이션·조각난 TCP 스트림을 이용한 IDS 회피 가장 잘 알려진 IDS 회피 기법이라면, IP 프레그멘테이션(fragmentation)을 이용한 IDS 회피, 그리고 조각난 TCP 스트림을 이용한 IDS 회피를 예로 들 수 있다. 이들을 제대로 탐지하기 위해서는 IP 디프레그멘테이션(defragmentation)과 TCP 스트림 리어셈블리(stream reassembly) 기능이 구현돼 있어야 한다. 이를 테스트하기 위한 유명한 툴은 더그 송(Dug Song)의 프레그라우트(fragroute)다. 프레그라우트 실행화면 예제는 <그림 3>과 같다. ④ 성립되지 않은 세션에서의 TCP 공격 TCP 스트림과 같이 세션에 의한 문제를 야기할 수 있는 것을 한 가지 더 보자. 스틱(stick)이라는 툴이 있다. 이 툴은 IDS를 테스트하기 위한 툴 중 하나인데, 대표적인 기능 중 하나가 세션을 맺지 않고 TCP 공격 패킷을 보내는 기능이다. TCP는 연결 지향 프로토콜로서 정보를 교환하기 전에 먼저 3웨이 핸드쉐이크(handshake)에 의해 연결을 성립한 후 정보를 보내고 제대로 받았다는 것을 인정하는 절차를 거친다. 즉 세션을 맺지 않고 TCP 공격 패킷을 보낸다면 응답으로 RST(리셋) 패킷을 받게 될 것이다. 이럴 경우 공격은 이뤄지지 않았지만, IDS는 경고 이벤트를 발생하게 된다. 가장 쉽게 알 수 있는 문제점은 소스 IP를 엉뚱한 IP로 속여서 다수의 경고를 발생시킬 수 있다. 단순히 재미 삼아서, 혹은 어떤 뚜렷한 목표를 가지고 특정 소스 IP를 범죄자로 오인 받게 만드는 것이 가능하다. 앞서 말한 능동 대응이 활성화된 경우에 이러한 공격을 하게 되면 큰 문제가 야기될 것을 짐작할 수 있다. 위와 같이 IDS를 운영하고 BMT 하면서 겪은 다양한 난제들이 있으며, 이 밖에도 운영하면서 많은 어려움을 접하게 될 수가 있다고 예상된다. 자사에 IDS 도입을 할 때에도 이러한 점들을 염두에 두고 필요한 기능을 고려해 도입해야 할 것으로 보인다. IDS 도입시 고려 사항 1. 제품 선정 과정에서의 고려 사항 이러한 침입탐지시스템 도입을 위해 제품 선정 과정에서 고려해야 할 사항은 <표 1>과 같이 정리될 수 있다. 2. 제품 설치 과정에서의 고려 사항 제품을 도입한 후 실환경에 적용하는 과정에서 고민돼야 할 점들은 다음과 같다. - IDS의 네트워크 구성 상에서의 위치는 어떻게 할 것인지(만약 방화벽을 운영한다면 인터넷 쪽에 둘 것인지 DMZ에 둘 것인지, 내부 네트워크에 둘 것인지) 인터넷 쪽에 IDS를 두게 된다면 방화벽을 통과하지 않게 될 공격까지 탐지돼 많은 오탐지를 발생할 수 있다는 단점, 내부 네트워크에 둔다면 포트스캐닝 공격과 같은 리커네선스(reconnaissance) 공격은 대부분의 스캐닝 패킷이 방화벽에 차단돼 IDS에서 탐지되지 않는다는 단점이 일반적이다. 이 점을 극복하기 위해 모든 포인트에 IDS를 배치할 수도 있겠지만 그만큼 비용이 증가한다는 점도 잊지 말아야 한다. - 스위치의 포트 미러링 세팅으로 설치할 것인지, TAP 장비를 이용할 것인지 스위치에서 포트 미러링을 설정할 경우 스위치의 성능 저하 문제가 있지 않을까 걱정에서 이런 영향을 전혀 고려할 필요가 없는 TAP 장비를 추가하는 경우가 있다. TAP 장비는 장비 자체에서 장애가 나더라도 정상적인 트래픽 송수신에 이상이 없고 네트워크 성능에 영향을 미치지 않기 때문에 선호된다. 하지만 포트 미러링 설정으로 인한 스위치의 성능 저하 문제도 무시할 수 있을 만큼 작아졌고 없는 경우도 많기에 성능 문제로 크게 고민할 필요는 없다. 3. 제품 운영 과정에서의 고려 사항 IDS는 방화벽보다 특히 운영 과정에서 보안 지식이 많이 필요한 솔루션이다. 이것을 효율적으로 운영하기 위해서는 체계적인 교육을 받은 보안전문가라는 전담인력이 필요하고 모니터링은 어떻게 할 것인지 고민돼야 한다. IDS 도입을 하게 되는 많은 기업이 힘들어하게 되는 부분인데 이 부분에 대해서는 보안관제서비스(Managed Security Service)를 이용해 비용대비 효과를 극대화시키는 것도 고려할만하다. 자체 인력으로 해결하든 아웃소싱을 통해 해결하든 간에 IDS 도입으로 기대효과를 극대화하기 위해서는 무엇보다도 적절한 운영 및 대응 프로시저 마련이 필요함을 염두에 둬야 한다. 결론 이제까지 침입탐지시스템을 운영하면서 겪을 수 있는 어려운 점들, 그리고 그러한 어려운 점들을 해소하기 위해 제품 도입 시 고려해야할 점들을 살펴봤다. IDS의 한계를 극복하기 위해 많은 시도가 있고 그 결과 침입방지시스템(IPS)이라는 능동형 보안 솔루션도 나타나고 있다. 그러나 오탐지의 극소화, 네트워크 관문에 설치돼 방어도 가능하게 한다는 IPS 역시 기본적으로는 IDS에 이론적 밑바탕을 두고 있기 때문에 IPS가 IDS를 완전히 대치하게 될 것인지는 좀 더 두고 볼 일이다. 무엇보다도 IDS는 설치 이후 자사의 환경에 맞는 커스터마이징 작업, 무수한 침입탐지 이벤트에서 실제로 의미 있는 이벤트에 대한 분석을 할 수 있는 보안전문지식이 필요한 솔루션이다. IDS를 도입했지만 그것을 제대로 관리를 하지 못해 업데이트한지 오랜 시간이 지난 엔진으로 단순한 로그 수집으로 방치하고 있는 관리자를 본 적도 많이 있다. 관리자는 모든 것이 해결돼 안심할 수 있는 방안을 찾고자 한다. 보안에 있어서 지속적인 모든 것을 100% 근본적으로 해결해줄 방법은 없다. 지속적이고 꾸준한 관리가 없는 보안을 하는 것은 하지 않는 것과 다를 바 없다. [NETWORK TIMES 2004년 05월호 이용학 코코넛 기술본부 대리 ] |
'Mission Critical' 이란 말을 무지 무지 많이 들은적이 있다! 기업의 중대한 업무에 사용 되는 장비의 광고에는 항상 이런 문구가 들어 있다. 아마 왠만한 시스템관리자는 지겨운 말 일 것이다. 시스템관리자의 가장 큰 고민은 무엇인가? 서버가 다운되지 않고 항상 한결같이 잘 돌아가 모든 서비스가 완벽하게 이루어지는 것일 것이다. 물론 일부에선 그런 환경이 만들어져 자신이 한가해지길 바라는 시스템관리자도 있겠지만 말이다. 하지만, 시스템관리자 못지 않게 시스템 다운에 민감한 사람이 또 있다. 바로 인터넷업체의 사장님들이다. 내가 알고 있는 인터넷 업체의 사장님들은 술을 마시고도 집에 들어가기 전 게임방에 들려서 자신의 회사 사이트에 확인 해보고 집으로 들어가는가 하면 자다가도 일어나서 사이트에 접속하기도 했다. 시스템관리자, 사장님 모두 시스템의 다운을 항상 걱정하고 있다. 그렇다고 시스템을 무한정 확장하고 비싼 관리 소프트웨어를 사용할 수도 없는 일이다. 바로 이런 필요에 의해 발생한 것이 바로 클러스터링이다. 실제로 일정 수준 이상의 규모가 있는 업체의 대부분의 서버가 클러스터링이 되어 있다. 그러면 이런 클러스터링이 무엇을 의미하는지, 그리고 어떻게 사용되고 있는지 자세히 알아보도록 하겠다. 이번 글에서 자세하게 알아볼 것은 클러스터링 기술 중 로드밸런싱, 즉 부하조절이라는 부분이라는 것도 있지 말자! 클러스터는 여러개의 시스템이 하나의 거대한 시스템으로 보이게 만드는 기술이다. 이렇게 하는 기술에는 여러 가지가 있기 때문에 각 기술의 특징을 잘 이해하는 것이 클러스터링 기술을 잘 활용할 수 있는 방법이다. 컴퓨터 클러스터링은 Digital VAX 플랫폼을 시초로 1980년대부터 다양한 형태로 만들어지기 시작했으며, 이러한 클러스터는 디스크 공간 같은 하드웨어 자원을 공유할 수 있었고, 여러 사용자에게 컴퓨팅 자원을 제공할 수 있었다. 클러스터는 노드와 관리자로 구성되어 있다. 노드는 프로세싱 자원을 제공하는 시스템이고, 클러스터 관리자는 노드를 서로 연결하여 단일 시스템처럼 보이게 만드는 로직을 제공한다. 클러스터노드 클러스터 노드는 클러스터의 실질적인 작업을 처리하는 것을 말한다. 일반적으로 클러스터 노드는 클러스터에 속하도록 구성해야 한다. 클러스터의 역할과 업무에 따라 해당 소프트웨어는 독특하게 제작된 것일 수도 있고, 일반적인 소프트웨어 일 수도 있다. 역할에 따른 특정 소프트웨어라면 공학 계산을 위한 각 노드에 맞는 프로그램일 수도 있으며, 일반적인 소프트웨어는 로드밸런싱을 위한 클러스터라면 아파치 같은 소프트웨어를 들 수 있을 것이다. 클러스터관리자 리눅스의 커널이 모든 프로세서에 대한 스케쥴과 자원관리를 하는 것처럼 클러스터 관리자 역시 이런 관리자의 역할로써 각 노드에 대한 자원분배 및 관리를 할 수 있는 기능을 가지고 있다. 기본적으로 하나의 관리자가 필요하지만 때에 따라서는 클러스터 노드가 클러스터 관리자 기능을 하기도 하며, 대규모 환경의 경우에는 여러대의 클러스터 관리자가 있기도 하다. 클러스트의 정의는 매우 광범위하다. 리눅스에서는 LVS(Linux Virtual Server) 라는 이름으로 불리기도 한다. 또한 앞에서 설명한 여러 가지들도 하나의 클러스터 기술이다. 그 만큼 클러스터는 여러 가지 기능을 하고 있으며, 시스템관리자의 고민을 해결해 주고 있다. 클러스터의 주요 목적은 CPU자원을 공유하거나, 여러 컴퓨터간의 부하 조정, 가용성이 높은 시스템을 구축, 주 시스템이 다운 되었을 때를 대비한 Fail-Over 기능을 제공하는 것이다. 공유 프로세싱 : HPC(High Performance Computing) 일반적으로 리눅스 클러스터링이라고 불리는 클러스터링이다. beowulf 프로젝트로도 유명하다. beowulf는 여러 시스템의 프로세싱 능력을 조합하여 대용량의 프로세싱 능력을 갖는 하나의 시스템을 제공한다. 이것은 원래 과학용 시스템이나 CPU 위주의 용도로 설계된 것인데, 이 시스템에서는 API에 따라 특별히 작성된 프로그램만 자신의 작업을 여러 시스템 사이에 분배할 수 있다. 즉, 프로그밍을 별도로 해야할 경우가 많아진다는 것이다. beowulf에 관한 자료는 http://www.beowulf.org/ 에 가면 얻을 수 있다. [리눅스원 HFC 와 아발론 HFC]
부하조정 : Load Balancing 최근에 대규모 웹사이트 구축에 필수적으로 사용되는 기술로 여러대의 웹서버 노드를 두고 중앙의 관리툴에서 부하를 분산하게 해주는 기술이다. 이 기술의 특징은 노드 간 통신이 필요 없다는 것이다. 부하 조정을 이용하면 각 노드는 자신의 용량이나 로드에 맞게 요청을 처리할 수 있기도 하고, 클러스터 관리자에서 할당한 양의 프로세스를 처리할 수도 있다. Fail-Over Fail-Over는 부하조정과 비슷하다. 하지만 조금 틀린 것이 있는데 부하조정의 경우에는 모든 노드가 한꺼번에 동작을 하는 것이고, Fail-OVer의 경우에는 평소엔 동작을 하지 않고 Primary 서버가 문제가 발생했을 시에 백업서버로써 가동을 하는 것이다. 부하조정을 응용하면 부하조정과 Fail-Over 기능을 동시에 하게 할 수가 있다. 높은 가용성 아무리 시스템 관리자가 뛰어난 실력을 지니고, 부지런하다고 해도, 서버는 기계이기 때문에 간혹 문제를 발생하기도 한다. 어떤 경우에는 관리자도 어떻게 할 수 없는 상황이 발생하기도 한다. 이런 경우에 최대한 가용성을 높이기 위한 방법이 바로 클러스터링이다. 이런 높은 가용성을 만들기 위해 위의 Fail-Over 기술을 사용한다. 클러스터 관리자는 클러스터 시스템에서 가장 중요한 역할을 하는 것이다. 실제로 여기서 다룰 클러스터링은 부하분산 즉 로드밸런싱에 관한 부분이다. 이것은 관리자의 부하 분산 방식에 따라 그 효과는 천차만별로 달라진다. 부하 분산 작동 방식에는 직접포워딩, IP터널링, NAT의 세가지 방식이 있다. 이 세가지에 대해서 자세히 알아보도록 하겠다. 직접포워딩 (Direct Routing)
부하분산 서버는 단순히 데이터 프레임의 MAC 주소만 선택한 서버로 바꾸며 이를 다시 LAN에 재전송한다. 이런 이유 때문에 부하분산 서버와 각 서버가 단일한 물리적 세그먼트안에서 연결되어야한다. 부하분산 서버를 통해 전달될 필요가 없기 때문에 빠르고 오버헤드가 적다. IP 터널링 IP 터널링 (IP encapsulation)은 IP 데이터그램안에 IP 데이터그램을 넣는 기술로서, 어떤 IP 주소를 향하는 데이터그램을 감싸 다른 IP 주소로 재지향할 수 있다. IP encapsulation은 현재 엑스트라넷, 모빌-IP, IP-멀티캐스트, tunnled 호스트나 네트웍 등에 일반적으로 사용되고 있다.
IP터널링을 이용하는 경우, 부하분산서버는 단지 들어오는 요청에 대하여 각기 다른 실제 서버로 할당만을 할 뿐이고 실제 서버가 사용자에게 직접 응답을 보낸다. 그래서 부하분산서버에서 더 많은 요청를 처리할 수 있으며 100개 이상의 실제 서버를 다룰 수 있다. 또한 부하분산서버자체가 시스템의 병목지점이 되는 현상도 없앨 수 있다. 이렇게 IP 터널링을 이용하면 부하분산서버에서 사용할 수 있는 서버 노드의 수를 크게 늘릴 수 있다. 설사 부하분산서버가 100Mbps full-duplex(전복조) 네트웍 어댑터를 가졌어도 가상 서버의 최대 처리량은 1Gbps에 달할 수 있다. IP 터널링의 이러한 특성을 이용하면 아주 높은 성능의 가상 서버를 구축할 수 있으며, 특히 가상 프록시 서버에 적합하다. 프록시 서버에서 요청을 받는 경우, 인터넷에 직접 연결하여 개체를 가져오고 그것을 바로 사용자에게 보내줄 수 있다. 그러나, 모든 서버에서 "IP 터널링"(IP Encapsulation)을 지원해야한다.NAT (Network address translation) IPv4에서는 IP주소가 부족하고 보안상에 몇가지 문제가 있어서, 점점 더 많은 네트웍에서 인터넷에서 사용할 수 없는 사설 IP(10.0.0.0/255.0.0.0, 172.16.0.0/255.240.0.0 , 192.168.0.0/255.255.0.0)를 사용하고 있다. 사설망에 있는 호스트에서 인터넷에 접속을 하거나 인터넷망에서 사설망의 호스트에 접속하기 위해서 NAT(network address translation)기능이 필요하다. NAT는 특정한 IP 주소를 한 그룹에서 다른 그룹으로 매핑하는 기능이다. 주소를 N-to-N 형태로 매핑하는 경우를 정적 NAT라 하고 M-to-N(M>N)를 동적 NAT라고 한다. 네트웍 주소 포트 변환은 기본 NAT의 확장기능으로 여러 가지 네트웍 주소와 TCP/UDP 포트를 단일의 네트웍 주소와 TCP/UDP 포트로 변환한다. N-to-1 매핑이라고 하며 리눅스에서 IP 마스커레이딩도 이러한 방식을 이용한다. 리눅스에서 NAT를 통한 가상 서버는 네트웍 주소 포트 변환을 통해 수행한다. 리눅스 IP 마스커레이딩 코드를 이용하며, 스티븐 클락(Steven Clarke)의 포트 포워딩 코드를 재사용하고 있다.
NAT를 이용하면 실제서버가 TCP/IP를 지원만 하면 모두 가능하고, 실제서버를 완벽하게 숨길 수 있어 보안성을 향상 시킬 수 있으나, 확장성에 제한이 있다.일반적인 PC서버 기준으로 했을 때 서버노드가 20개 이상으로 증가할 경우 부하분산서버에서 병목이 생길 수 있다. 왜냐하면 패킷이 들어오고 나갈때마다 부하분산서버에서 패킷을 변경해야하기 때문이다. 다음과 같이 가정해보자. TCP 패킷의 평균 길이가 536Bytes 이다. 패킷 변경에 의한 지연시간은 60us(펜티엄 프로세서 기준이며 이보다 더 뛰어난 프로세서를 쓰면 지연시간이 감소될 것이다)이고 부하분한서버의 최대 처리량이 8.93MBytes/s이다. 실제 서버의 평균 처리량이 400Kbytes/s 일때 부하분산서버는 22개의 실제 서버를 스케쥴링할 수 있다. 무지 어려운 말이다. 스케쥴링 알고리즘. 스케쥴이라는 말은 모두 잘 알고 있을 것이다. 시간표도 하나의 스케쥴링 이니까. 실제로 클러스터 관리자의 가장 중요한 역할이다. 아무리 많은 클러스터 노드가 있다고 해도 관리자가 실제로 일을 배분하는데 뇌물을 먹고 한 노드에게만 준다던지, 아니면 아예 주지 않는 다면 그건 무용지물 인 것이다. 이렇게 일을 주는 방법에도 여러 가지가 있다 이번에는 그런 스케쥴링 알고리즘에 대해서 설명하겠다. 실제로 클러스터 관리자는 뇌물을 먹지 않으니 걱정 안해도 된다. Round-Robin Scheduling (라운드 로빈 스케쥴링) 말 그대로 라운드 로빈 방식이며, 서버의 상황이나 네트웍 상황, 모든 상황을 무시한채 단순하게 요청을 전달해주는 형태이다. 실제로 서버의 사양이 모두 동일하고, 같은 네트웍 상이라면 가장 단순하고 효율적일 수도 있다. Weighted Round-Robin Scheduling (가중치기반 라운드 로빈 스케쥴링) 가중치란 것은 어떤 특정한 것에 가중치를 둔다는 말이다. 서버에서도 특정서버의 스펙이 굉장히 뛰어나다던지 아니면 다른 서버보다 기타 환경이 나아 더 많은 요청을 전달하고 싶을 때 해당 서버에 가중치를 주어 더 많은 요청을 처리할 수 있도록 하는 방식이다. 가중치가 있는 라운드 로빈 스케쥴링을 사용하면 실제 서버에서 네트웍 접속을 셀 필요가 없고 동적 스케쥴링 알고리즘보다 스케쥴링의 과부하가 적으므로 더 많은 실제 서버를 운영할 수 있다. 그러나 요청에 대한 부하가 매우 많을 경우 실제 서버사이에 동적인 부하 불균형 상태가 생길 수 있다.Least-Connection Scheduling (최소 접속 스케쥴링) 최소 접속 스케쥴링은 가장 접속이 적은 서버로 요청을 직접 연결하는 방식을 말한다. 각 서버에서 동적으로 실제 접속한 숫자를 세어야하므로 동적인 스케쥴링 알고리즘중의 하나이다. 비슷한 성능의 서버로 구성된 가상 서버는 아주 큰 요구가 한 서버로만 집중되지 않기 때문에, 접속부하가 매우 큰 경우에도 아주 효과적으로 분산을 한다. 가장 빠른 서버에서 더 많은 네트웍 접속을 처리할 수 있다. 그러므로 다양한 처리 용량을 지닌 서버로 구성했을 경우에도 훌륭하게 작동 한다는 것을 한눈에 알 수 있을 것이다. 그렇지만 실제로는 TCP의 TIME_WAIT 상태 때문에 아주 좋은 성능을 낼 수는 없다. TCP의 TIME_WAIT는 보통 2분이다. 그런데 접속자가 아주 많은 웹 사이트는 2분동안에 몇천개의 접속을 처리해야 할 경우가 있다. 서버 A는 서버 B보다 처리용량이 두배일 경우 서버 A는 수천개의 요청을 처리하고 TCP의 TIME_WAIT 상황에 직면하게 된다. 그렇지만 서버 B는 몇천개의 요청이 처리되기만을 기다리게 된다. 그래서 최소 접속 스케쥴링을 이용할 경우 다양한 처리용량을 지닌 서버로 구성 되었을 경우 부하분산이 효율적으로 되지 못할 수 있는 것이다. Weighted Least-Connection Scheduling (가중치 기반 최소 접속 스케쥴링) 가중치 기반 최소 접속 스케쥴링은 최소 접속 스케쥴링의 한 부분으로서 각각의 실제 서버에 성능 가중치를 부여할 수 있다. 언제라도 가중치가 높은 서버에서 더 많은 요청을 받을 수 있다. 가상 서버의 관리자는 각각의 실제 서버에 가중치를 부여할 수 있다. 가중치의 비율인 실제 접속자수에 따라 네트웍 접속이 할당된다. 기본 가중치는 1이다. 클러스터의 기본적인 개념과 기타 필요한 지식을 알아보았다. 그리고 이제 마지막으로 공유 데이터 저장장치에 대해서 알아보겠다. 많은 서버가 있으면 모든 서버에 데이터가 동일한 데이터이어야 할 필요가 있다. 실제로 고객이 접속할 때마다 각 노드의 자료가 달라 다른 페이지가 보이거나 접속이 되었다 안되었다 한다면 그것은 클러스터링을 했다는 의미가 없을 것이다. 하지만 일반적인 생각으로 데이터를 모두 동일하게 한다는 것은 때마다 데이터를 백업해서 옮겨놓는 방식이 있는데 일방적인 자료 제공이라면 상관없지만 고객의 자료 업로드가 필요한 경우는 막막하게 된다. 이런 문제점을 해결하기 위해 많은 방식들이 논의되어 왔는데 이런 기술들을 소개하겠다. NFS (Network File System) NFS는 UNIX에서는 널리 알려진 시스템으로 내부적으로 다소 불안하고 여러 시스템으로 데이터를 복제하는 방법이 제공되지 않는다는 단점이 있다. 따라서 NFS를 사용할 경우 기본으로 지정된 파일서버가 죽을 경우 모든 클러스터링 서버가 죽을 수 있다는 단점이 있다. AFS (Andrew File System) http://www.angelfire.com/hi/plutonic/afs-faq.html AFS는 피츠버그에 위치한 Carnegie Mellon 대학의 Andrew Project에서 개발된 상업용 소프트웨어이다. NFS와 많은 공통점을 가지고 있지만, NFS의 최대 단점인 인증 부분을 Keberos 프로토콜을 기반으로 안정된 메카니즘을 제공한다. Coda Coda 파일 시스템은 현재 리눅스 커널과 함께 제공되는 Open Source 분산 파일 시스템이다. Coda는 AFS와 비슷한 시스템을 유지하면서도 단속적인 연산, 서버 측 복제, 부분적인 네트워크 실패시 연속 연산, 그리고 확장성, 대역폭 조정 기능을 제공하여 몇 가지 가용성 문제를 해결했다. Intermezzo 이 파일 시스템도 역시 Open Source 분산 파일 시스템이며, 고유 파일 시스템의 상위 계층에 위치하여 사용자가 고유 파일 시스템을 사용하여 데이터를 저장할 수 있게 해준다. Intermezzo는 Coda보다 최신 컴퓨팅 환경과 장비의 능력을 더 잘 이해하며, Coda와 마찬가지로 높은 가용성, 대규모 복제, 분리된 네트워크에 중점을 둔다. 하지만 아직은 베타 개발 단계에 있다는 점을 명심해야 할 것이다. GFS 리눅스를 위한 최고의 분산 파일 시스템 솔루션 중 하나로써 이 솔루션은 파일 시스템 소프트웨어뿐 아니라 하드웨어 지원을 요구한다. 그리고 클라이언트의 장애로 인한 저널링 및 복구기능을 지원한다.
RAID http://www.terms.co.kr/RAID.htm 하나의 디스크 장치가 여러대에 연결되어 있다면 공유되어있는 네트웍 뿐만이 아니라 물리적인 디스크 자체에도 많은 부하가 걸리게 되어 있다. 이런 점을 보완하기 위한 장치로써 여러개의 디스크를 하나의 디스크처럼 만들어주는 장치로, 디스크 장애로 인한 복구, 빠른 액세스, 백업등을 지원한다. 레벨에는 0,1,2,3,4,5 등이 있으며, RAID 5 가 가장 많이 쓰인다. 참고자료
글쓴이 : 정순권 님 ( fuga@hostinglove.com )
| ||||||||||||||||||||||||||||||||||||||||||||||||
클러스터링은 어떻게 보면 병렬 처리 기술의 일부에 속한다. 다른 기술과의 차이점은 자원을 공유하거나 복제하는 수준에 달려 있다. 가장 단순한 구조는 한 마더보드에 여러개의 프로세서를 유지하고 다른 기술을 공유하는 것이다. 가장 높은 수준은 분산프로세싱이 여러개의 컴퓨터를 사용하되, 시스템이 단일 서버로 취급되지 않는 것이다. 다음에 병렬프로세싱에 관련된 비슷한 기술들이 있다.
SMP(Symmetric Multiprocessing) : 대칭형 다중처리 SMP는 운영체계와 메모리를 공유하는 여러 프로세서가 프로그램을 수행하는 것을 말한다. SMP에서는 프로세서가 메모리와 입출력 버스 및 데이터 path를 공유하며, 또한 하나의 운영체계가 모든 프로세서를 관리한다. 보통 2개부터 32개의 프로세서로 이루어지며, 어떤 시스템은 64개까지 프로세서를 공유한다. SMP시스템은 보통 MPP시스템에 비하여 병렬 프로그래밍이 훨씬 쉽고, 프로세서간 작업을 분산(workload balance)시키는 것은 훨씬 용이하지만, 확장성은 MPP에 비하여 취약하다. 또한 많은 사용자가 동시에 데이터베이스에 접근하여 일을 처리하는 OLTP 작업에서도 강점을 보인다. SMP 컴퓨터에서 운영체계 자체는 애플리케이션을 구성하는 개별적인 프로세스를 사용 가능한 CPU간에 분배한다. Windows NT는 가중치가 매우 높은 스레드를 기반으로 하고, 리눅스는 가중치가 매우 적으므로, 두가지 모두 SMP하드웨어에 아주 적합하다. 2~4개의 프로세서를 가지는 SMP 시스템은 구축하기 쉬우나 그 이상은 힘든데, 이것은 SMP 시스템자체가 단일의 I/O와 메모리를 공유해야 하기 때문이다. 이것이 바로 시스템의 병목현상을 일으키는 주 원인이기 때문에 오히려 이 이상의 CPU확장은 성능 저하의 원인이 될 수도 있다. 실제로 2CPU SMP 시스템과 4CPU SMP 시스템의 성능차이는 크지 않다. 위와 같이 설명되어지는 것이 일반적인 서적이나 매뉴얼에 나와 있는 설명이다. 실제로 이런 설명을 이해할 수 있는 사람은 몇 명되지 않을 것이다. 그럼 SMP는 무엇인가? 하나의 일을 여럿이서 나누어서 하는 것이다. 그러나 일을 주는 사람과 일을 받아 나가는 사람은 한 사람밖에 없는 것이다. 그러므로 중간에 일을 실제로 하는 사람이 많으면 일을 주고 받는 사람이 지치게 될 수밖에 없을 것이다. * OLTP : OLTP[오엘티피]는 일반적으로 은행이나, 항공사, 우편주문, 슈퍼마켓, 제조업체 등을 포함한 많은 산업체에서 데이터 입력이나 거래조회 등을 위한 트랜잭션 지향의 업무을 쉽게 관리해주는 프로그램이다. [대칭형 다중처리]
NUMA (Non-Uniform Memory Access) : 비균등 메모리 억세스 SMP System에서 가장 큰 문제점은 I/O와 메모리 엑세스의 병목 현상이었다. 즉 일주는 사람과 다 된 일을 받아 가는 사람이 너무 바빠서 중간에 실제적으로 많이 확보된 인부를 활용하지 못하는 상황이다. 하지만 이런 경우 각각의 인부에게 한사람씩 더 주어 자신의 일을 미리 미리 받고 자신이 하고 난 일을 임시로 보관해 둘 수 있는 장소가 있다면 이런 문제는 해결 될 수 있을 것이다. 바로 이런 SMP의 단점을 해결한 것이 바로 NUMA 기술이다. NUMA는 몇 개의 마이크로프로세서들 간에 중간 단계의 공유 메모리를 추가함으로써, 모든 데이터 액세스가 주버스 상에서 움직이지 않아도 되도록 하는 것이다. NUMA는 하나의 상자 속에 있는 클러스터로 생각할 수 있다. 클러스터는 대체로 마더보드 상의 하나의 공유 메모리 (L3 캐시라고도 부른다)로 향하는 로컬버스에, 서로 연결된 네 개의 마이크로프로세서들로 구성된다. 이 유니트는 모든 클러스터들을 서로 연결하는 공용 버스 내에서 SMP를 구성하기 위하여 비슷한 유니트에 추가될 수 있다. 이러한 시스템은 대체로 16~256개의 마이크로프로세서를 가지고 있다. SMP 시스템에서 실행되는 응용프로그램에게는, 모든 개별 프로세서 메모리들이 하나의 단일 메모리인 것처럼 비쳐진다. 프로세서가 어떤 메모리 주소에 있는 데이터를 찾을 때, 그것은 마이크로프로세서 그 자체에 붙어 있는 L1 캐시를 먼저 찾은 다음, 근처에 있는 다소 큰 L2 캐시 칩을 찾는다. 그 다음에는 다른 마이크로프로세서 인근에 있는 원격 메모리의 데이터를 찾기 전에, NUMA 구성에 의해 제공되는 제3의 캐시를 찾는다. NUMA에게는, 이러한 클러스터들 각각이 서로 연결된 네트웍 내에 있는 하나의 노드들 처럼 비쳐진다. NUMA는 모든 노드들 상에 있는 데이터를 계층 체계로 유지한다.
MPP (Massive Parallel Processing) MPP 시스템은 보통 하나의 CPU, 하나의 Memory, 하나의 OS로 구성된 여러 Node들의 집합으로 구성되어 있다. MPP 시스템은 단일 OS하에서 운영되지 않으므로 Hardware Coherency를 사용할 수 없으며 Message-passing방법을 사용한 Software Coherency를 사용한다. Software Coherency는 Hardware Coherency에 비해 수백 내지는 수천배의 지연시간(latency)을 허용하며, 따라서 수백 내지 수천개의 프로세서를 사용하여 시스템을 구성하기가 쉽다. 이러한 지연시간으로 인해 MPP 시스템상에서 높은 Performance를 얻을 수 있는 어플리케이션은 각 노드간에 교환되는 데이터를 최소화 할 수 있도록 잘 분리되는 것이라야 한다.MPP 시스템은 Hardware Coherency나 Shared Memory를 구현해야 할 필요가 없기 때문에 시스템 개발자에게는 구현하기 쉬운 장점이 있으나 어플리케이션 개발자는 Coherency구현을 위한 Message Passing 및, 퍼포먼스를 위한 어플리케이션 분산등을 고려하여 작성해야 하는 어려움이있다. 이러한 이유로 인해 데이터 공유가 필수적이고 빠른 응답시간을 요구하는 OLTP 어플리케이션들은 MPP 시스템에 적합하지 않으며, 빠른 응답시간을 요구하지 않고 어플리케이션의 각 시스템에서 데이터 요구가 분리되어 있는 의사결정 지원 시스템(DSS : Decision Support System), VOD(Video On Demand) 시스템등에 MPP시스템이 유용하다. 대규모의 병렬 시스템은 주로 계산 위주의 고급 연산에 사용되고, 현재 세계에서 가장 빠른 컴퓨터는 수학적 모델을 통해 핵 폭발을 시뮬레이터하는 MPP 시스템이다. [MPP]
| ||||||||||||||||||||||||||||||||||||||||||||||||
RAID 0 RAID-0는 전형적인 Parity가 없는 striped disk drive들의 non-redundant group으로 정의된다. RAID-0 array는 보통 I/O intensive application을 위한 large stripes로 구성되는데, 종종 data intensive application의 single-user를 위한 synchronized spindle drive들을 이용한 sector-stripe으로 구성할 수도있다. RAID-0는 redundancy를 지원하지 않기 때문에 만일 Array내의 하나의 drive가 장애를 일으키면, Array 전체가 장애를 일으키게 된다. 그러나 RAID-0는 모든 Array type중 가장 빠르고 data저장 효율이 높다.
RAID 1 Disk Mirroring이라 불리는 RAID-1은 data를 중복 저장하도록 디스크드라이브들을 쌍으로 구성한 것으로 서버쪽으로는 하나의 드라이브로 인식된다. RAID-1은 striping은 사용되지 않는 반면, 여러개의 RAID-1 array들이 서로 striped되어 mirrored drives pair들로 구성된 하나의 대용량 array로 구성 시킬 수 있으며, 이를 "Dual-level array" 또는 RAID-10이라 부른다.Write는 Mirrored Pair인 두개의 Drive에 동시에 저장되어 각 Drive가 동일한 정보를 저장하게 된다. 그러나 각 Drive는 Simultaneous Read Operation을 수행할 수 있다. 따라서, 각 Drive의 Read Performance는 두배로 되고 Write Performance는 변화가 없게 된다. RAID-1은 Redundant를 가진 Array중에서는 최고의 Performance를 보이며, 특히 Multi-user Environment에서 유용하다.
RAID 3 RAID-3는 RAID-2처럼 Sector-striped data를 Drive Group에 걸쳐 저장하지만, Group내의 하나의 Drive는 Parity Information만을 저장하도록 지정된다. RAID-3는 Error Detection을 위해서는 각 sector에 embbed된 ECC에 의존한다. Hard Drive가 장애를 일으킬 경우, Data 복구는 남아 있는 Drive상에 기록된 Information의 Exclusive OR(XOR)연산을 통하여 이루어진다. Records는 전형적으로 모든 Drive에 걸쳐 있기 때문에, Data Intensive 환경에 적합하다. 각 I/O은 Array내의 모든 Drive들을 액세스하기 때문에, RAID-3 Array는 I/O을 Overlap시킬 수가 없고 따라서, RAID-3는 long record의 Single-user, Single-tasking 환경에 적합하다. 그러므로 Short record에서의 성능 저하를 피하기 위해서는, RAID-3는 Synchronized-spindle drives가 필요하다.
RAID 5 종종 Rotating Parity Array라 불리는 RAID-5는 RAID-4에서 하나의 전용Parity Drive를 설정함으로써, Parity Update가 한 Drive에서 이루어지므로 생기는 Write Bottleneck을 피하기 위하여 만들어진 RAID Array이다. RAID-5는 RAID-4처럼 large-stripe이 사용되어 multiple I/O operation이 overlap되도록 하고 있다. 그러나, RAID-4와는 다르게, 각 Drive들이 일련의 서로 다른 stripes들에 대한 parity를 돌아가면서 저장하게 된다. 따라서, 전용 parity Drive가 없기 때문에 모든 drive들이 데이타를 저장할 수 있고, Read operation이 모든 drive에 걸쳐 overlap될 수 있다.Write Operation은 전형적으로 single data drive를 액세스하며 그 record에 대한 parity drive를 액세스한다. 따라서, RAID-4와는 달리 서로 다른 records들이 해당 parity들을 서로 다른 drive들에 저장하기 때문에, Write Operation도 overlap이 가능하다. RAID-5는 RAID-1이 모든 데이타를 redundant copy하는 것과는 달리, parity information만을 저장하기 때문에 RAID-1에 비하여 Storage Efficiency를 높일 수 있다. 결과적으로 RAID-5 Array는 어떤 수의 Drive도 연결이 가능하고, 각 Drive들은 Parity information 저장 부분만을 제외하고는 모두 data storage로 활용될 수 있다. 즉, RAID-5는 RAID-1보다 저장 장치를 효율적으로 극대화 시킬 수 있다. 그러나 performance에서는 손실을 감수 하여야 한다. Data가 RAID-5 Array에 쓰여질 때, Parity information 또한 Update되어야 하는데, 이는 Write Operation에 의하여 어떤 data bit들이 바뀌었는지를 찾아내어 이에 해당하는 parity bits들을 바꿈으로써 Update된다. 이는 overwritten될 old data를 먼저 읽고, 이것이 새로 overwrite될 새로운 데이타와 XOR 연산을 함으로써 수행된다. 이것은 바뀐 모든 bit의 position에서 1이 되는 bit mask를 만들게 되고, 이 bit mask가 parity drive로부터 읽어 들인 old parity information과 XOR연산을 수행한다. 이 결과, Parity information내에 있는 해당 bit를 변화 시킨다. 이렇게 하여 Update된 Parity는 Parity Drive에 write back된다. 그러므로, write-request하는 모든 Application에 대하여 RAID-5 Array는 두개의 Read, 두개의 Write와 두개의 XOR operation을 수행하여야만이 원래의 write가 완료된다. RAID-1에서의 redundant data에 비하여, Parity를 저장하는 RAID-5는 위와 같이 보다 많은 연산을 행하게 되며, write operation 중에 parity information을 재생하는데 추가적으로 시간이 소요된다. 이러한 이유 때문에 RAID-5는 RAID-1에 비하여 write performance가 약 3/5~1/3 수준밖에 되지 않는다. 이 때문에, RAID-5 Array는 결코 Software적으로 사용되지 않으며, 아울러 디지탈 비디오 캡쳐와 같이 write performance가 중요한 Application에는 사용되지 않는다.
| ||||||||||||||||||||||||||||||||||||||||||||||||














20세기 중반 이후로 통신망 기술, 교환 기술, 전송 기술의 통신 기술과 고성능 및 지능형 컴퓨터 기술, 소프트웨어 기술 그리고 단말 기술의 급격한 발달로 정보통신 발전에 지대한 영향을 주었고, 세계 각국은 자국의 미래 정보통신의 사활이 초고속통신망 구축에 달려 있음을 인식하고 통신망 구축에 박차를 가하고 있다.
국내도 마찬가지로 국가의 정보통신 사활이 이에 있음을 인식하고 정부 주도하에 초고속통신망 구축을 진행중에 있으며, 현재 일부 지역에 초고속통신망 시범 서비스를 실시하고 있다. 또한 앞으로의 각국은 정보통신의 발전이 초고속통신망 구축과 더불어 인터넷으로의 발전을 예상하고 있으며, 세계 각국은 인터넷의 접속을 통하여 각종 최신의 정보를 수집하고, 서로 정보를 교환하고 있다. 이러한 통신망으로의 발전에 힘입어 사용자들은 음성 및 비음성 등의 다양한 멀티미디어 정보 획득과 유통에 상당한 편익을 누리는 반면에 이의 역기능인 내부 네트워크의 자원 및 정보에 대한 해커들의 불법 침입 및 위협이 날로 증가하고 있다.
인터넷에 연결하여 사용하는 내부 네트워크의 자원 및 중요한 정보등을 해커로부터 보호하기 위해 방화벽 시스템에 대한 연구가 국내외에서 활발히 진행되고 있으며, 많은 상용 제품들이 시판되고 있다. 따라서 인터넷 등과 같은 외부 네트워크에 연결된 내부 네트워크를 보호하기 위해서는 네트워크를 연결해주는 장치에서 입출력되는 패킷을 분석하여 패킷 트래픽을 제어 및 차단하는 방화벽 시스템을 사용하면 네트워크를 보다 안전하게 보호할 수 있다.
지금부터 얘기 할 내용은 제 2장에서 인터넷 환경 하에서의 전반적인 보안문제를 설명하고 제 3장에서는 방화벽 시스템에 대한 일반적인 개요 및 방화벽 시스템 설계 시 고려되어야 할 사항에 대해 설명하고, 제4장은 방화벽의 종류에대해서 설명하고, 마지막으로 제 5장에서 결론을 맺는다. 그리고 APPENDIX에서는 최근 가장 큰 Hacking의 주류로 떠오르고 있는 IP Spoofing과 SYN Flooding Atack에 대한 전반적인 설명과 그 대응책에 대해 간단히 설명하고 마지막으로 Fwalls-FAQ@iwi.com 의 Marcus J. Ranum 이 관리하는 FIREWALL FAQ를 번역한 자료를 첨부 한다.
2. 인터넷 보안
1) 자원보호
- 망보안(Network Security)
■ 정보 보안(Information Security)
Security
- 데이터 무결성(integrity)
- 인증되지 않은 접근 방지
- Spoofing(속임 예:IP Spoofing)또는 도청(Audit)방지
- 서비스를 혼란 시키는 것을 방지
- 보안에 대한 절대적인 대책은 없다. 다만 범죄를 더욱 어렵게 함으로써 범죄 발생을 억제하거나 저하시키는 방향으로의 대책이 최선의 대책이다.
Requirement for Security
가) 물리적인 보안
컴퓨터, 자기테이프,디스크외에 네트웍 환경에서의 물리적 보안으로는 네트웍의 하부구조를 구성하는 케이블, 브릿지,라우터들에 적용된다. 실상 물리적 보안은 방화벽을 구성하고 보다 안전하게 유지 하는 것 보다 더 중요할 수 있다. (예: 라우터의 라우팅 테이블의변조 및 조정 또는 랜케이블의 도청)
나) 추상적 자원의 보호
물리적 자원의 보호보다 더 어렵다.
- 데이터 무결성(Data integrity) : 정보를 인증되지 않은 변경으로부터 보호 하는 것
- 데이터 가용성(Data Availability): 외부 사용자가 네트웍 트래픽을 포화시킴으로써 합법적인 데이터 접근을 방해할 수 없도록 보장
- Privacy의 보장 : 인증되지 않은 청취로 부터의 보호
(예)
① ACDC( image viewer)프로그램의 삭제 - 멋진 그림들을 더 이상 불 수 없음 -> 정보 보안의 차원에서 보면 데이터 가용성의 침해 또는 웹서버에 엄청난 양의 네트웍 트래픽을 부과하여 다른 사용자들의 접근이 불가능하게 함(Overflow) -> 정보 보안의 차원에서 보면 데이터 가용성의 침해
② 순이가 철수에게 "나 너 사랑해 !" 라는 내용의 전자메일을 보냄 --> 순돌이가 이를 중간에서 Hijacking 하여 "난 순돌이를 더 사랑해 !" 라고 순이의 메일을 변조해서 철수에게 보냄 --> 철수와 순이의 관계는 그날로 종지부를 찍게됨 : 데이터 무결성(Data integrity)이 침해 받은 사례
③ 용길이가 성민이의 나우누리 패스워드를 알아내고 나우누리에 접속해 야한 글을 공공 게시판에 올려놓음 : 성민이의 프라이버시가 침해당함
2) 정보 정책의 필요성
네트웍 보안 이전에 실시해야 할 일
가) 해당 네트웍의 위험 요소를 평가
나) 정보 접근과 방어에 관한 정책을 개발
어떤 보안 방식에 있어서도 인간은 일반적으로 가장 취약한 부분이다. 악의가 있거나 부주의하거나 조직의 정보 정책을 알지 못하는 고용자가 가장 뛰어난 보안을 손상 시킬 수 있다. 결국 보안의 완결은 보안 및 보안 정책에 대한 지속적인 교육과 의식화가 반드시 필요하다.
3) 인터넷에서의 보안문제
인터넷에서의 보안 문제는 첫째, TCP/IP 자체가 보안에 대해 취약하기 때문(즉 보안을 고려해 프로토콜이 디자인되지 못했다.) 둘째, 인터넷이 라우터들의 집합이기 때문에 데이터 전송시 송신측과 수신측 이외에 데이터를 라우팅하는 다른 조직들의 라우터에 의존해서 데이터가 전달되며 각각의 라우터에 대한 제어를 송/수신측에서 관리 할 수 없기 때문에 발생한다.
4) 인터넷 보안 기법
- 권한(Authorization), 인증(Authentication), 무결성(Integrity) Authentication mechanism : 신원(신분) 확인에 대한 문제
-User Authentication 예) Nownuri login : peter password: *********
-IP Source Authentication : IP Spoofing을 통해 특정 네트웍에 인증된 IP로 Spoofing하여 접근 가능 - 결국 IP Source Authentication은 불완전한 인증 메카니즘 - 상호인증(Mutual Authentication) Source와 Destination을 서로 확인하기 위한 메카니즘으로 Public key encryption system을 사용한다. 서로 연결을 원하는 상대방은 메시지를 암호화(Encryption) 하고 해독하는데 사용하는 두 개의 키를 할당 받아야 한다 (비대칭 알고리즘).
상대방은 자신의 공중키(Public key)를 공중키 데이터 베이스에 등록 공고하고 데이터 암호화를 위한 비밀키는 보관한다.
비밀키에 의해 암호화된 데이터는 암호화된 비밀키에 합당한 공중키로 해독된다. 예를들어 A라는 사람과 B라는 사람은 서로 통신하기 이전에 공중 키 데이터 베이스에 각각 자신의 공중키를 등록 공고한다.
A라는 사람은 자신의 비밀 키를 이용해 데이터를 암호화해서 B에게 전자메일을 통해 전송한다. B라는 사람은 공 중키 데이터 베이스로부터 A의 공중키를 얻어은 후 이를 이용해 A로부터 전송된 암 호화된 데이터를 해독한다. 암호화된 데이터가 A의 공중키로 해독된다면 해당 데이터 는 A로부터 전송된 데이터가 확실함을 확인할 수 있다. 만약 A의 비밀키가 알려진다면 물론 상호인증에 대한 신뢰성에 피해가 예상된다. 그러나 현재로써는 최상의 암호화 메카니즘으로 PGP(Pretty Good Privacy)라는 알고리즘이 대표적인 공중키 암호 화 시스템으로 평가받고 있으며 키 인증에 대한 활발한 연구가 진행중에 있다.
나) Privacy 보호
개인의 프라이버시를 보호하기 위해 암호화 기법이 사용된다. 주로 사용되는 암호화 기법으로는 Public Key Encryption 방법이 주로 사용된다.
일반적인 암호화 기법은 암호화 된 데이터의 해독을 위해서는 암호화시 사용된 키가 해독시에도 사용되는 대칭형 암호화 시스템이 주로 사용되었다(예: Unix login password). 그러나 최근에 PGP(Pretty Good Privacy)라는 공중키 암호화 시스템이 주로 사용된다. 이 암호화 시스템은 비대칭 암호 화 시스템으로 암호화시 사용되는 키와 해독시 사용되는 키가 서로 다른 키라는 특징을 같는다. 예를 들면 A라는 사람이 B라는 사람에게 메일을 전송할 경우 A는 B의 공중키 를 이용해 메일을 암호화해 전송한다. B는 자신의 비밀키를 이용해 데이터를 해독하게된 다.
결국 데이터 전송도중 발생할 수 있는 데이터 Intercept나 변조에 대해 최고의 대안 을 제공할 수 있다. 메시지 암호화는 비밀 보장 뿐만아니라 송신자 인증을 위해서 두 번 암호화 될 수 있다. 송신자가 송신자의 비밀키를 이용해 메시지를 암호화(송신자에 대한 확인)한 후 암호화된 데이터를 수신자의 공중키를 이용하여 다시한번 암호화한다. 수신 자는 우선 송신자의 공중키로 수신된 데이터를 해독한다(송신자 인증). 그리고 해독된 데 이터를 자신의 비밀키를 이용해 마지막으로 해독한다(Privacy).
현재 공중키 암호화 방 식으로 PGP가 메일 송수신시 대중적으로 사용되고 있으나 미국에서는 PGP 보안 시스 템에 대해 무역 금지 조치를 내려 미국외의 지역 외에서는 작은 키값의 PGP version만 이 사용되고 있다. PGP freeware를 이용해 보시기 바랍니다. :>
- 공중키 암호화와 같은 기법들은 인중, 권한, 비밀 보장과 같은 문제들을 해결하는데 사용될 수 있다. 이같은 기법들을 사용하기 위해서는 클라이언트와 서버 소프트웨어를 모두 변경해야 한다.
다) Access Control(availability)
Firewalls의 사용
5) 다중 연결과 취약 링크
외부와 다중 연결을 갖는 조직이 방화벽 구축을 계획하고 있다면 그 조직의 모든 외부 연결에 방화벽을 설치하여야 하며 보안 경계가 효과적 이도록 하기 위해서는 모든 방화벽들 이 동일한 접근 제약을 사용하도록 조정해야 한다.
그렇지 않을 경우 한 방화벽들의 제약 을 회피하기 위해 우회하여 다른 방화벽을 통해 접근 할 수 있게된다. 이는 "보안 시스템 이 가장 취약한 지점만큼만 강하다"는 최약 링크의 공리(Weakest link axiom)로 해당 조직의 보안 시스템의 수준을 평가하고 분석하는 것을 난해하게 한다.
6) 방화벽 구현과 고속 하드웨어
방화벽의 구현은 기본적으로 컴퓨터들간의 권한이 없는 모든 통신을 막도록 설계되어져야 하며 외부에서 내부망으로 또 내부에서 외부로의 모든 트래픽이 보안 시스템을 반드시 경 유할 수 있도록 디자인 되어야 한다.
실제 방화벽 구현에 있어서는 망기술, 연결의 용량, 트래픽 부하, 조직정책들이 해당 조직에 적합하게 하나의 완결된 구조로 구현되어야 한다. 이를 위해서는 요구되는 처리능력을 파악하는 것이 중요하며 연결의 속도와 같은 속도로 데이터그램을 처리할 수 있어야 한다.
만약 방화벽이 데이터그램을 전송할지 여부를결 정하기 위해서 버퍼에 데이터그램을 지연시키면, 방화벽은 재전송으로 압도될 것이고 결국 버퍼는 넘쳐 방화벽의 Overflow를 초래하게 될 것이다. 결국 망속도로 동작하기 위해 서 방화벽은 그 작업에 최적인 하드웨어와 소프트웨어를 갖고 있어야 한다.
3. 방화벽 시스템의 개요
1) 방화벽 시스템 설계 시 고려 사항
인터넷 등의 외부 전산망에 연결된 내부 네트워크를 보호하기 위해서 방화벽 시스템을 구축하고자 할 경우 고려해야 할 사항은 다음과 같다.
가) 어떤 자원을 보호할 것인가 ? 보호하고자 하는 하드웨어, 소프트웨어, 각종 중요한 정보, 시스템 사용자, 시스템 관리에 대한 도큐먼트 등을 정의하고, 방화벽 시스템 구축 시 이를 고려하여야 한다.
나) 어떤 위협이 존재하는가 ? 보호하고자 하는 자원 및 정보들에 대한 위협이 어떤 것들이 있는가를 분석한다.
다) 자원이 얼마나 중요한가 ? 보호하고자 하는 자원의 중요성이 어느 정도인가를 분석한다.
라) 어떤 사용자를 인가할 것인가 ? 사용자 계정을 가진 사용자만이 네트워크를 사용하도록 할 것인지 비인가자라도 제한된 자원에만 사용하도록 할 것인지를 결정한다.
마) 요구되는 응용 및 서비스는 무엇인가 ? 보호하고자 하는 네트워크에서 사용 가능한 응용 및 서비스들이 어떤 것들이 존재하는지를 분석한다.
바) 비용 대 효과 측면에서 보호하기 위해 실현될 수 있는 기법은 무엇인가 ? 화일이나 디렉터리 등은 액세스 제어에 의해 보호하고, 네트워크 장비 및 호스트의 보호는 방화벽 시스템 사용 등의 보호 기법을 고려한다.
사) 해커 등의 불법 침입 감지 시 취해야 할 행동은 무엇인가 ? 해커 등과 같은 불법 침입자가 시스템 내부에 침입했을 때 취해야 할 대응책을 마련해야 한다.
아) 정기적으로 시스템을 점검한다. 보호하고자 하는 네트워크 및 자원들에 변화가 일어났는지 정기적으로 점검하고 기록한다. 이러한 행위는 시스템 관리자 및 네트워크 관리 시스템에 의해 자동적으로 실행한다.
방화벽 시스템을 설계할 때 상기와 같은 사항을 고려하여 보다 효과적으로 해커등과 같은 불법 침입자로부터 내부 네트워크를 보호할 수 있도록 해야 한다. 일반적으로 방화벽 시스템을 설계할 때 사용하는 패러다임은 두가지로 구분되는데
첫째로는, 내부 네트워크로의 진입을 명확하게 허용하지 않는 트래픽은 내부 네트워크로의 진입을 방지하는 것이고,
둘째로는 첫번째 패러다임의 반대 개념으로 명확하게 내부 네트워크로의 진입이 방지되지 않는 트래픽은 네트워크로의 진입을 모두 허용한다.
2) 방화벽 시스템이 방어할 수 있는 것
방화벽 시스템은 인터넷과 같은 외부 네트워크와 내부 네트워크 사이에 놓이며, 외부 네트워크로부터 내부 네트워크로의 침입을 감지하여 정보 및 자원들을 보호한다. 즉, 외부 네트워크에서 내부 네트워크로 액세스하 기 위해서는 방화벽 시스템을 통과하여야만 내부 네트워크로 진입할 수 있도록 하여 내부 네트워크에 존재하는 정보 및 자원들에 대한 트래픽을 사전에 방어하는 것이다.
3) 방화벽 시스템이 방어하지 못하는 것
방화벽 시스템은 내부 사용자가 내부 네트워크에 존재하는 중요한 정보를 디스크 혹은 테이프와 같은 매체를 통해 가지고 나가는 것은 방어하지 못한다. 또한 외부 네트워크로부터 내부 네트워크로 비 인가된 다이얼 모뎀을 통한 접근을 방어하지 못하며, 바이러스 혹은 정보 지향적인 공격에 대해서는 방어하지 못한다. 따라서 방화벽 시스템은 보호하고자 하는 네트워크의 자원이나 정보들을 완벽하게 불법 침입자로부터 보호할 수 없으며, 다만 외부 네트워크에서 내부 네트워크로의 진입을 1차로 방어해주는 기능을 수행 한다.
4) 위험 지역의 축소
인터넷 및 외부 네트워크에는 많은 해커가 존재하며, 이들은 언제 어느 통신망에 접속하여 내부 네트워크에 존재하는 자원 및 중요한 정보를 파괴, 변경, 갈취 등을 할지 예측할 수 없다. 따라서 인터넷 등 외부 네트워크에 연결된 모든 내부 네트워크는 해커들이 침입할 수 있는 위험 지역(Zone of Risk)에 놓이게 된다. 이러한 위험 지역으로부터 내부 네트워크를 분리 시키고자 하는 것이 방화벽 시스템이다.
5) 방화벽 시스템의 정보보호 서비스
방화벽 시스템의 기능을 지원하기 위해서는 다음과 같은 정보보호 서비스가 필요하다.
-사용자 인증
인터넷 상에서 Sniffer와 같은 네트웍 도구를 이용해 사용자 계정과 비밀번호를 알아 낼 수 있기 때문에 이러한 문제를 해결하고 방화벽이 설치된 내부망의 보안을 강화하기위해 보다 강력한 인증 수단이 요구된다. 이를 위해서 One-Time Password 인증 방법등이 많이 사용된다.
-접근제어
허용된 시스템에서 접근 요청을 하는지 그리고 통신 대상인 목적지 시스템이 원하는 곳인지 검사하고 허용 여부를 결정하며 네트웍 자원에 대해서 접근할 자격이 있는지를 검사한 후 접근 여부를 결정함으로써 불법 침입자에 대한 불법적인 자원 접근 및 파괴를 방지한다.
-트래픽 암호화
인터넷의 경우 TCP/IP 프로토콜을 사용하여 암호화되지 않은 Plain text형식으로 되어있기 때문에 데이터 내용에 대한 보안이 이루어 지지 않아 제 3 자에게 트래픽이 노출된 위험이 있다.이를 방지하기 위해 전송되는 트래픽을 암호화한다. 주로 사용되는 알고리즘은 DES, RSA, IDEA 등이 있다.
-트래픽 로그
외부와 내부네트웍 사이를 통과하는 모든 트래픽에 대해서 로그 파일에 기록한다.
-감사 추적 기능
내부 네트웍의 누가,언제,어떤 호스트에서 어떤 일 들을 했는가를 기록한다. 정보는 내부 네트워크의 해커 및 외부의 불법 침입자들이 시스템 내의 침입 여부를 파악할 수 있으며, 침입했을 때 적절히 대처할 수 있도록 해준다.
6) 방화벽 구축 시 장점
방화벽 구축시의 장점
- 취약한 서비스로부터 보호 방화벽은 크게 네트워크 보안을 증가시키고
원천적으로 불안전한 서비스를 필터링함으로써 서브네트 상에 있는 호스트에 위험을 감소시킨다. 선택된 프로토콜만이 방화벽을 통과 할 수 있기때문에, 서브네트 네트워크 환경은 위험에 덜 노출된다.
- 방화벽은 호스트 시스템으로의 액세스를 컨트롤할 수 있다.
예를 들면,외부 네트워크에서 한 호스트로 접속할 수 있는데, 원하지 않는 액세스는 효과적 으로 차단해 준다. 사이트는 메일 서버같은 특별한 경우를 제외한 외부로 부터의 액세스를 차단한다.
● 보안의 집중
방화벽은 대부분의 수정된 소프트웨어와 추가되는 보안 소프트웨어를 많 은 호스트에 분산시키지 않고 방화벽에 설치할 수 있다는 점에서 경제적이다. 특별히, one-time 패스워드 시스템과 다른 추가적인 인증 소프트웨를 방화벽에 설치할 수 있다.
● 확장된 프라이버시
일반적으로 해가 없다고 생각되는 것들이 실질적으로 프라이버시 침해에의 결정적인 요인이 될 수 있다. 방화벽을 사용한 사이트(호스트와의 연결 시스템)들은 핑거(finger)와 dns(domain named service)같은 서비스를 막고자 한다. 핑거는 마지막 로그인 시간과 메일 도착 여부, 다른 아이템들을 읽었는지 등 해당 계정의 사용자 정보를 디스플레이 하는 명령어다. 이런 편리한 '핑거' 서비스는 해커(시스템 침입자)들에게도 그 시스템이 얼마 나 자주 사용되는지, 시스템에 연결된 사용자가 있는지, 그리고 침해될 수 있는지에 관한 정보를 보여준다. 따라서 방화벽은 가능하면 핑거를 이용하는 것을 막음 으로써 침입자들의 접근 요인을 막고자 하는 것이다.
- 방화벽은 또한 사이트 시스템에 관한 dns 정보를 막고자 하는데 사용된다.
그래서 사이트의 이름과 ip어드레스를 인터네트 호스트에서 유출되지 않게한다. 어떤 사이트들은 이러한 정보를 막음으로써 침입자에게 유용하게 사용 될 수 있는 정보를 숨길 수 있다.
● 네트워크 사용과 비사용에서의 로그인과 통계자료 제공
인터네트 안밖으로의 모든 액세스가 방화벽을 통과 한다면, 방화벽은 액세스 정보를 기록할 수 있고 네트워크 사용에 관한 유용한 통계자료를 제공한다. 의심스러운 활동이 있을때 적당한 알람기능을 가진 방화벽은 방화벽과 네트워크가 침입 시도를 받고 있는지 또는 침입 되었는에 대한 세부사항을 제공해 준다
● 정책 시행
마지막으로 이것이 가장 중요한데, 방화벽은 네트워크 액세스 정책을 실행한다. 사실상, 방화벽은 사용자들과 서비스의 액세스를 컨트롤할 수 있다. 그래서, 네트워크 액세스 정책은 방화벽에 의해서 시행될 수 있게 된다. 그러나 방화벽이 없다면, 그러한 정책들은 전적으로 사용자들의 협조에 의존해야 한다. 사이트는 자신의 사용자들의 협조에 의존하여 보안을 유지할 수 있기 때문이다. 그러나 일반적으로 인터네트 사용자들에게는 적용되지 않는다.
4. 방화벽 시스템의 종류
방화벽 시스템은 OSI 참조 모델과 관련하여 방화벽 시스템이 동작하는 프로토콜 계층에 따라 분류 될 수 있다.
계층 3인 네트워크 계층과 계층 4인 트랜스포트 계층에서 패킷필터링 기능을 수행하는 스크리닝 라우터와 응용 계층에서 패킷필터링 기능과 인증 기능 등을 수행하는 응용 계층의 게이트웨이로 분류할 수 있다.
일반적으로 스크리닝 라우터를 설계할 경우 [명확하게 내부 네트워크로의 진입이 방지되지 않은 트래픽은 네트워크로의 진입을 허용] 하는 패러다임을 사용하고, 게이트웨이 혹은 proxy 서버의 경우 [내부 네트워크로의 진입을 명확하게 허용하지 않은 트래픽은 내부 네트워크로의 진입을 방지]하는 패러다임에 입각하여 설계한다.
1) 스크리닝 라우터(Screening Router)
스크리닝 라우터는 OSI 참조 모델의 계층 3과 계층 4에서 동작되기 때문에 계층 3과 4에서 동작하는 프로토콜인 IP(Internet Protocol), TCP (Transmission Control Protocol) 혹은 UDP(User Datagram Protocol)의 헤더에 포함된 내용을 분석해서 동작한다.
스크리닝 라우터란 네트워크에서 사용하는 통신 프로토콜의 형태, 근원지 주소와 목적지 주소, 통신 프로토콜의 제어 필드 그리고 통신 시 사용하는 포트 번호를 분석해서 내부 네트워크에서 외부 네트워크로 나가는 패킷 트래픽을 허가 및 거절하거나 혹은 외부 네트워크에서 내부 네트워크로 진입하는 패킷 트래픽의 진입 허가 및 거절을 행하는 라우터를 말한다.
이러한 진입 허가 혹은 거절 결정은 패킷필터 규칙에 따른 라우팅 테이블에 의해 결정된다. 일반 패킷과 특수한 프로토콜에 입각한 포트로 전송되는 패킷을 구별하는 능력 때문에 패킷 필터 라우터라고도 한다.
(그림 1)은 스크리닝 라우터(패킷 필터 라우터)의 위치 및 기능을 보여 준다.
가) 패킷 필터의 동작
스크리닝라우터로 연결에 대한 요청이 입력되면, IP, TCP 혹은 UDP의 패킷 헤더를 분석하여 근원지/목적지의 주소와 포트 번호, 제어 필드의 내용을 분석하고, 이들을 패킷 필터 규칙에 적용하여 계속 진입시킬 것인지 아니면 거절할 것인지를 판별한다. 연결 요청 패킷의 진입이 허가되면 이 후의 모든 패킷은 연결 단절이 발생할 때까지 모두 허용된다.
나) 패킷 필터 규칙
패킷 필터 규칙은 <표 1>과 같이 근원지 주소, 근원지의 포트 번호, 목적지 주소, 목적지의 포트 주소, 프로토콜 플래그, 행위(허가/거절) 등으로 구성된다. 이러한 패킷 필터 규칙이 정해지면 인터넷 주소에 적용하는 허가 /거절하는 조건의 순차적인 액세스 집합인 액세스 리스트를 정의한다.
스크리닝 라우터는 이러한 액세스 리스트를 가지고 프로그램 되며, 패킷을 허가 혹은 거절할 것인지를 액세스 리스트에 있는 행위에 대해서 순차적으로 결정하며, 패킷에 해당하는 액세스 리스트가 나타날 때까지 혹은 마지막 액세스 리스트에 도달할 때까지 순차적으로 점검한다.
방화벽 시스템을 실현할 경우 액세스 리스트의 점검 순서는 매우 중요하기 때문에 액세스 리스트의 점검 순서를 신중히 검토하여 사용한다.
<표 1. 패킷 필터 규칙>
* 장점
- 필터링 속도가 빠르고, 비용이 적게 든다.
. 네트워크 계층에서 동작하기 때문에 클라이언트와 서버에 변화가 없어도 된다.
- 사용자에 대해 투명성을 유지한다.
하나의 스크리닝 라우터로 보호하고자 하는 네트워크 전체를 동일하게 보호할 수 있다.
* 단점
- 네트워크 계층과 트랜스포트 계층에 입각한 트래픽만을 방어할 수 있다.
- 패킷 필터링 규칙을 구성하여 검증하기 어렵다.
- 패킷내의 데이터에 대한 공격을 차단하지 못한다.
- 스크리닝 라우터를 통과 혹은 거절당한 패킷에 대한 기록(log)을 관리 하기 힘들다.
2) Bastion 호스트
Bastion 호스트는 통신망을 보호하는데 중요한 방화벽 시스템으로 사용되며, 네트워크 관리자가 정기적으로 주의 깊게 감시 및 점검하여야 한다.
Bastion 호스트로는 상용 제품인 SPARCstation, IBM/AIX, NT Server 등이 사용될 수 있으며, 이들은 방어 기능이 철저히 구현된 호스트이다. 이러한 Bastion 호스트는 인터넷 등의 외부 네트워크와 내부 네트워크를 연결해 주는 방화벽 시스템 역할을 한다. 인터넷 사용자가 내부 네트워크로의 액세스를 원할 경우 우선 Bastion 호스트를 통과하여야만 내부 네트워크를 액세스하여 자원 및 정보를 사용할 수 있다.
해커 및 불법 침입자가 Bastion 호스트에 있는 중요한 정보를 악용하여 내부 네트워크로 접근하는 것을 방지하기 위해서는 Bastion 호스트 내에 존재하는 모든 사용자 계정을 지워야 하며, 중요하지 않은 화일이나 명령 및 유틸리티, IP forwarding 화일 그리고 라우팅 정보 등을 삭제하여야 한다. Bastion 호스트로의 입력시 강력한 인증 기법을 구현하여야 하며, Bastion 호스트는 내부 네트워크로의 접근에 대한 기록(log), 감사 추적을 위한 기록 및 모니터링 기능을 가지고 있어야 한다.
(그림 3)은 방화벽 시스템으로 동작하는 Bastion 호스트를 이용하여 외부 네트워크의 불법 사용자들로부터 내부 네트워크로의 접근을 방지하는 구성도를 나타낸 것이다.
* 장점
- 응용 서비스 종류에 보다 종속적이기 때문에 스크리닝 라우터보다 안전 하다.
- 정보 지향적인 공격을 방어할 수 있다.
- 각종 기록(logging) 정보를 생성 및 관리하기 쉽다.
* 단점
- Bastion 호스트가 손상되면 내부 네트워크를 보호할 수 없다.
- 로그인 정보가 누출되면 내부 네트워크를 보호할 수 없다.
3) Dual-Homed 게이트웨이
Dual-Homed 게이트웨이는 (그림 4)와 같이 두개의 네트워크 인터페이스 를 가진 Bastion 호스트를 말하며, 하나의 네트워크 인터페이스는 인터넷 등 외부 네트워크에 연결되며, 다른 하나의 네트워크 인터페이스는 보호하고자 하는 내부 네트워크에 연결되며, 양 네트워크간의 라우팅은 존재하지 않는다. 따라서 양 네트워크간의 직접적인 접근은 허용되지 않는다.
만약 라우팅이 가능하면 외부 네트워크로부터 내부 네트워크로의 액세스가 가능 하다. 라우팅이 없는 Dual-Homed 게이트웨이를 이용하여 인터넷 혹은 내부 네트워크의 정당한 사용자들이 응용 서비스를 제공받는 방법은 두가지로 구분되는데,
첫째 방법은 Dual-Homed 게이트웨이상에서 실행되며 서비스를 제공하는 proxy 서버를 사용하는 것이고,
두번째 방법은 응용 서비스를 제공해주는 Dual-Homed 게이트웨이에 직접 로그인한 다음 다시 내부 네트워크로 접근하는 것인데, 이 경우 강력한 인증 방법이 게이트웨이에 구현되어야 한다.
따라서 해커나 불법 침입자가 악용할 소지가 있는 명령어(suid, sgid 등), 유틸리티 및 불필요한 서비스, 프로그래밍 도구(컴파일러 등)를 이들이 사용할 수 없도록 Dual-Homed 게이트웨이에서 삭제하여야 하며, 라우팅이 되지 않도록 하여야 한다. 또한 로그인에 대한 기록 정보 및 감시 추적에 필요한 기록을 정확히 유지 관리하여야 한다. 외부 네트워크로부터 내부 네트워크로 진입하기 위해서는 Dual-Homed 게이트웨이를 통과하여야 한다.
* 장점
- 응용 서비스 종류에 좀더 종속적이기 때문에 스크리닝 라우터보다 안전 하다.
- 정보 지향적인 공격을 방어할 수 있다.
- 각종 기록 정보를 생성 및 관리하기 쉽다.
- 설치 및 유지보수가 쉽다.
* 단점
- 제공되는 서비스가 증가할수록 proxy 소프트웨어 가격이 상승한다.
- 게이트웨이가 손상되면 내부 네트워크를 보호할 수 없다.
- 로그인 정보가 누출되면 내부 네트워크를 보호할 수 없다.
4) 스크린된(Screened) 호스트 게이트웨이
스크린된 호스트 게이트웨이는 Dual-Homed 게이트웨이와 스크리닝 라우터를 혼합하여 사용한 방화벽 시스템이다.
방화벽 시스템의 구성 방법은 (그림 5)와 같이 인터넷과 Bastion 호스트 사이에 스크리닝 라우터를 접속하고, 스크리닝 라우터와 내부 네트워크 사이에서 내부 네트워크상에 Bastion 호스트를 접속한다.
인터넷과 같은 외부 네트워크로부터 내부 네트워크로 들어오는 패킷 트래픽을 스크리닝 라우터에서 패킷 필터 규칙에 의해 1차로 방어하고, 스크리닝 라우터를 통과한 트래픽은 모두 proxy 서버를 구동하는 Bastion 호스트에서 입력되는 트래픽을 점검하며, 스크리닝 라우터 혹은 Bastion 호스트를 통과하지 못한 모든 패킷 트래픽은 거절된다.
내부 네트워크로부터 인터넷 등으로 나가는 트래픽은 1차로 proxy 서버를 구동하는 Bastion 호스트에서 점검한 후 통과된 트래픽을 스크리닝 라우터로 보내고 스크리닝 라우터는 Bastion 호스트로부터 받은 트래픽을 인터넷등의 외부 네트워크로 송신할 것인지 결정한다.
Bastion 호스트와 스크리닝 라우터를 통과한 트래픽만이 외부 네트워크로 전달된다. Bastion 호스트는 외부 네트워크로 또는 외부 네트워크로부터의 서비스 요청을 허용할 것인지 아니면 거절할 것인지를 결정하기 위해서 응용 계층의 proxy 서버를 구동한다.
스크리닝 라우터의 라우팅 테이블은 외부 트래픽이 Bastion 호스트로 입력되도록 구성되어야만 하며, 이 스크리닝 라우터의 라우팅 테이블은 침입자로부터 안전하게 보호되어야 하고 비인가된 변환을 허용해서는 안된다. 만약 라우팅 테이블이 변환되어 외부 트래픽이 Bastion 호스트로 입력이 되지 않고 곧바로 내부 네트워크로 진입할 수 있다면 해커 및 불법 침입자는 내부 네트워크의 자원 및 정보를 변환, 파괴 등을 할 수 있다.
이와 같은 방화벽 시스템의 스크리닝 라우터에서는 정적 라우팅 테이블을 사용하는 것이 안전하다.
* 장점
- 2 단계로 방어하기 때문에 매우 안전하다.
- 네트워크 계층과 응용 계층에서 방어하기 때문에 공격이 어렵다.
- 가장 많이 이용되는 방화벽 시스템이며, 융통성이 좋다.
- Dual-Homed 게이트웨이의 장점을 그대로 가진다.
* 단점
- 해커에 의해 스크리닝 라우터의 라우팅 테이블이 변경되면 이들을 방어 할 수 없다.
- 방화벽 시스템 구축 비용이 많다.
5) 스크린된 서브네트 게이트웨이
인터넷과 내부 네트워크를 스크린된 게이트웨이를 통해서 연결하며, 일반적으로 스크린된 서브네트에는 방화벽 시스템이 설치되어 있으며, 인터넷과 스크린된 서브네트 사이 그리고 서브네트와 내부 네트워크 사이에는 스크리닝 라우터를 사용한다. 이와 같은 방화벽 시스템의 구성도는 (그림 6)과 같다.
스크리닝 라우터는 인터넷과 스크린된 서브네트 그리고 내부 네트워크와 스크린된 서브네트 사이에 각각 놓이며, 입출력되는 패킷 트래픽을 패킷 필터 규칙을 이용하여 필터링하게 되며, 스크린된 서브네트에 설치된 Bastion 호스트는 proxy 서버(응용 게이트웨이)를 이용하여 명확히 진입이 허용되지 않은 모든 트래픽을 거절하는 기능을 수행한다. 이러한 구성에서 스크린된 서브네트에 대한 액세스는 Bastion 호스트를 통해서만 가능하기 때문에 침입자가 스크린된 서브네트를 통과하는 것은 어렵다.
만약 인터넷을 통해 내부 네트워크로 침입하려고 한다면 침입자는 자기가 자유롭게 내부 네트워크를 액세스할 수 있도록 인터넷, 스크린된 서브네트 그리고 내부 네트워크의 라우팅 테이블을 재구성해야만 가능하다. 그러나 스크리닝 라우터가 존재하기 때문에 이는 힘들다.
비록 Bastion 호스트가 침해되었더라도 침입자는 내부 네트워크상에 존재하는 호스트로 침입해야 하고, 그리고 스크린된 서브네트를 액세스하기 위해서 스크리닝 라우터를 통과해야 한다.
* 장점
- 스크린 된 호스트 게이트웨이 방화벽 시스템의 장점을 그대로 가진다.
- 융통성이 뛰어나다.
- 해커들이 내부 네트워크를 공격하기 위해서는 방어벽을 통과할 것이 많아 침입이 어렵다.
- 매우 안전하다.
* 단점
- 다른 방화벽 시스템들 보다 설치하기 어렵고, 관리하기 어렵다.
- 방화벽 시스템 구축 비용이 많다.
- 서비스 속도가 느리다.
6) Proxy 서버/응용 게이트웨이
응용 게이트웨이 혹은 proxy 서버는 방화벽 시스템(일반적으로 Bastion 호스트)에서 구동되는 응용 소프트웨어를 말하는데 store-and-forward 트래픽뿐만 아니라 대화형의 트래픽을 처리할 수 있으며, 사용자 응용 계층 (OSI 참조 모델의 계층 7)에서 트래픽을 분석할 수 있도록 프로그램된다. 따라서 이것은 사용자 단계와 응용 프로토콜 단계에서 액세스 제어를 제공 할 수 있고, 응용 프로그램의 사용에 대한 기록(log)을 유지하고 감시 추적을 위해서도 사용될 수 있다. 응용 게이트웨이는 사용자 단계에서 들어오고 나가는 모든 트래픽에 대한 기록을 관리하고 제어할 수 있으며, 해커 및 불법 침입자를 방어하기 위해서 강력한 인증 기법이 필요하다.
응용 게이트웨이는 사용되는 응용 서비스에 따라 각각 다른 소프트웨어를 구현하여 사용하기 때문에 고수준의 보안을 제공할 수 있다.
네트워크에 첨가되고 보호가 필요한 새로운 응용 이 생기면 이를 위해 새로운 특수 목적용 코드를 생성해야 한다.
응용 레벨 게이트웨이를 사용하기 위해서 사용자는 응용 게이트웨이 장치에 로그인하거나 서비스를 이용할 수 있는 특수한 클라이언트 응용 서비스를 실현해야 한다. 각각 응용에 따라 다르게 사용하는 특수한 게이트웨이는 제각기 내부에 관리 도구와 명령 언어를 가지고 있다.
응용 게이트웨이는 실제 서버의 관점에서 볼 때 클라이언트처럼 동작하며, 클라이 언트 관점에서 볼 때는 실제 서버처럼 동작한다. 응용 게이트웨이의 실현 예는 TELNET 게이트웨이, FTP 게이트웨이, Sendmail, NNTP News Forwarder 등이 있다.
* 장점
- 응용 서비스마다 각각 다른 응용 게이트웨이를 구현하므로 보다 안전 하게 보호할 수 있다.
- 응용 사용에 따른 기록 및 감시 추적을 유지 관리 가능하다.
- 융통성이 좋다.
- 정보보호 서비스를 응용 게이트웨이에 구현 가능하다.
* 단점
- 응용 서비스마다 제각기 다른 응용 게이트웨이가 필요하다.
- 사용되는 응용 서비스가 증가할수록 구축 비용이 증가한다.
인터넷에 연결하여 사용하는 내부 네트워크의 자원 및 중요한 정보 등을 해커로부터 보호하기 위해 사용되고 있는 보안의 전반을 방화벽 시스템을 중심으로 살펴보고 이들의 기능 및 성능을 분석하였으며 각 각의 장단점을 제시하였다.
주어진 환경에 가장 적합한 방화벽 시스템을 구축하는 것은 많은 고려 사항으로 인하여 쉬운 일은 아니다. 이를 선택하기 위해서는 구축 비용 대 효과, 사용하는 네트워크 기술, 보호해야 할 정보, 보안 정책, 조직의 네트 워크에 대한 정책 등을 신중히 고려하여 자신의 네트워크에 가장 타당한 방화벽 시스템을 선택하여야 한다. 그러나 방화벽 시스템이 완벽하게 해커 및 불법 침입자로부터 내부 네트워크의 모든 자원 및 정보를 보호해 준다고 믿어서는 안되며, 단지 방화벽 시스템은 내부 네트워크를 보호하기 위한 1차 방어선으로 생각하고 암호화 기법 및 강력한 인증 서비스 등과 같은 안전한 정보 보호 서비스를 구현하여야 하며, 이와 더불어 가장 중요한 보안 정책이라고 할 수 있는 사용자 및 관리자들에게 보안 교육 등을 꾸준히 실시해야 하며, 관리자는 내부 네트워크 시스템을 정기적으로 점검함으로써 발생할 수 있는 모든 면을 미리 대비하도록 하여야 한다.
1) IP spoofing
TCP/IP 프로토콜의 결함에 대해서는 이미 1985년에 로버트 모리스의 논문 "A Weakness in the 4.2 BSD UNIX TCP/IP Software"에 언급되었고 1995년 유명한 해커 케빈미트닉이 이 이론을 실제화하여 해킹을 시도하다가 체포된 사건이 있었다. 이 사건 이후로 케빈미트닉이 사용한 해킹기술은 IP spoofing라는 용어로 불리게 되며 현재까지 TCP/IP 약점을 이용한 여러 가지의 공격기법 이 지속적으로 나오고 있다.
IP spoofing이란?
spoofing이라는 것은 '속이다'라는 의미이고 IP spoofing은 IP를 속여서 공격하는 기법을 의미한다. 현재 알려진 TCP/IP 프로토콜의 약점을 이용한 IP spoofing은 다음과 같다.
- 순서제어번호 추측(Sequence number guessing)
- 반(Half)접속시도 공격(SYN flooding)
- 접속가로채기(Connection hijacking)
- RST를 이용한 접속끊기(Connection killing by RST)
- FIN을 이용한 접속끊기(Connection killing by FIN)
- SYN/RST패킷 생성공격(SYN/RST generation)
- 네트워크 데몬 정지(killing the INETD)
- TCP 윈도우 위장(TCP window spoofing)
그러나 일반적으로 IP spoofing이란 케빈미트닉이 사용한 방법을 의미하며 순서제어번호추측 공격, 반(Half)접속시도 공격 등이 함께 사용되는 고난도의 수법으로 볼 수 있다.
공격과정
가) 위 그림에서 C는 A로 자신의 IP주소를 위장하여 SYN를 보내 접속요청을한다. 요청에 대한 응답으로 A가 C에 대한 ACK와 함께 자시의 SYN을 전송하지만 C가 이에 대해 ACK를 보내지 않으면 A는 자신이 보낸 ACK에 대한 C의 응답을 기다리게 된다. 이 과정을 연속적으로 반복하면 (예를 들어 SunOs의 경우, 약 8개 정도의 SYN패킷을 80초 정도 간격으로 보낸다.) A는 외부의 접속요청에 응답할 수 없는 오버플로우 상태가 된다.
나) 이후, C는 B로 정상적인 접속을 시도하여 순서제어번호의 변화를 패킷 모니터링을 이용하여 관측한다.
다) 순서제어번호의 변화를 관찰아여 추측한 순서제어번호를 이용하여 C는 자신의 IP주소를 A로 가장한후 B에 접속요청(SYN)을 보낸다. (순서제어번호의 변화는, 예를 들어 4.4BSD에서 OS부팅시 1로 세트되고 0.5초마다 64,000씩 증가한다. 또한 새로운 TCP 접속이 만들어질 때마다 64,000씩 증가한다.)
라) B는 수신된 SYN 패킷이 A에서 온 것으로 인식, A에게 ACK와 새로운 SYN를 보내지만 이미 A는 외부와 통신 불능상태이므로 응답을 할 수 없게 된다.. (만일 A가 C보다 먼저 응답하여 RST을 보내게되면 C의 공격은 실패한다.)
마) C는 자신의 IP 주소를 A주소로 위장하여 추측된 순서제어번호를 이용해 B가 A로 보낸 SYN/ ACK에 대한 ACK를 B에 보낸다.
바) 결국 C와 B 불법적 접속이 이루어지고, B와 A는 연결되어 있는 것으로 착각한다.
사) 이후 rsh을 이용하여 echo '+ +' >/.rhosts과 같은 데이터를 보내면 된다.
방지대책
외부에서 들어오는 패킷중에서 출발지 IP주소(Source IP Address)에 내부망 IP주소를 가지고 있는 패킷을 라우터 등에서 패킷 필터링을 사용하여 막아낼 수 있다. 그러나 내부 사용자에 의한 공격은 막을 수 없으므로 각 시스템에서 TCPwrapper, ssh 등을 설치해서 운영하고 , rsh, rlogin 등과 같이 패스워드의 인증 과정이 없는 서비스를 사용하지 않는 것이 바람직하다. 그러나 여러종류의 IP spoofing은 TCP/IP의 설계와 구현상의 문제점에 기인한 것으로 새로운 프로토콜을 사용하지 않는 한 완벽한 보호대책은 존재할 수 없다. 다만 지속적인 보안관리 및 점검만이 최소한의 피해를 막을 수 있다고 할 수 있겠다.
2) TCP SYN FLOODING ATTACK
최근 두종류의 지하 잡지에 "반만 열린" TCP 연결들을 생성하므로써 서비스거부공격을 하는 코드가 발표되었다. 인터넷에 연결되어 TCP 기반의 서비스(예를 들면, 웹서버, FTP서버, 또는 메일서버 등)를 제공하는 모든 시스템들이 이 공격에 노출되어 있으며, 공격의 결과는 시스템에 따라 다르다. 그러나 이 문제에 대한 완벽한 해결책은 없으며 단지 영향을 감소시키는 방법들만이 알려져 있다.
어떤 시스템(클라이언트)이 서비스를 제공하는 시스템(서버)에 TCP 연결을 시도할 때, 클라이언트와 서버는 다음과 같이 일련의 메시지들을 교환한다. 먼저 클라이언트 시스템은 서버에 SYN 메시지를 보내며, 서버는 SYN-ACK 메시지를 클라이언트에 전송하므로써 접수된 SYN 메시지에 대해 확인한다. 클라이언트는 다시 ACK 메시지를 전송하므로써 접속 설정을 완료한다. 이렇게 하므로써 클라이언트와 서버 사이의 접속이 열리게 되고, 클라이언트와 서버사이에 서비스에 고유한 자료들을 교환할 수 있게된다. 이러한 접속방법은 모든 TCP 연결(텔넷, 전자우편, 웹 등) 에 대해 적용된다.
공격의 가능성은 바로 서버가 클라이언트에 확인 메시지(ACK-SYN)을 보낸 후 클라이언트로 부터 다시 확인 메시지(ACK)를 받기 이전의 시점에서 발생한다. 이 상태가 바로 "반만 열린" 연결이라고 불린다. 서버는 모든 진행중인 연결에 대한 정보를 저장하기 위해 시스템 메모리에 자료구조를 구축하며 이 자료구조는 그 크기가 제한되어 있다. 따라서 계속하여 "반 만 열린" 연결을 생성하므로써 이 자료구조를 넘치게 할 수 있다.
반만 열린 연결은 IP 속이기를 이용하면 손쉽게 생성할 수 있다. 공격자 시스템에서 피공격 서버에 적법하게 보이지만 실제로는 ACK-SYN에 대해 응답할 수 없는 클라이언트를 참조하는 SYN 메시지를 발송한다. 따라서 피공격 서버는 최종 SYN 메시지를 받 을 수 없게된다. 마침내 피공격 서버측의 "반만 열린" 연결을 위한 자료 구조가 가득차게 되고 이 자료 구조가 비워 질 때까지 피공격 서버는 새로운 연결 요구에 대해 응답할 수 없게 된다. 일반적으로 반만 열린 연결에 대해서는 타임아웃 값이 설정되어 있어 일정 시간이 경과하면 자동적으로 취소되게 되므로 새로운 연결에 대해 응답할 수 있게 된다. 그러나 이와같은 복구에 소요되는 시간보다 빠르게 공격자 시스템이 반복적으로 속임용 IP 패킷을 전송할 수 있다.
대부분의 경우, 이러한 공격의 피해 시스템은 새로운 네트워크 연결 요청을 받아 들이는데 곤란을 겪게 되며 서비스제공 능력의 저하를 가져온다. 그러나 기존의 외부로 부터의 연결이나, 외부로의 새로운 접속 요청 전송에는 영향을 받지 않는다. 그러나 특별한 경우, 시스템의 메모리가 고갈되거나, 파괴되거나, 또는 작동불가능하게 될 수도 있다.
SYN 패킷의 근원지 주소가 가짜이므로 공격의 근원을 알아내는 것은 어려우며 패킷이 피공격 서버에 도착한 뒤에 근원을 알아내는 것은 불가능하다. 네트워크는 패킷을 목적지 주소만을 이용하여 전달하므로 근원을 검증하는 유일한 방법은 입력 소스 필터링을 이용하는 것 뿐이다.
현재의 IP 프로토콜 기술로는 IP 속임 패킷을 제거하는 것이 불가능하므로 현재로서는 이 문제에 대한 완전한 해결책이 없는 상태이다. 그러나 관리하고 있는 네트워크로 유입되거나 이로부터 유출되는 IP 속임 패킷을 감소시킬 수 있는 방법이 있다. 즉, 라우터를 적절히 구성하므로써 공격당할 가능성을 줄이거나, 해당 사이트내의 시스템이 공격의 근원이 될 수 있는 가능성을 감 소시킬 수는 있다.
현재로서의 최상의 해결책은 외부 접속용 인터페이스로의 유입을 제한하는 필터링 라우터(입력 필터라고 부름)를 설치하여 근원이 내부 네크워크인 모든 패킷의 유입을 금지시키는 것이다. 이에 더하여 근원이 내부 네트워크가 아닌 모든 패킷의 유출을 금지시켜 관리하의 사이트로 부터 IP 속임 공격이 발생되는 것을 방지할 수 있다. 그러나 이러한 방법도 외부 공격자가 다른 임의의 외부 주소를 이용하거나, 내부의 공격자가 내부의 주소를 이용하여 공격하는 것에 대해서는 방어하지 못한다.
3) FIREWALL FAQ
Original Contributor : Marcus J. Ranum, ranum@iwi.com
1st Korean Contributor: Chaeho Lim, chlim@certcc.or.kr
-----------------------------------------------------
목차
- About FAQ
- 네트워크 방화벽시스템이란?
- 왜 방화벽인가?
- 방화벽시스템이 막을 수 있는 것은?
- 방화벽시스템이 막지 못하는 것은?
- 바이러스에 대해서는?
- 방화벽시스템에 대한 좋은 참고자료는?
- 네트워크에서 받을 수 있는 좋은 참고자료는?
- 방화벽시스템 제품, Consultants 는?
- 방화벽시스템 설치를 위한 네트워크 설계는?
- 방화벽시스템 종류는?
- 프락시서버는 무엇이며, 어떻게 동작하나?
- 값싼 패킷스크린 도구는?
- CISCO 에서의 적당한 필터링 규칙은 무엇인가?
- WWW/HTTP 와 어떻게 동작하게 만드나?
- DNS와 어떻게 동작하게 만드나?
- FTP와는 어떻게 동작하게 만드나?
- TELNET 과는 어떻게 동작하게 만드나?
- Finger/Whois 와는 어떻게 동작하게 만드나?
- Gopher/Archie, 기타 서비스와 어떻게 동작하게 만드나?
- X-Window 와 동작하게 만들 경우의 관련 이슈는?
- Source Route 는 무엇이며, 왜 위험한가?
- ICMP Rediect 란 무엇이며 Redirect Bomb란?
- 서비스거부(Denial of Service)란 무엇인가?
- 용어 설명
- 공헌자들
-----------------------------------------------------
a) About the FAQ
이 FAQ는 어떤 특정 제품이나 업체, 컨설턴트응 위한 것이 아니며, 이 FAQ에 대한 어떤 코멘트라도 환영한다. 이것에 대한 코멘트는 Fwalls-FAQ@iwi.com 으 보내면 이 FAQ는 http://www.iwi.com 에서도 볼 수 있다.
b) 네트워크 방화벽시스템이란?
방화벽이란 2개의 네트워크 사이에서 접근제어 정책을 구현할 수 있도록 하는 시스템이나 시스템들의 집합이다. 궁극적으로 이 시스템이 수행하는 기능의 입장에서는 2개의 메카니즘으로 이루어지는데, 즉 네트워크에서의 트래픽을 막는 것과허용하는 것이다. 방화벽에 따라 2가지중 어떤 하나가 더욱 강조될 수 있으나 아마 가장 중요한 것은 방화벽이 접근제어 정책을 구현다는 사실이다. 만약 어떤 접근제어에 의해 막거나 허용할 것인지 알 수 없을 때나 단순히 어떤 것을 허용한다는 생각을 가지거나 제품이 제공하는 혹은 그들이 생각하는 식으로 구현하려한다면 그들은 당신이 속한 기관 전체의 정책을 만드는 것이다.
c) 왜 방화벽인가?
인터넷에서도 일반 사회에서 벌어지는 다른 사람의 벽에 낙서를 하거나 우체통을 훼손하거나차량을 훼손하는 등등의 일들과 유사한 행위들이 벌어지고 있는데, 여기에는 중요한 데이타나 자원들이 있을 수 있어 인터넷에 가입된 기관은 이를 막으려 하고 있다. 방화벽의 주된 목적은 이러한 불법행위에 대해 자신의 네트워크를 보호하고 내부에서는 일상적인 업무를 평시와 같이 할 수 있도록 하자는 것이다. 대부분 전통적인 기관이나 네트워크/데이타센터들은 자체적인 보안정책이나 실행강령등을 가지고 있는데, 정책이 데이타의 보호를 주목적으로 준비된 곳이라면 방화벽은 매우 중요하다. 인터네트에 접속하고자 할때 만약 규모가 큰 기관이라면,비용이나 노력에 대한 정당성을 찾기 어려울 뿐 아니라 관리적인 것도 안전한지정당화하기 어렵다. 방화벽은 보안 뿐 아니라 망관리에 대한 보증이 되기도 한다.
마지막으로 방화벽은 인터넷에 대한 기관의 대사관 역할을 하게 된다. 많은 기관들이 방화벽에 자신의 제품이나 서비스에 대한 공개 정보 서버로서 활용하여 파일을 제공한다. 이러한 시스템의 많은 경우에서 인터넷서비스의 중요한 역할(사례: UUnet.uu.net, whitehouse.gov, gatekeeper.dec.com 등)과 자신의 기관이 인터넷에서의 어떤 역할을 하는지 잘 반영할 수 있게 한다.
어떤 방화벽은 단지 전자우편 트래픽만을 허용하기도 하는데, Email 서비스 공격이 아닌 모든 네트워크공격에 대해 보호한다. 어떤 방화벽은 보다 느슨한 제한을 두어 단지 문제가 알려져있는 서비스만 막는다.
일반적으로 방화벽은 외부에서의 불법적인 대화형 접근을 막을 수 있도록 구성할수 있으며 불법행위자들이 내부의 네트워크내 기계로 접근하는 것을 봉쇄한다.그러면서 내부 사용자는 외부에 자유롭게 접근할 수 있도록 허용한다. 하지만 방화벽은 어디에서 출발한 트래픽일지라도 제어할 수 있다.
방화벽은 보안과 기록(Audit)가 필요한 곳이라면 단 하나의 점검할 수 있는 기능이 제공되어 매우 중요하다. 어떤 컴퓨터가 다이얼모뎀에 의한 공격을 받을 수있는 것과는 달리 방화벽은 효과적인 전화태핑과 역추적 도구 기능이 제공된다. 방화벽이 제공하는 로그를 이용하여 어떠한 트래픽일지라도 관리자에게 보고할 수있도록 만들고 얼마나 많은 침입시도가 있었는지를 알 수 있다.
- 방화벽시스템이 막을 수 있는 것은?
방화벽 서버를 통과하는 TIP/IP패킷
e) 방화벽시스템이 막지 못하는 것은?
방화벽은 방화벽을 통과하지 않는 트래픽에 대해서는 막을 수 없다. 인터넷에 연결된 많은 기관들이 인터넷에 연결된 통로를 따라 누출될 수 있는 데이타의 보호를 위해서는 관심이 많다. 하지만 오히려 마그네틱 티으프에 의한 데이타의 유출에 대해서는 관심이 그다지 많지 않으며 또한 모뎀을 통해 인터넷 접근에 대한 보호가 필요하며 꾸준한 정책이 요구된다는 것을 잘 모르고 있다.이것은 나무집에 살면서 두꺼운 철제 대문을 만드는 것과 마찬가지로, 많은 기관들이 값비싼 방화벽제품을 구매하면서 자신의 네트워크로 들어가는 수많은 뒷문에 대해서는 신경도 쓰지 않은 것과 같다. 방화벽이 잘 동작하기를 바란다면 기관 전체의 보안구조의 일부로서 동작하게금 일관성을 가지는 것이 좋다. 방화벽에 대한 정책은 현실적이어야 하며, 전체 네트워크의 보안 수준을 잘 반영하도록 해야한다. 예를 들어 최고등급이나 분류된 데이타를 가진 곳에서는 방화벽이 전혀 필요없다. 즉 이 기관은 인터넷에 연결해서는 안되며, 이러한 정보를 처리하는 시스템은 전체 네트워크로 부터 차단해야 하는 것이다.또 하나 문제는 방화벽이 기관의 배반자나 스파이들에 대해서는 보호할 수 없다는것이다. 산업스파이가 방화벽을 경유하여 정보를 빼낼 수 있지만 대부분 전화나 팩스, 프로피디스크 등을 선호하게 된다. 또한 방화벽은 어떤 바보같은 행위에 대해서도 막을 수 없다. 사용자가 중요한 정보를 무심코 흘릴수도 있으며, 침입자의 사회과학적수법에 속게 되면 방화벽을 개방 시킬 수도 있다.
f) 바이러스에 대해서는?
방화벽은 바이러스에 대해 효과적으로 막지는 못한다. 네트워크를 통해 전달될 수 있는 실행파일을 작성할 수 있는 방법들이 많이 있으며, 그러한 방법들을 제공하는 바이러스나 구조들이 많이 존재한다. 방화벽은 사용자들을 대신하여 모든 것을 막을 수 없으며, 네트워크의 전자우편이나 복사를 통해 전달된 바이러스에 대해 효과적으로 막을 수 없으며, 이러한 사례들은 여러가지 버젼의 Sendmail 에서, 혹은 Ghoscript, Postscript Viewer 등에서 발견되었다. 바이러스에 대해 대책을 세우려는 기관들은 기관 전체의 차원에서 바이러스 제어 수단을 세워야 하며, 방화벽에서 바이러스를 검출하겠다는 발상보다 중요한 시스템이 부팅될 때 마다 바이러스 스캐닝할 수 있도록 하는 편이 좋다. 바이러스 스캐닝 도구를 이용하여
네트워크를 보호하는 것은 플로피디스크, 모뎀, 인터넷 등에서 들어오는 바이러스를 막는 것이다. 방화벽에서 바이러스를 막는 방식은 단지 인터넷에서의 바이러스침투를 막는 것 밖에 없다. 대부분은 플로피디스크에 의해 전달된다는 사실을 알아야 한다.
g) 방화벽시스템에 대한 좋은 참고자료는?
방화벽에 대한 책자를 소개 한다.
서 명 : Firewalls and Internet Security: Repelling the Wily Hacker
저 자 : Bill Cheswick and Steve Bellovin
출판사: Addison Wesley Edition
년 도 : 1994
ISBN : 0-201-63357-4
서 명 : Building Internet Firewalls
저 자 : D. Brent Chapman and Elizabeth Zwicky
출판사: O'Reilly Edition
년 도 : 1995
ISBN : 1-56592-124-0
서 명 : Practical Unix Security
저 자 : Simson Garfinkel and Gene Spafford
출판사: O'Reilly Edition
년 도 : 1991
ISBN : 0-937175-72-2 (discusses primarily host security)
서 명 : Internetworking with TCP/IP Vols I, II and III
저 자 : Douglas Comer and David Stevens
출판사: Prentice-Hall
년 도 : 1991
ISBN : 0-13-468505-9 (I), 0-13-472242-6 (II), 0-13-474222-2 (III)
서 명 : Unix System Security - A Guide for Users and System Administrators
저 자 : David Curry
출판사: Addision Wesley
년 도 : 1992
ISBN : 0-201-56327-4
h) 네트워크에서 받을 수 있는 좋은 참고자료는?
Ftp.greatcircle.com - Firewalls mailing list archives. Directory: pub/firewalls
Ftp.tis.com - Internet firewall toolkit and papers. Directory: pub/firewalls
Research.att.com - Papers on firewalls and breakins. Directory: dist/internet_security
Net.Tamu.edu - Texas AMU security tools. Directory: pub/security/TAMU
iwi.com - Internet attacks presentation, firewall standards
인터넷방화벽시스템 메일링리스트는 "방화벽 관라자 및 개발자들의 포럼"이며, 이의 가입은 전자우편의 내용에 "subscribe firewalls" 를 넣어 Majordomo@GreatCircle.Com으로 보내면 된다. 메일링리스트의 아카이브는, ftp.greatcircle.com 으로 악명 FTP를 이용하여 pub/firewalls/archive 에서 찾아볼 수 있다.
i) 방화벽시스템 제품 업체, Consultants 는?
이러한 내용이 FAQ에 들어가야 할지는 민감한 내용이 되겠지만 업체와는 무관하게 다음 URL에서 관리되고 있으며, 이것은 어떤 보장을 하거나 권고는 아니다.
http://www.access.digex.net/~bdboyle/firewall.vendor.html
j) 방화벽시스템 설치를 위한 네트워크 설계는?
방화벽을 설계, 사양을 작성하거나, 구현 혹은 설치를 위한 사전 검토를 위한 사람들을 위해 이미 알려진 설계 이슈들이 많이 나와 있다. 처음이자 가장 중요한 이슈로서 당신의 조직이 어떻게 시스템을 운영할 것인지에 대한 정책을 반영하는 것으로서, 매우 중요한 네트워크에서의 작업을 제외하고는 모든 접속을 거부하는 식의 시스템을 운영할 것인가 아니면 덜 위협적인 방법으로 접속해 오는 모든 트래픽에 대해 조사하고 점검하는 방식으로 시스템을 운영할 것인가라는 선택을 할 수 있다. 이러한 선택은 결정권에 대한 당신의 태도에 달려있으며, 특히 엔지니어링 측면의 결정 보다 정책적인 결정에 따르게 된다.
두번째 이슈로는 어느 정도 수준의 모니터링, 백업 및 제어를 원하는가 라는 문제이다. 첫번째 이슈로서 기관이 받아들일 수 있는 위험 수준이 세워졌다면, 이제 어떤 것을 모니터하고, 허용하고, 거부할 것인가라는 체크리스트를 작성해야 한다. 즉, 기관의 전체적인 목적을 결정하고 위험평가에 근거한 필요성 분석을 하며, 구현하고자 계획하여 사양을 마련했던 목록과 구별될 수 있는 문제점들을 가려낸다.
세번째 이슈는 경제적인 문제이다. 우리가 여기에서 정확하게 지적할 수 있지는 못하지만 이것을 구매하는데 드는 비용과 구현에 드는 비용을 정확하게 정량적으로 산출하고자 하는 것이 중요하다. 예를 들어 완전한 방화벽제품의 구매에 드는 비용은 무료에서 100,000 달러에 이를 수 있으며, 무료에는 Cisco라우터의 비용과 구성 및 스태프의 인건비 등은 포함되지 않은 것이다. 제품 구매에 드는 비용에는 월 30,000달러 의 인건비 등이 포함된다. 그리고 시스템 관리에 드는 오버헤드 등이 포함된다. 방화벽 시스템의 우선 설치 및 구현에 드는 비용 뿐 아니라 지속적으로 드는 비용과 지원비 등이 계상되어야 한다.
기술적인 측면에서 몇가지 결정해야 할 것이 있는데, 기관 내부의 네트워크와 네트워크 서비스 제공자 사이에서의 고정적 트래픽 라우팅 서비스 등에 대해서도 결정하야 한다. 트래픽라우팅은 라우터에서의 IP 수준의 스크린 규칙이나 혹은 프락시게이트웨이 나 서비스에서의 응용 수준 등에서 구현되어야 한다.
telnet, ftp, news 등의 프락시를 설치되는 외부에 노출된 기계가 외부네트워크에 둘 것인가 혹은 하나 이상의 내부 기계와 통신을 허용하는 필터링으로서의 스크린 라우터를 만들 것인가를 결정해야 한다. 각각의 접근 방식은 장단점이 있는데, 프락시기계가 고급 수준의 기록성과 잠재적인 보안 기능을 많이 구현해야 하는 만큼 또한 비용이 많이 요구되기 때문이다. 프락시는 요구되는 서비스 마다 따로 따로 설계되어야 하며, 편리성과 보안에 드는 비용은 상대적이다.
k) 방화벽시스템 종류는?
개념적으로 2개의 타입이 있다.
* 네트워크 레벨(Network Level),
* 응용 레벨(Application Level)
이러한 2가지 타입에 대해 어떤 것이 좋고 어떤 것이 나쁘다는 식의 판단을 내리기는 어려운 점이 있지만 기관의 요구사항에 어떤 것이 부합되는지를 잘 판단하는것이 좋다.
네트워크 레벨의 시스템은 IP 패킷의 Source/Destination 어드레스와 포트에 의해결정하게 된다. 단순한 라우터는 낡은 방식의 네트워크 레벨 방화벽을 제공하는데,이것은 어떤 패킷이 동작하는지 어떠한 네트워크에서 왔는지를 판단해야 하는 복잡한 규칙에 대해 판단하기 어렵고, 현재의 네트워크 레벨 방화벽은 매우 복잡해져서 허용된 접속들의 상태와 어떤 종류의 데이타 내용 등을 관리할 수 있다. 한가지 중요한 구별점은 네트워크 레벨 방화벽이 라우트를 직접 제어할 수 있으며, 할당된 IP 블럭을 정당하게 사용할 수 있도록 해준다는 점이다. 네트워크 레벨 방화벽은 매우 빠르며, 사용자에게 투명한 서비스를 보장한다.
* 네트워크 레벨 방화벽의 사례 : "스크린호스트방화벽" 이라고 할 수 있으며, 하나의 호스트에서의 접근제어가 네트워크 레벨에서 동작하는 라우터에서 이루어지며, 이때의 하나의 호스트란 "Bastion Host"이다.
* 네트워크 레벨 방화벽의 사례 : "스크린서브네트방화벽" 이라는 것으로 구현될 수 있으며 이것은 네트워크 레벨에서 동작하는 라우터가 하나의 전체 네트워크에 대 한 접근제어를 할 수 있음을 말한다. 스크린호스트의 네트워크란 점만 빼면 스크린 호스트와 유사한다.
응용 레벨 방화벽은 2개으 네트워크 간에 항상 직접적인 트래픽을 막고, 트래픽에 대해 로그, Audit 기능 등이 지원되는 프락시를 실행하는 기계를 말한다. 프락시 응용은 방화벽의 소프트웨어 부분이므로 많은 로그와 접근 제어 기능을 주는 것이 좋은 것이다. 응용레벨 방화벽은 어드레스 번역기로서 사용될 수 있다. 어떤 쪽에서들어와 다른 쪽으로 나가기 때문에 처음 시도한 접속에 대해 효과적인 마스킹을 할 수 있는 것이다. 이렇게 중도에 응용을 가지는 것은 어떤 경우에는 성능에 문제를 가질 수 있으며, 투명성이 보장되지 않는다. TIS 툴킷 등에 구현된 것과 같은 초기 응용레벨 방화벽은 일반사용자에게 투명하지도 않으며, 어떤 연숩이 필요하였다. 최근의 응용레벨 방화벽은 투명성이 보장되며, 보다 상세한 Audit 보고와 네트워크레벨 방화벽보다 보다 온전한 보안 모델을 제공하고 있다.
* 응용레벨 방화벽 사례 : "이중네트워크게이트웨이(Dual-Homed Gateway)"이 있을 수 있으며, 프락시를 실행하는 고도의 보안이 제공되는 시스템이다. 이것은 2개 의 네트워크 인터페이스를 가지고 하나의 네트워크 인터페이스에 대해서는 모든 트래픽이 그냥 통과되는 것을 막는다.
미래의 방화벽시스템은 네트워크레벨 과 응용레벨 방화벽의 어떤 정도에 해당된다.이것의 의미는 네트워크레벨에서는 보다 상위의 기능을 가지려 하고 응용레벨에서는 보다 하위 기능을 가지려 하기 때문이다. 최종 결과는 아마 매우 빠른 패킷스크린 기능과 모든 트래픽에 대한 로그와 Audit 등이 예측되며, 특히 네트워크를 통해 전달되는 트래픽의 보호를 위해 암호 기법이 사용되리라고 보여진다. 종단간 암호 방식은 데이타나 패그워드 등이 도청되는 것을 막는 방식을 원하는 사설백본(Private Backbone)에서 여러 인터넷 접속점을 가진 기관에서 유용할 것이다.
l) 프락시서버는 무엇이며, 어떻게 동작하나?
흔히 응용게이트웨이 혹은 응용 전달자라고 하는 프락시 서버는 보호된 네트워크와 인터넷 사이의 트래픽을 중재하는 응용이라고 볼 수 있으며, 네트워크간에 직접 트래픽이 통과되는 것을 막는 라우터 기반의 트래픽제어을 대신하여 이용된다. 많은 프락시들은 그밖에도 추가적인 로그 기능과 사용자 인증 기법들이 지원되며, 사용되는 응용프로토콜을 이해해야 하므로 각각의 프로토콜에 특정적인 보안 기능을 구현할 수 있다. 예를 들어 FTP 프락시는 들어오는 FTP접속은 허용하고 나가는 FTP접속을 막을 수 있다.
프락시 서버는 응용에 특정적이다. 만약 프락시를 경유한 새로운 프로토콜을 지원하려면 그를 위한 프락시를 개발해야 하며, 일반적으로 사용되는 프락시 서버들은 Telnet, rlogin, FTP, X-Window, http/web, NNTP/Usenet 서비스 등을 가진 TIS 툴키트이다. SOCKS는 일반적인 공통의 프락시이며, 클라이언트 응용쪽에서 함께 컴파일 되어 방화벽과 함께 사용할 수 있다. 이것의 장점은 사용하기 편리하다는 점이 있지만 사용자 인증의 부가 기능이나, 프로토콜에 특정적인 로그 기능이 제공되지 않는다는 것이다. SOCKS에 대해서는
ftp://ftp.nec.com/pub/security/socks.cstc
을 참고하기 바란다.
m) 값싼 패킷스크린 도구는?
TAMU(The Texas AMU) : 스크린 라우터 기능 구현 소프트웨어
ftp://net.tamu.edu, pub/security/TAMU
Karlbridge : PC-based screening router kit
ftp://ftp.net.ohio-state.edu/pub/kbridge
DEC "screend" kernel screening software for BSD/386, NetBSD, and BSDI
n) CISCO 에서의 적당한 필터링 규칙은 무엇인가?
다음 사례는 CISCO 라우터를 필터링 규칙에 의해 구성하는 것을 보이고 있으며, 이것은 특정 정책에 의한 것이며, 각 기관은 자신의 정책에 따라 구현해야 한다.
* 이 사례에서는 128.88 B Class 어드레스를 가지고 있으며, 8 비트를 서브네트로 활용하고 있다. 인터넷 접속 부분은 128.88.254 이며, 모든 다른 서브네트는 내부의 신뢰하는 네트워크이다. 다음 사항을 기억하면 구성을 잘 이해할 수 있다.
- CISCO 에서의 규칙은 외부로 나가는 패킷에 대해서만 적용한다.
- 규칙들은 순서대로 시험되며, 처믐 매치에 정지한다.
- access list 규칙의 마지막 부분에 묵시적인 접근거부로서 모든 것을 거부한다.
이 사례는 구성의 필터링 부분만 보인 것이며, 라인번호는 작의적으로 붙인것이다.
여기에 적용된 정책은,
- 선언된 접근 허가가 아니면 모든 거부한다.
- 외부의 게이트웨이와 내부망과의 트래픽은 허용한다.
- 내부망에서 출발한 서비스는 허용한다.
- 내부망으로 가는 FTP 데이타 접속 포트들은 허용한다.
1. no ip source-route
2.!
3. interface Ethernet 0
4. ip address 128.88.254.3 255.255.255.0
5. ip access-group 10
6. !
7. interface Ethernet 1
8. ip address 128.88.1.1 255.255.255.0
9. ip access-group 11
10. !
11. access-list 10 permit ip 128.88.254.2 0.0.0.0 128.88.0.0 0.0.255.255
12. access-list 10 deny tcp 0.0.0.0 255.255.255.255 128.88.0.0 0.0.255.255 lt 1025
13. access-list 10 deny tcp 0.0.0.0 255.255.255.255 128.88.0.0 0.0.255.255 gt 4999
14. access-list 10 permit tcp 0.0.0.0 255.255.255.255 128.88.0.0 0.0.255.255
15. !
16. access-list 11 permit ip 128.88.0.0 0.0.255.255 0.0.0.0 255.255.255.255
17. access-list 11 deny tcp 128.88.0.0 0.0.255.255 0.0.0.0 255.255.255.255 eq 25
18. access-list 11 permit tcp 128.88.0.0 0.0.255.255 0.0.0.0 255.255.255.255
* NO IP Source-route : 이것은 필터링 규칙은 아니지만 여기에 넣는 것이 좋는데, 라우터가 모든 source-route 패킷을 거부하도록 한다.
* IP Access-Grpup 10 : 이더넷 0 는 안전하지 않은 네트워크이며, 확장된 접근 리스트 10 은 이 인터네페이스에서 나가는 쪽으로 적용된다. 안전하지 않은 네트워크에서의 출력은 이 닌터페이스에서의 입력으로 간주된다.
* IP Access-Group 11 : 이더넷 1은 안전한 네트워크이며, 확장된 접근리스트 11은 이 인터페이스에서의 출력으로 적용된다.
* Permit 128.88.254.2 : 게이트웨이 기계로 부터 안전한 네트워크로 가는 트래픽을허용한다.
* 접근리스트 10 Permit tcp : 안전하지 않은 네트워크로 부터 오는 모든 1024 에서5000 번까지의 접속을 허용한다. 이것은 안전한 망으로 돌아오는 FTP 데이타 접속을 허용한다는 것이며, 5000 은 OpenView 시작인 것과 같이 상위 제한번호 이다.
우리는 이것을 주어진 정책에 의해 허용한 것이며, Cisco 에서는 소스포트에 대해 필터를 할 수 있는 방법이 없다. 이 규칙은 처음 매치때 까지 시험되므로 이것을 사용할 수 밖에 없다.
* 접근리스트 11 Permit ip : 모든 안전한 네트워크에서 게이트웨이로 가는 패킷을 허용한다.
* 접근리스트 11 Deny tcp : 안전하지 못한 네트워크로 가는 모든 SMTP(25) 메일을 거부한다.
* 접근리스트 11 Permit tcp : 안전하지 못한 네트워크로 가는 모든 TCP 트래픽을 허용한다.
Cisco.Com 에서는 방화벽을 구축하는 사례들을 가지고 있으며, 새로운 버젼의 Cisco펌웨어들은 관리자가 inbound/outbound 패킷들에 대한 필터링을 할 수 있도록해주고있다. 사례들의 모음은 다음에 있다.
ftp://ftp.cisco.com/pub/acl-examples.tar.Z
o) WWW/HTTP 와 어떻게 동작하게 만드나?
다음 3가지 방식 중에 하나를 선택하면 된다.
* 스크린라우터를 사용한다면, "established" 접속을 라우터에서 허용한다.
* SOCKS 를 지원하는 Web 클라이언트를 사용하고 방화벽에서 SOCKS를 구현한다.
* 방화벽에서 웹서버 프락시를 구현한다. TIS 툴키트는 http-gw라는 프락시를 지원 하고 있으며, Web, Gopher/gopher+, FTP 프락시까지 지원된다. CERN httpd 도 프락시를 지원하며, 많은 기관들은 자주 접근되는 페이지에 대해 캐쉬 성능과 함께 도작하도록 사용한다. 많은 웹클라이언트들(Netscape, Mosaic, Spry, Chameleon 등)은 프락시 서버를 지원하며, 함께 구현되어 있다.
p) DNS와 어떻게 동작하게 만드나?
많은 기관들이 DNS 이름을 바깥에 드러나지 않게 하고 싶어 한다. 전문가들은 이것이 가치있다고 생각하지는 않지만 기관의 정책이 그렇다면 이러한 접근방법들이 알려져 있다. 또 하나의 이유는 기관 내부에서 표준 어드레스를 사용하지 않는 경우가 있을 수 있는데, 이경우에는 어쩔 수 없이 이 방법을 사용하지 않을 수 없다.이것 때문에 느려진다든가 방화벽이 침입자에 의해 침해를 받지는 않는다. 기관의네트워크에 관한 정보들은 네트워크 계층 자체에서는 너무나 쉽게 알려질 수 있는데, 이의 시험을 위해서는 LAN 에 ping 서브네트 방송 어드레스를 이용하여, "arp -a"을 해보면 알 수 있다. DNS에서의 이름을 감추는 것은 메일 헤더나 뉴스헤더 등에 호스트 이름을 드러내지 않도록 해주기도 한다.
이 접근방식은 각 기관이 자신의 호스트 이름을 외부에 드러내지 않도록 하는데 유용하며, 이 접근 방식의 성공여부는 DNS 클라이언트들이 같은 기계에 있는 서버와 대화하지 않도록 하는데 있다. 즉 이것은 만약 어떤 한 기계에 서버가 있다면 기계의 DNS 클라이언트 행위가 다른 기계에 있는 서버에게 재전달되는 잘못이 없기때문이다.
먼저, Bastion 호스트에 DNS 서버를 구축하여 외부에서 대화할 수 있도록 한는데,기관의 도메인에 대해 공식적인 궈한을 가질 수 있도록 한다. 사실 모든 이 서버가 알고 있는 것은 외부에서 알도록 공개하고 싶은 것들 뿐이다. 이것은 공개적인 서버로서 게이트웨이의 이름과 어드레스, 와일드 MX 레코드 등등이다.
그리고 나서 내부기계에 DNS 서버를 구축한다. 이 서버도 역시 공개서버와는 다르지만 공식적인 권한을 가질 수 있도록 하는데 진짜로 데이타를 가진 일반 서버인것이다. 그리고 이 서버를 공개서버를 resolve 할 수 없도록 /etc/named.boot 에 "forwarders" 라인을 이용하여 질의를 포워드하게금 세업한다.
마지막으로 /etc/resolv.conf 파일에서 공개서버를 가진 기계를 포함한 모든 클라이언트들이 내부서버를 사용하도록 조정하는데 이것이 주 포인트이다.
내부 클라이언트들은 내부호스트에 대해서는 내부서버에게 물어보고 응답을 받으며,외부호스트에 대해서는 공개 서버에게 물어보도록 되어있는 내부서버에게 요청한다.공개서버에 있는 클라이언트도 마찬가지로 동작하며, 하지만 외부의 클라이언트들은 내부의 정보에 대해 공개서버로 부터 제한된 정보만을 받게 된다.
이러한 접근방법은 이 2개의 서버간에 패킷 필터링 방화벽이 있다는 것을 가정하고있으며 이것은 상호 DNS 대화를 허용하지만 다른 호스트 사이에는 DNS를 제한하는것이다.
이러한 접근 방식의 또 다른 유용한 트릭은 기관의 IN-ADDR.ARPA 도메인에 와일드카드 PTR 레코드를 채택하는 방버이다. 이것은 어드레스-네임 어떠한 내부의 호스트에 대한 lookup도 에러가 아닌 "unknown.Your.Domain" 식으로 반환하게금 하며, 대화하려는 호스트에 대한 이름을 가지도록 해주는 ftp.uu.net 와 같은 익명FTP에 적당한 것이다. 이것은 호스트 이름이 그것의 어드레스와 마찬가지로 매치되는지 DNS ceross-check를 하는 싸이트와 대화할 경우에는 실패하게 된다.
q) FTP와는 어떻게 동작하게 만드나?
일반적으로 FTP를 방화벽과 동작하게 만드는 것은 TIS 툴킷의 ftp-gw 식의 프락시나혹은 내부네트워크로 들어오는 접속에 제한된 영역을 주어 허용하든지, 아니면, "establicshed" 스크린 규칙과 같은 방법을 이용하여 내부로 들어오는 접속을 제한할 수 있다. FTP 클라이언트들이 그 정해진 영역으로 데이타 포트를 바인드할 수 있도록 고쳐지면 내부의 호스트에 있는 클라이언트들이 수정될 수 있게금 한다.
어떤 경우에는 만약 FTP 다운로드가 기관이 원하는 모든 것이라면 FTP를 죽이고,대신에 Web 을 다운로드 기능에 사용될 수 있다. 만약 Web FTP를 사용한다면 사용자는 FTP 파일을 가져갈 수 없게 되고 문제가 생길 수 있다.
또다른 접근 방법으로서 원격지 서버가 클라이어트로 하여금 접속을 시도하도록 지정하는 FTP 의 "PASV" 옵션을 사용할 수 있다. 이것은 FTP 서버가 이러한 동작을지원하도록 운영되어야 한다.(RFC 1579)
어떤 싸이트들은 SOCKS 라이브러리를 지원하는 FTP 프로그램 버젼을 선호한다.
r) TELNET 과는 어떻게 동작하게 만드나?
TELNET 는 TIS 툴킷의 tn-gw 처럼 응용프락시를 사용하는 것이 일반적이다. 혹은 "established" 스크린규칙을 이용하여 외부로 나가는 접속을 허용하도록 라우터를구성할 수 있다. 응용프락시는 Bastion 호스트에서 단독 프락시로 실행되도록 할 수 있으며, 혹은 SOCKS서버와 수정된 클라이언트를 사용할 수 있다.
s) Finger/Whois 와는 어떻게 동작하게 만드나?
많은 방화벽시스템은 단지 신뢰하는 시스템에서만 finger 포트를 이용할 수 있도록열어주는데, "finger user@host.domain@firewall" 형태를 지원하도록 한다. 이 접근방식은 표준 유닉스의 finger 버젼에서 동작하며, tcpwrappper나 TIS 툴킷의 netscl을 이용하면 서비스 접근을 제어할 수 있다. 어떤 finger 서버 버젼에서는 이러한 접근 방법을 지원하지 못할 수도 있다.
많은 기관들이 외부에서의 finger 접석을 허용하지 않는데, 이유는 finger 가 웜 프로그램등에서 취약점이 되었었다는 이유와 내부의 정보를 외부로 유출하고 싶지않은 이유들에 기인한다. 하지만 기관의 사용자들이 자신의 .plan 등에 주요한 정보나 민감한 정보를 넣어두고 있다면 방화벽이 풀 수 있는 것보다 더욱 심각한 보안 문제들을 야기할 수 있는 것이다.
t) Gopher/Archie, 기타 서비스와 어떻게 동작하게 만드나?
많는 방화벽관리자들은 gopher나 archie를 직접 동작하게 하는 것이 아니라 웹프락시를 통해 사용하도록 하고 있다. TIS 튤킷에서의 http-gw 프락시등에서는 gopher/gopher+ 질의를 html로 바꾸어주고 있으며, archie나 다른 서비스들을 위해서는 ArchiePlex와 같은 인터넷 기반의 웹-Archie 서버 등을 지원하도록 한다.웹이 인터넷의 모든 것을 지원하고자 하는 경향이 있다.
많은 새로운 서비스들이 만덜어지고 있지만 어떤 것들은 보안 문제를 신경쓰지 않고설계되기도 하고 어떤 것은 라우터에서 특정 포트를 경유하도록 설계해 줄 수 있지만 많은 새로운 응용들이 이렇게 지원하지 않으며 방화벽을 염두에 두고 설계하지 못하고 있다. 특히 UDP 접근을 직접 원하는 경우에는 문제가 있다. 만약 이러한 문제들을 직접 느낄 수 없다면 우선 이것들에 대해 허용하여 보라. 이것들이 보안을 전혀 내재하고 있지 않다는 것을 알게 될 것이며, 알수 없고 막을 수도 없는 보안 취약점들을 그대로 안고 있다는 것과 같다.
u) X-Window 와 동작하게 만들 경우의 관련 이슈는?
X 윈도우는 매우 유용한 시스템이지만 매우 보안에 위험한 요소들을 가지고 있는데,원격지시스템은 워크스테이션의 X 디스플레이를 조작하여 사용자가 입력하는 키를모니터하거나 윈도우 내용 전체를 복사할 수 있다.
가령 MIT 의 Magic Cookie 등을 이용하여 이러한 시도를 막을 수 있지만, 공격자의사용자 X 디스플레이를 방해할 수 있는 요소는 여전히 남아있다. 대부분의 방화벽은모든 X 트래픽을 막아버린다. 어떤 경우에는 DEC의 CRL X 프락시(ftp://crl.dec.com)와 같은 응용 프락시를 이용할 수 있다. TIS 툴킷은 x-gw라는 프락시를 이용하고 있는데, 사용자는 telnet 프락시를 이용하여 방화벽의 가상 X 서버를 생성하게 된다.가상 X 서버에 X 접속 요청이 들어오면 접속 요청이 허용된 것이라면 이것에 대해 Pop-Up 으로 나타나게 된다.
v) Source Route 는 무엇이며, 왜 위험한가?
보통 패킷이 목적지까지 가기위한 경로는 그 경로상에 있는 라우터에 의해 결정되고패킷 자체는 목적지 주소만 가지고 있을 뿐 경로에 대한 어떤 정보도 가지지 않는다.
하지만 옵션으로서 패킷을 보내는 쪽에서 목적지까지 가는 경로를 정의할 수 있다. 그래서 이름 그대로 'Source Routing"이다. 방화벽에서는 공격자가 내부망으로 곧장들어가도록 요구할 수 있기때문에 문제가 된다. 일반적으로 그러한 트래픽이 방화벽자원에 라우팅되지 않도록하며, Source Routing 에 대해서는 목적지 시스템과 공격자의 호스트사이에 모든 라우터의 역경로를 반환하게 한다. 이러한 공격에 대한 구현은 매우 간단하며, 방화벽 구축자는 이러한 일들을 염두에 두어야 한다.
실질적으로 Source Routing 은 거의 사용되지는 않는다. 사실 이것의 적법한 사용은네트워크 문제 디버그를 위한 것이며, 어떤 특수한 상황하에서 네트워크 혼잡성제어를 위한 특정 링크에 대해 사용하게 된다. 방화벽을 구축할 때 Source Routing은 어떤 점에서 막아야 하며, 대부분의 상용라우터는 이것을 막는 방법이 제공된다. 그리고 방화벽을 지원하는 유닉스 플래트홈 버젼에서도 이것을 금지하거나 무시하는방법들이 제공된다.
w) ICMP Rediect 란 무엇이며 Redirect Bomb란?
ICMP Redirect는 라우팅테이블에 존재하는 문제를 수신자에게 반환한다. 이것은 특정한 목적지에 대한 라우트에 생긴 문제점과 적합하지 않은 라우팅을 사용하는호스트에 얘기하는 라우터에 의해 사용된다. 잘못된 라우터는 호스트에게 ICMPRedirect 패킷을 되돌려주며, 정확한 라우팅을 알려주게 된다. 만약 ICMP Re-direct 패킷을 위장하고 상대편 시스템이 이것을 인지한다면 상대편 시스템의 라우팅테이블을 바꾸어 네트워크 관지자가 의도하지 않은 패스를 주어 보안문제를일을킬 수 있다. 이것은 또한 서비스 거부(Denial of Service) 공격에 이용될 수 있는데, 주로 네트워크 접속을 잃어버리게금 하는 식이고, 특정한 네트워크로
가는 패스에대해 더 이상 접근할 수 없다는 식으로 이용될 수 있다.
많은 방화벽 구축자들은 네트워크에 ICMP Redirect 패킷을 스크린할 수 있도록 하고 있으며, 외부자들이 호스트를 ping 할 수 있는 능력을 제한하든가 라우팅테이블을 고칠 수 없도록 한다.
x) 서비스거부(Denial of Service)란 무엇인가?
서비스거부란 어떤이가 네트워크나 방화벽이 정상동작 못하게 파괴하거나 정지시키거나 고장내거나 넘치게 만드는 것이다. 이것의 문제점은 인터넷에 대해 보호기능을마비시킨다는 점이다. 이유는 네트워크의 분산된 성능과 능력에 있는데, 각각의 네트워크 노드들은 각 또다른 네트워크에 상호 연결되어 있는 것이다. 방화벽관리자나 ISP들은 미치는 단순한 근거리의 일부만 제어할 수 있다. 공격자는 언제나 상대가 제어하는 곳을 Upstream 시켜 접속을 파괴할 수 있다. 만약 어떤 네트워크의 동작을 방해하고 싶다면 언제든지 네트워크를 잘라버릴 수 있는 것이며, 이런 유사한 서비스 거부 방법들은 매우 많다. 만약 어떤 기관이 접석 및 서비스 시간이 중요하고 어떤 매우 중요한 업무를 인터넷에서 하고 있다면 네트워크의 정지나 문제점에 대비한 복구 능력을 가지고 있어야 할 것이다.
y) 용어설명
권한남용(Abuse of Privilege): 어떤 사용자가 허용되지 않은 행위를 할 경우
응용레벨방화벽(Application-Level Firewall): 전반적인 TCP 접속 상태와 순서 등을 관리하는 프로세스가 제공되는 방화벽시스템, 외부로 나가는 트래팩이 내부호스트가 아닌 방화벽에서 다시 re-addressing 되어 나타나게 된다.
인증(Authentication): 시스템에 접근하는 사용자의 신원을 확인, 결정하는 프로세스
인증토큰(Authentication Token): 사용자를 인증하는 이동형 장치로서, challenge/response 및 time-based code sequences 등의 기법을 이용하며, 이것은 종이에 적어둔 일회용 패스워드도 포함될 수 있다.
인증허가(Authorization): 어떤 행위가 허용될 수 있는지 결정하는 과정으로서, 보통 이것은 인증의 개념이다. 한번 인증이 되면 그 사용자는 어떤 형태의 접근과 행위를 인증 허가된 것이다.
베스쳔호스트(Bastion Host): 어떠한 공격에도 견딜 수 있도록 만든 시스템으로서 어떤 네트워크에서의 공격을 예측하고 만든다. 이것은 방화벽의 한 구성 요소로서 외부의 웹서버일 수 있는 공개 접근할 수 있는 시스템이다. 일반적으로 이것은 ROM 위주의 Firm 운영체제가 아닌 일반 목적의 운영체제를 가진 시스템이다.
질문/응답(Challenge/Response): 사용자에게 예측하기 어려운 값을 주면 사용자가 토큰을 이용하여 계산한 값을 반환하는 사용자 인증 기술의 하나
제한암호체크썸(Cryptographic Checksum): 나중에 참조하기 위해 만든 유일한 지문으로 만드는 단방향 함수로서 UNIX의 파일시스템의 내용 변경을 막기위한 주요한 수단이 된다.
데이타주도공격(Data Driven Attack): 공격하기 위해 어떤 사용자나 다른 프로그램에 의해 실행되는 불법의 데이타에 의한 공격으로서 방화벽에서는 내부의 네트워크로 침투하기 위한 데이타가 방화벽을 공격할 수 있다.
깊은방어(Defense in Depth): 네트워크의 모든 시스템이 완전히 보호해야한다는 보안 접근 방식의 하나로서 방화벽에 도입되어 사용될 수 있다.
DNS위장(DNS spoofing): 다른 시스템의 DNS 이름을 가장하여 상대시스템의 네임 서비스 캐쉬를 훼손하거나 정당한 도메인의 서버를 공격하는 것
이중네트워크게이트웨이(Dual Homed Gateway): 2개 이상의 네트워크 인터페이스를 가져 2개의 네트워크를 상호 연동하는 게이트웨이로서, 방화벽 구성시 네트워크를 패스하는 트래픽에 대해 막거나 필터링하는 역할을 한다.
암호라우터(Encrypting Router): 라우터 터널과 가상네트워크 경계를 보라
방화벽(Firewall): 2개 이상의 네트워크 경계를 해주는 시스템이나 어떤 집합
호스트기반의보안(Host-based Security): 각각의 호스트에 대한 공격에 대비하는 보안기술로서 운영체제나 관련 버젼에 따라 달라지게 된다.
내부공격(Insider Attack): 보호된 네트워크 내부에서의 공격
침입탐지(Intrusion Detection): 네트워크에서 알 수 있는 정보나 로그에 기반을 둔 전문가시스템 혹은 사람이 침입이나 침입시도를 탐지하는 것
IP 위장(IP Spoofing): 다른 시스템의 정당란 어드레스를 위장한 공격
IP 끊기, 납치(IP Splicing / Hijacking): 현재 접속되어 있는 세션을 뺏는 공격 으로서 이미 사용자가 인증된 세션을 가로챈다. 이것에 대한 주된 대응은 세션이나 네트워크 계층에서의 암화를 지원하는 것이다.
최소권한(Least Privilege): 시스템이 최소한의 권한으로 동작하도록 만드는 것으로 이것은 어떤 행위가 실행될 때 이의 인증허가가 최소화할 수 있으며, 사용자나 어떤 프로세스가 보안에 위배되는 행위를 할지도 모르는 비인가된 행위를 일으킬 여지를 줄인다.
기록(Logging): 방화벽이나 네트워크에서 일어나는 사건들의 기록
기록유지(Log Retention): 어떻게 오랫동안 기록을 유지하고 추적감사할 수 있는가
기록프로세스(Log Processing): 어떻게 기록이 처리되고, 주요 사건을 찾아 요약 할 수 있는가라는 감사추적성
네트워크레벨방화벽(Network-Level Firewall): 네트워크 프로토콜 레벨에서의 트래픽을 검사되는 방화벽
경계기반의 보안(Perimeter-based Security):네트워크의 모든 입구/출구에서의 접근을 제어하여 네트워크를 보호하는 기술
정책(Policy): 전산자원의 허용된 사용 수준, 보안기술, 운영절차 등에 대한 기관차원의 규칙
프락시(Proxy): 사용자를 대신하는 소프트웨어 에이젼트로서 대표적인 프락시는 어떤 사용자의 접속을 받아 이것이 허용된 호스트나 사용자인지 점검하고 어떤 추가적인 인증 기능을 할 수도 있는데, 원격지 목적지로 사용자의 대신한 접속을 만든다.
스크린호스트(Screened Host): 스크린라우터 다음의 호스트로서 스크린호스트에 접근될 수 있는 정도는 라우터에 정의된 스크린규칙에 따라 달라진다.
스크린서브네트(Screened Subnet): 스크린라우터 다음의 하나의 서브네트로서 서브네트에 접근될 수 있는 정도는 라우터의 스크린규칙에 따라 다르다.
스크린라우터(Screening Router):관리자가 설치시 정의한 일련의 규칙에 근거한 트래픽을 허용하거나 거부할 수 있는 라우터
세션훔치기(Session Stealing): IP Spoofing 을 보라
트로이목마(Trojan Horse): 트랩도어나 공격 기능을 가지고 동작하는 일반적인 프로그램 엔티티
터널라우터(Tunneling Router): 트래픽을 신뢰할수 없는 네트워크를 통해 보낼 때 암호화 후 인캡슐레이션하여 보내고 수신쪽에서는 다시 복호화를 하도록 기능이 지원되는 라우터
사회공학(Social Engineering): 상대편 시스템의 관리자나 사용자를 속이는 공격으로 대부분 전화 등을 통해 정당한 사용자처럼 위장하여 권한을 얻는 경우를 말한다.
가상네트워크경계(Virtual Network Perimeter): 신뢰할 수 없는 네트워크 사이에 암호화된 가상 링크로 연결된 방화벽들 너머 하나의 보호된 네트워크처럼 보이게 하는 네트워크
바이러스(Virus): 자기 복제 능력이 있는 코드세그먼트로서 바이러스는 공격 프로그램이나 트랩도어를 가질 수도 있고, 없을 수도 있다.
z) 공헌자들
* Primary Author: mjr@iwi.com - Marcus Ranum, Information Warehouse!
* Cisco Config: allen@msen.com - Allen Leibowitz
* DNS Hints: brent@greatcircle.com - Brent Chapman, Great Circle Associates
* Policy Brief: bdboyle@erenj.com - Brian Boyle, Exxon Research
Copyright(C) 1995 Marcus J. Ranum. All rights reserved. This document may be
used, reprinted, and redistributed as is providing this copyright notice and
all attributions remain intact.
블로그 > 20Th BOY!!
http://blog.naver.com/yayaluna/1515669
2004-03-25
조병욱
EJB 는 J2EE의 기술의 하나로, 분명히 편리하고 강력한 첨단 기술임에는 틀림이 없다. 그렇지만, EJB의 특징과 장단점을 제대로 인식하고 EJB 사용하는 개발자는 많지 않다고 느껴진다.
특히나 대부분의 EJB로 이루어지는 부분에 대해서는 EJB가 아니라 일반 Java Beans로도 구현이 가능하다. 그렇다면 언제 EJB를 사용해야 되는것인지에 대해서 알아보도록 하자.
일반 Servlet/JSP는 Presentation 즉 데이타를 화면에 나타내기위한 부분을 위해서 디자인 된 부분이다. 종종 웹개발자들이 개발을 하면서 Business Logic이나 SQL문장까지 Servlet/JSP에 들어가는 일이 있는데, 이렇게 되면 Presentaion과 Logic의 분리가 불가능하다. 즉 둘중 하나만 바뀌더라도 코드를 수정해야된다.
EJB를 사용하지 않더라도
Servlet/JSP (Presentation) -> Java Beans (Business Logic) -> DBMS
이런 방식으로 구현하는게 좀더 모범답안이다.
대부분의 Web Application은 이런 방식으로 개발이 가능하다.
그 외에도 간단한 WebService의 개발이나, 또는 3 Tier가 아닌 위에서 제시한 2 Tier 모델인 경우에도 굳이 EJB를 사용할 필요가 없다.
EJB 선택에 있어서 잘못된 상식
그렇다면 EJB는 언제 사용하는가?
개발자들과 EJB에 대해서 이야기 해보면 몇가지 잘못된 상식이 있다. 하나하나 집어 보도록 하자.
EJB server는 비싸다?
EJB 도입에 있어서 망설이는 부분중 하나가 WAS의 가격문제이다. WAS 자체의 가격만으로만 보면 절대 싼 가격은 아니다. 그러나 프로젝트 전체를 봤을때는 반대로 비싼 가격이 아니다. 프로젝트 전체란 단순히 개발 비용만을 말하는것이 아니라 유지 보수 비용을 포함한다. 더군다나, J2EE Framework (EJB, Load Balancing,Failover,Transaction 처리 등)을 직접 구현하지 않고 이미 표준화되고 안정화된 환경을 사용하는것에 대하면 오히려 개발비용을 효과적으로 줄일 수 있는 방안이기도 하다.
단, 국내 개발자들이 WAS선택에 있어서 고려해야할점은 합리적인 선택이 필요하다는 것이다. 같은 WAS라도 지원하는 Feature에 따라서 가격이 틀리기 때문에 구현하고 사용하고자 하는 Feature를 갖추고 있는 WAS Version을 구입할 필요가 있다.
그리고 구입전에는 용량 산정작업 (Capacity Planing)이 필요하다. 주먹구구식으로 HW성능과 WAS의 개수를 선택하다보면 쓸데없이 비용만 낭비하기 마련이다. 용량 산정에 대한 사전 작업과 컨설팅에 비용을 투자한다면 그로 인해서 쓸데 없이 사양만 높은 HW와 많은 수의 WAS를 사는 일을 줄여서 프로젝트 비용을 많이 조정할 수 있을 것이다. ( 실제로도 4CPU만으로도 충분한 프로젝트를 12CPU이상으로 진행하는 경우도 많이 봤다. 국내에서는 컨설팅 문화가 정착되지 않은 이유도 있겠지만, 효과적인 컨설팅은 프로젝트의 위험요소 제거와 정확한 진행에 많은 도움을 준다. 물론 컨설팅 회사가 그만한 노하우를 가져야 함은 두말할나위 없는 사항이다.)
그외에 방안으로는 공개 WAS를 사용하는 방법도 있다. 대신 중요한 업무를 다루는 프로젝트의 경우 공개 WAS는 기술지원의 한계와 가이드의 부제등 때문에 절대 추천하고 싶지 않다.
EJB로 나누면 Component 모델이나 각 Tier를 구분하기가 훨씬 편리하다?
물론 EJB를 사용하면 Business Logic이나 Data Model을 분리하기도 좋고, Component 화 하기도 좋다. 그러나 이런 이유만으로 EJB를 선택하는것은 합당하지 못하다. EJB를 사용하지 않더라도 Java Beans 만으로도 충분히 Component Model이나 Tier 구분이 가능하다.
그럼 EJB 는 언제 사용해야 하는가?
EJB를 언제 사용하느냐는 것은 EJB의 장점과도 연관이 된다.
좀더 빠르고 안정적인 시스템을 위하여…
EJB는 instance pooling,transaction 처리, 보안,CMP,CMR 그리고 데이타 캐슁과 클러스터링을 통한 Load Balancing과 Fail over 기능들을 이미 다 구현해놓은 frame-work이다. 간단하게 Session Bean을 통해서 SQL문을 하나 처리한다 하더라도 그 안에는 이런 기능이 이미 구현되어 있고, 이런 기능들은 이미 vendor들에 의해서 최적화 되고 안정성이 검증된 기술들이다.
이런 기능들을 일일이 구현하기 위해서는 framework등을 만들어야 하는데, 여기에 소요되는 시간과 기술 그리고 시행 착오에 드는 비용이 매우 크다. 프로젝트 하나를 위해서 Clustering 기능을 직접 구현한다고 생각해보자… 필자로서는 상상이 안가는 일이다.
담당자가 바뀌었을때도 안정적인 운영이 가능하다.
Framework을 만들어서 운영을 했다고 하자, 그후에 운영 담당 기술자가 바뀌면 그 Framework을 설명과 별도의 교육 작업이 필요하다. 그렇지만 J2EE 기술은 표준 기술이기 때문에 J2EE 기술을 가지고 있는 기술자를 뽑는다면 Framework 자체에 대한 기술 교육은 필요없이 바로 시스템을 인수 받을 수 있게 된다.
표준기술이기 때문에 많은 자료들을 구할 수 있다.
또한 잘 알다 싶이 J2EE는 이미 표준화되고 많은 검증된 솔루션(J2EE Pattern)과 Article들이 많기 때문에 EJB 솔루션을 사용하기 위한 도움을 받기가 용이하다.
RAD Tool을 통해서 개발 생산성을 극대화할 수 있다.
이미 EJB는 표준화된 기술이기 때문에 각종 RAD에서 EJB를 만들기 위한 Process를 자동화해서 지원하고 있다. 그래서 빠르게 EJB를 이용하여 프로그램을 제작할 수 있고 , RAD 이외에도 ant와 같은 command line tools를 이용해서도 개발에 도움을 받을 수 있다.
Tier 구분이 매우 편리하다.
Tier 구분은 위에서 말한 단순한 Servlet/JSP->Java Bean 이런 Tier 구분이 아니라, EJB는 Remote Call로 Invoke가 가능하기 때문에 Presentation (Servlet/JSP)와 Business Logic(EJB)을 물리적으로 완전히 분리하는것도 가능하다. 또한 Servlet/JSP가 아니라 Applet, RMI/IIOP를 이용하여 일반 Client까지 연동이 가능하기 때문에, Presentation Layer에 대해서 독립성을 가지는 Tier 모델을 작성할 수 있다.
그렇다면 EJB를 사용하는게 언제나 좋은가?
결론부터 이야기 하자면, 대답은 NO이다.
특히 가장 하고 싶은말중 하나는 EJB의 특징을 제대로 알고 필요한 요소에 제대로 사용하자는 것이다. ( 예를 들어 EJB의 Transaction 모델을 쓰면서 dbconn.commit()을 한다던지와 같은 일을 하는건 없어져야한다는 말이다. )
물론 EJB 기술이 쉬운 기술은 아니다.그러나 한국 IT 특성상 신기술을 따라가는 경향이 심한것 같다. EJB의 특징이나 문제점을 제대로 파악하지 않는 상태에서 EJB를 사용하는것은 오히려 득보다는 실이 많다.
RMI나 Beans 기술에 익숙하다면 이미 익숙한 기술을 사용하기 바란다. 프로젝트는 공부를 하기 위해서가 아니라, 이미 알고 있는 기술을 안정적으로 구현하는 것이 되어야 한다.
그외에도 JNI를 사용하는 구조나 Multithread 모델을 사용하는 구조, static 변수를 사용하는 구조를 EJB로 구현하는것은 해서는 안될일이다.
그리고 simple한 application을 굳이 EJB를 써서 구현할 필요는 없다. (EJB는 Deployment Descriptor도 만들어야하고, 생각보다 할일이 많다.)
결론적으로 EJB는 매우 유용한 Architecture이고 개발자가 해야할 많은 부분을 자동으로 처리해주는 안정화되고 최적화된 개발 framework이다. 그러나 EJB를 사용하기 위해서는 그에 알맞은 적절한 지식이 필요하며, 적재적소에 사용하지 않는 다면 득보다 실이 많을 수 있는 기술임을 인식하는것이 중요하다.
참고 자료 http://www.theserverside.com/articles/article.tss?l=Is-EJB-Appropriate
블로그 > Don't Worry~ Be Happy!! http://blog.naver.com/swucs/40003014614
EJB는 왜 필요할까요?
EJB는 "대규모이고 구조가 복잡한 분산 객체 환경"을 쉽게 구현하기 위해서 등장했습니다.
이것이 과거, 현재, 미래를 통틀어 EJB의 제 1 목표이고, 존재의 의미입니다.
따라서, EJB를 사용할 것인지 말 것인지에 앞서, 개발자들은 전체 아키텍쳐를 분산 객체 환경으로 가져갈 것인가 말 것인가를 고려해야 합니다. 만일, 분산 객체 환경이 필요 없다면, EJB를 써야 할 필요성의 70퍼센트는 감소됩니다.
그렇다면, 분산 환경은 왜 필요한걸까요?
분산 환경은 비즈니스 로직과 UI로직을 서로 다른 머신(또는 프로세스)로 분리시킴으로써 비즈니스 로직의 재사용성과 시스템 아키텍쳐의 유연성을 높이기 위해서 등장했습니다.
이 두 조건은 시스템이 커지고 복잡해질 수록 중요합니다. 그래서 대규모 시스템엔 분산 객체 아키텍쳐가 추천되는 것이고, 분산 객체 환경의 구축을 쉽게 하려다 보니 EJB와 같은 전용 플랫폼이
필요한 것입니다.
자, 그렇다면, EJB의 각 요소들과 기능들이 나오게 된 연유에 대해 좀 더 자세히 알아봅시다.
분산 환경을 쉽게 구현하게 하려다보니, RMI 가 필요합니다. 재사용성을 높이려다 보니 컴포넌트 형태가 적합합니다. 데이트 소스가 어떤 형태이든 간에 비즈니스 로직의 소스가 바뀌지 않게 하기 위해서는 비즈니스 로직 컴포넌트와 데이터베이스 접근 컴포넌트를 따로 나눌 필요가 있었습니다. 그래서 세션 빈이라는 것과 엔터티 빈이라는 것을 만들었습니다.
이들이 데이터베이스에 접근하는 컴포넌트이고, 만들기 쉽게, 재사용하기 쉽게 만들어야 하다보니
자연히 트랜잭션을 최대한 자동화할 필요가 생겼습니다. 그래서 트랜잭션 속성이란 걸 지정해서 트랜잭션을 관리하게 만들었습니다. 컴포넌트가 컴포넌트를 호출하다 보니, 컴포넌트 간에 트랜잭션을 전달하게 할 필요도 있습니다. 그래서, 그런 기능도 넣었습니다. 컴포넌트의 다양한 상태에 따라 사용자가 적절한 조치를 취할 수 있도록 콜백 메소드들도 넣었습니다. 자, 수정사항이 발생할 때마다 컴포넌트를 고치게 하는 것은 용이성, 재사용성의 규칙에 위배되므로, 굳이 로직으로 넣을 필요가 없는 것(비즈니스 로직이 아닌 것)은 설정파일에 담아, 소스 수정이 없이 설정만 하면 적용되도록 만들 필요가 있습니다. 그래서 배치 디스크립터란 설정 파일을 만들고, 그런 것들을 끌어
모아 몽땅 집어넣었습니다....etc....어라? UI 와 비즈니스 로직 컴포넌트 간에 네트웍을 통한 RMI 통신이 들어가고, 게다가 여러 개의 객체가 모여 하나의 컴포넌트를 이루며, 자동화를 위해 개발자 모르게 여러 로직을 실행시키게 하다 보니 이거 원 속도가 장난이 아니게 느리고, 자원을 지나치다 싶을 만큼 잡아먹습니다.
이렇게 무겁고 느린 걸 누가 삽니까. 자, 어떻게든 최대한 자원을 관리할 필요가 있습니다.
세션 빈을 상태유지 세션 빈과 무상태 세션 빈으로 나누고, 무상태 세션 빈 인스턴스는 풀링을 시켰습니다. 같은 맥락으로, 데이터 베이스 커넥션 풀링시키는 건 테크닉이라고 하기도 뭐할 만큼 일반적이며 필수적이므로 이 또한 포함시켰습니다.
자, 그럼 결론.
1. "속도를 위해 EJB를 사용한다?"
=> EJB의 여러 기능들은 "속도" 를 위해서 나온 것이 아니라, "분산 객체 환경" 에서 "개발유지보수의 편의성" 과 "시스템의 유연성"을 높이기 위해 고안되었습니다. "속도" 와 "개발유지보수편의성/시스템유연성"은 서로 반비례 그래프를 그리는 인자들입니다. "속도" 와 "편의성/유연성" 이 대치되어 이들 중 하나를 선택할 필요가 있을 때, EJB의 스펙이나 컨테이너 설계자들은 "편의성/유연성"을 택할것입니다.
따라서, 누군가가 "기능 구현을 위해 꼭 필요한 것은 아니지만, 속도를 높이기 위해 EJB를 끼워넣겠다" 라고 한다면 그는 EJB의 개발 의도를 잘못 이해한것이고, 따라서 심각한 오해를 하고 있다는 것을 말해두고 싶습니다.
2. "안정성을 위해 EJB를 사용한다?"
EJB는 이론적으로 안정성이 높습니다. 왜 그럴까요?
첫째 이유는, EJB가 좋은 프레임웍이기 때문입니다.
비즈니스 로직과 UI가 완전히 분리되어있으므로, 개발자들은 비즈니스 로직 담당자와 UI담당자로 나뉘게 됩니다. 각 개발자들의 관심의 범위가 1/2로 좁아지게 되는 만큼 이들은 각각의 영역에 대해 심리적, 지식적으로 2배만큼 전문화됩니다.
전문가들이 만든 코드는 일관성과 안정성을 갖게 되죠. 또한, 잦은 로직 수정 요구가 있더라도 보다 적은 부분을 수정함으로써, 짧은 시간에, 안정적으로 요구를 반영할 수 있습니다.
또한, EJB는 프로그래밍 상의 제한점을 많이 두었기 때문에(예를 들어 하나의 컴포넌트 인스턴스를 동시에 두 명의 사용자가 사용하지 못한다든지 하는...) 개발자의 실수를 미연에 방지하는 역할도 합니다. (안정성을 저해하는 가장 큰 요인은 설계/개발자의 무지와 OS 및 엔진 역할을 하는 소프트웨어의 버그 때문이라는 거 아시죠?)
둘째, EJB는 3계층의 미들티어에 위치하면서, 한정된 공유자원들 (예를 들어, 데이터 베이스 커넥션)을 효과적으로 관리해줍니다. 이것은 사용자가 많을 경우의 안정성에 지대한 영향을 미치는 요인입니다.
그러나, EJB를 끼워넣어야만 이것이 가능한 것은 아닙니다. 웹서버(WAS포함)와 데이터베이스만으로 이루어지는 구조에서, WAS 즉, 서블릿/JSP 엔진은 데이터베이스 커넥션 풀링이라든지 스레드 풀링등을 통해 나름대로 공유자원을 최대한 활용하는 메커니즘을 제공해 줍니다.
세째, 기본적으로 EJB가 들어가면, 머신은 WebServer단 + EJB 단 + DB 단으로 보통 3계층화 됩니다.
WebServer 단 + DB 단으로 이루어지는 2계층에 비해 머신이 1대 더 많죠. 즉, 한 대의 머신이 UI 와 비즈니스 로직을 모두 처리하는 대신, 두 대의 머신이 비즈니스 로직과 UI를 나눠서 처리하므로 2계층 환경에 비해 더 많은 사용자를 수용할 수 있습니다.
어라? 그럼, EJB서버로 쓸 예정이던 머신을 WebServer 머신으로 쓰고, 2개의 WebServer 머신을 클러스터링 시키면 어떨까?
네, 좋습니다. RMI 와 컴포넌트를 사용하지 않으므로, 같은 수의 사용자에 대해서 이 구조는 자원을 보다 덜 소모합니다. 이는 바꿔 말하면, 같은 양의 자원으로 보다 많은 사용자를 수용할 수 있다는 뜻입니다.
또한, WebServer + EJB 서버 각각 한 대로 된 구조는 클러스터링이 되어있지 않습니다.
클러스터링을 시키려면 각 티어마다 머신을 한 대씩 더 두어서 총 4대의 머신을 마련해야 하죠.
그러나, EJB를 안쓰면 웹서버 단이 두 대가 되므로 이들은 자연스레 클러스터링을 구성할 수 있습니다. 즉, 동일한 물리적 환경에서 이 구조는 페일오버가 된다는 얘기죠. 이렇게 보면, EJB를 쓰지 않은 구조는 오히려 훨씬 안정적인 아키텍쳐가 됩니다.
결론적으로, 분산 객체 환경이 필요하지 않다면, EJB를 쓰는 구조가 쓰지 않는 구조에 비해 갖는 이점은 "좋은 프레임웍을 제공" 한다는 것 뿐입니다.
WebServer 티어 (아...물론, 이 글에서 WebServer 티어라 하는 것은 , JSP 와 서블릿을 포함하여 말합니다.
정확히 말하면, WebServer + WAS를 말한다는 거죠.) 에 모든 것을 두는 것이 안정성이 더욱 높습니다.
3. 더하여, "EJB는 배우기 쉽고, 사용하기 쉽다" 라는 말씀들을 많이 하시는데...그건, CORBA라든지 하는 다른 분산객체용 엔진에 비해 그렇다는 것입니다.
EJB를 능숙하게 사용하려면 적잖은 시간이 걸립니다. 한 일주일 교육받는 걸로 충분한 문제가 아니라는 거죠. 그렇다고, EJB에 대해 철저히 알지 못하고 사용하시는 것은 오히려 사용하지 않는 것만 못합니다.
이는 오히려 개발자의 무지로 인해 시스템의 안정성과 유지/보수의 용이성을 해치게 되죠. 그리고, 나중에 튜닝한다고 시간을 더 뺏기게 될 수도 있습니다. 필요한 만큼 머신을 구입할 수 있는 상황이 안되는 그런 경우에, 성능이 기대만큼 안 나오면 어쩔 수 없이 튜닝작업 들어가야 하지 않겠습니까? 아다시피, 어플리케이션의 정확한 속도는 테스트를 해봐야 아는 거고 보다 정확한 테스트는 개발이 어느 정도 완료된 후에야 할 수 있는 거죠. 그러다보니, 튜닝할 시간은 짧고, 그래서 꼼수에 꼼수를
더해가는 하는 거죠. 이거...쥐약이죠. 잘 만들어 놓은 어플리케이션을 끝에 가서 완전히 꼬아놓을 수도 있습니다. 흔히 말하는 "스파게티 소스" 가 되는거죠. 스파게티 소스에서 안정성을 기대할 수 있겠습니까? 절대 아니죠.
결론적으로, 님의 환경이 어떻든간에 즉, 트랜잭션이 얼마나 많고, 레코드가 얼마나 많건간에 "분산 객체 아키텍쳐"가 필요치 않고, 좋은 프레임웍을 갖고 계시다면, EJB는 넣지 않으시는 것이 좋습니다. 그렇지 않다면, 즉, "분산 객체 아키텍쳐"가 필요하다거나, 좋은 프레임웍이 없다거나, 능숙한 설계/개발자가 없다거나 하실 경우는 EJB가 적극 추천됩니다.
물론, 어플리케이션 개발 후, 성능 테스트의 결과에 따라, 머신은 WebServer 만 사용할 때보다 1.5 내지 2 배정도 증설하실 여력이 있다면 말입니다.
블로그 > 숨쉬는 일보다 니가 더 익숙했던 난 http://blog.naver.com/celestialorb/40004374985 